
1. 서론
열화된 영상을 원래 형태로 복원하는 것을목표로 하는 영상복원 문제는 컴퓨터 비전과 영상 처 리 분야에서 가장 근본적 인 문제중 하나이다. 열화된 영상y는 일반적으로 y = f (x) + n 으로 모델링 되 어 지 며,여 기 서 x 는 원본 영 상,f 는 영 상 열화 방법,n은 표준편 차 여를 갖는 가산성 백 색 가우시 안 잡음 (Additive White Gaussian Noise)으로 가정된다. 영상 복원의 목표는 y 로부터 x 를추정하는 것이다. f의 정의에 따라 영상 복원은 다른 하위 문제들로 분류될 수 있다. 예를 들어,f (x) = x인 경우는 잡음 제거,f (x)가 블러 커널인 경우에는 블러 제거,f (x)가 Joint Photographic Experts Group (JPEG) 압축인 경우에는 JPEG 영상 복원 문제가 된다.
영상 복원의 중요성 때문에 간단한 필터 링 방법부터 정교한 학 습 기반의 방법에 이르기까지 수 십년 동안 다양한 해결 방법들이 제안되어 왔다. 기존의 이미지 복원 방법은 필터링 기반 접근법 [1], 총 변량 (Total Variation) 기반의 방법 [2, 3],자기 유사성 기 반 방법 [4, 5, 6], 그리고 딤러닝 이전의 학습 기반 방법 [7, 8] 이 제안되었다. 딤 러닝의 발전으로 많은 영상 복원 문제 [9, 10] 에 적용되었다. 딤러닝 기반의 방법들은 대규모 학습 데이터셋을 사용하여 열화된 영상으로부터 해당 복원된 영상으로 매핑하는 방법을 학습한다. 딤러닝의 능력 덕분에 고전적인 영상 복원 방 법보다 훨씬 뛰어난 결과를 보여준다.
딤 러닝을 사용하면서 기존의 방법들에 비해 높은 성능을 내지 만, 대부분 딤러닝 기반의 영상 복원 방법들은 각 잡음 정도나 JPEG 압축 정도, 블러 정도에 따라 각각 학습을 해줘야 한다. 즉, 위에서 언급한 딤 러닝 기반의 영상 복원 방법들은 한 가지 열화 방법에 특화되 어 있다. 그렇기 때문에 열화된 영상을 복원시 키 려 면 열화된 방법을 인지하여 그에 맞는 모델을 이용하여 복원을 해야한다. 하지만 자율주행 자동차나 로봇 시스템과 같은 영상 열화 방법을 인지할 수 없는 상황에는 영상 복원 방법을 적용하 는데 무리가 있다. 또한 실제 환경 에서는 잡음, 블러 등과 같은 다양한 열화들 이 발생하기 쉽 다. 즉, 이 런 상황에서는 한 가지 열 화에 특화된 복원 방법을 적용할 수 없기에, 다양한 열화에 대처 가 가능한 영상 복원 방법 이 필요하다.
복합 열화 복원을 위한 연구는 거의 진행되지 않았다. Yu et al.11는 강화학습을 사용하여, 네트워크 내에서 영상 열화를 인지하여 그에 맞는 열화 복원 네트워크를 사용하여 복합 열화 를 복원하는 방법인 RL-Restore를 제안했다. 하지만 이 방법을 사용하기 위해서는 각 열화 정도 별로 복원 네트워크를 학습 시 켜줘야하고, 학습된 열화별 복원 네트워크를 가지고 영상에 적 용된 열화를 인지하기 위한 LSTM도 따로 학습을 시켜줘야한다. 이는 네트워크를 학습시키기 위해 많은 시간이 필요하고, 복합 영상 복원 성능 또한 좋지는 못하다. Suganuma et al.[12]는 복 합 열화 복원을 위 해 operation attention과 group attention을 적용 하여 Operation-wise Attention Network (OWAN)을 제 안했다. 한 레이어에서 총 8가지의 operation을 사용하여 특징 맵을 얻은 뒤, 열화된 영상으로부터 각 operation간의 어텐션 정보를 얻어 곱해 주게 된다. 어텐션 정보가 곱해진 8개의 특징맵을 concatenation 을 시 켜 1개의 특징맵으로 합친 뒤, 1 × 1 합성곱을 사용하여 원 래 채널수와 맞춰준다. 다양한 operation을 사용하여 얻은 많은 정보중에서 필요한 정보만 가지고 영상 복원을 진행하여 효율적 으로 보인다. 하지만 이 네트워크는 한 층에서 여 러가지 operation 을 사용하기 때문에 많은 파라미터로 구성되어 있고, 논문의 분 석 내용을 보면 거 의 사용되지 않는 operation도 존재한다. 이는 비효율적 이고, 학습 및 테스트를 진행할때에도 많은 시간을 소모 하게 된다.
본 논문에서 우리는 영상 열화 방법을 인지할 수 없는 상황에 서 적용할 수 있는 복합 열화 복원 네트워크를 제안한다. 우리는 네트워크에 채널간 어텐션 모듈과 스킵 커넥션을 적용하여, 영 상에 적용된 열화에 따라 복원에 필요한 채널에 높은 가중치를 적용하여 효율적 인 영상 복원이 가능하도록 하였다. 본 논문에서 제안하는 네트워크는 기존에 제안되었던 최신 (state-of-the-art) 방법들 보다 높은 성능을 내고, 단 한번의 학습으로 복합 열화 복원이 가능하도록 하였다.
이 연구의 기 여는 다음과 같다.
2. 관련 연구
이번 절에서는 다양한 열화에 대한 영상 복원 및 채널 어텐션의 기존 연구에 대해 설명한다. 영상 복원은 영상 처리 분야에서 가 장 근본적 인 문제 중 하나이기 때문에 방대한 양의 연구 결과가 있다. 여기서 우리는 각 열화별로 대표적인 작품들 중 일부만을 다루고 있다.
주변 픽셀이 복원할 픽셀과 비슷한 픽셀을 가지고 있다고 가정 하여 가우시안 필터링이나 바이레터럴 필터링과 같은 필터링 기반의 방법들 [1]이 제안되었다. Freeman et al.[7]은 초해상 도 복원을 위해 외부 데이터베이스를 활용하여 선명한 영상과 열화된 영상사이의 관계를 학습하는 방법을 제안했다. Elad와 Aharon [8]은 잡음 제거를 위해 사전을 학습하는 방법을 제안하 였다. Buades et al.[4]는 영상내의 비국부적 자기유사성을 이용 한 영상 복원 방법을 처음으로 제안했다. Dabov et al.[5]는 3D DCT 변환과블락 매칭을 결합하여 BM3D라는 영상잡음 제거 방 법을 제안했다. BM3D는 매우 효과적 인 잡음 제거 방법으로, 여 전히 영상 잡음제거에서는 비교 방법 중 하나로 사용된다. Glasner et al.[13]는 단일 이미지 내에서 블록 레벨 통계를 활용함으 로써 단일 영상을 외부 데이터베이스나사전의 필요 없이 초해상 도 복원을 할 수 있음을 보여준다. Cho et al.[14]는 위 해 기 댓값 최대화 알고리즘을 사용하여 outlier들을 조절하는 방법을 제안 하여 영상의 블러제거에서 뛰어난 결과를 보여준다.
최근 몇 년간 영상 복원 문제에 대 해 딤 러닝 이 활발히 적용되 었 고, 고전적 인 방법에 비해 우수한 결과를 보여주고 있다. Dong et al.[15]는 처음으로 딤러닝 기반의 초해상도 복원 방법인 SR-CNN을 제안했다. SRCNN은 단순히 3개의 합성곱 층으로 구성 되어 있지만, 고전적인 복원 방법들보다 우수한 결과를 보여준 다. Kim et al.[16]은 단일 이미지 초해상도 복원을 위한 매우 깊은 네트워크와 잔여 학습(residual learning)을 제안했다. Xu et al.[17]는 딥러닝 기반의 deconvolution CNN을 제안하여, 블러 제거 문제에서 딤러닝이 적용되지 않은 방법들에 비해 좋은 결 과를 보여준다. Zhang et al.[9]은 잡음제거를 위해 잔여학습과 배치 정규화 (batch normalization)를 사용하여 DnCNN을 제 안했 다. DnCNN은 잡음제거 뿐만 아니 라, JPEG 영상 복원 문제 및 초해상도 복원 문제에서도 좋은 성능을 보였다. Tai et al.[18]는 많은 재귀 유닛과 게이트 유닛으로 구성된 80개의 합성곱 층을 가진 메모리 네트워크를 제안하여 잡음 제거, 초해상도 복원 및 JPEG 영상 복원에 적용했다. Liu et al.[19]는 영상 복원을 위해 반복되 는 비 국부적 모듈로 구성 된 Non-local recurrent network를 제안했다.
위에서 언급한 대부분 방법들은 열화종류를 인지해야만 적용 가능하다. 영상의 열화 종류를 알 수 없는 경우에, 영상내 열화 를 제거하기 위한 소수의 방법들도 제안되었다. Yu et al.[11]는 강화학습을 사용하여 복합 열화에 대 처 가능한 RL-Restore를 제 안했다. Suganuma et al.[12]는 다양한 operation간의 어텐션을 이용하여 영상내의 복합 열화를 제거하는 모델인 OWAN을 제안 했다.
Hu et al.[20]가 처음으로 채널 어 텐션을 제안함으로써 몇몇 연 구에 채널 어텐션을 도입하였다. Hu et al.이 제안한 채널 어텐 션 모듈을 적용한 네트워크는 2017 ILSVRC 영상 분류 (image classification) 분야에서 우승했다. Park et al.[21]은 bottleneck 구간에서 정보량이 줄기 전에 채널 어텐션 모듈을 추가하여, 적 은 파라미 터 수의 증가로 영상 분류에서 높은 성능 향상을 이끌 어 냈다. Woo et al.[22]은 채널 어텐션과 공간 어 텐션 (spatial atten仕on)을 결합한 CBAM (convolu仕onal block attention module) 을 제안하여 영상 분류 및 검출 (image detection)과 같은 여러 영 상인식 문제에서 높은성능을 이끌어냈다. 위에서 언급한 것처럼 고레벨 비전문제뿐 만 아니라, 영상복원에서도 채널 어텐션 모듈 이 적용되 었다. Zhang et al.[23] 과 Cheng et al.[24]은 초해상도 복원을 위해 채널 어텐션을사용하여 다른 딤러닝 기반의 초해상 도 복원 방법들에 비해 우수한 결과를 보여준다.
3. 방법
이번 절에서는 우리가 제안한 복합 열화복원을 위한 네트워크를 소개한다. 3.1 절에서는 여기서 사용한 채널 어텐션 모듈을 소개 하고, 3.2절에서는 본 논문에서 제안하는 네트워크 구조, 3.3절에 서 는 네 트워 크의 학습방법 을 소개한다.
채널 어 텐션 모듈은 Hu et al.[20]가 처음으로 squeeze-and-excitation block이란 이름으로 제안하였다. 일반적인 합성곱 연 산은국부적정보만이용하지만, 채널어텐션모듈은global average pooling (GAP)를 적용하여 비국부적인 정보까지 이용할 수 있게 한다. Fig. 1는 채널 어텐션 모듈을 보여준다.
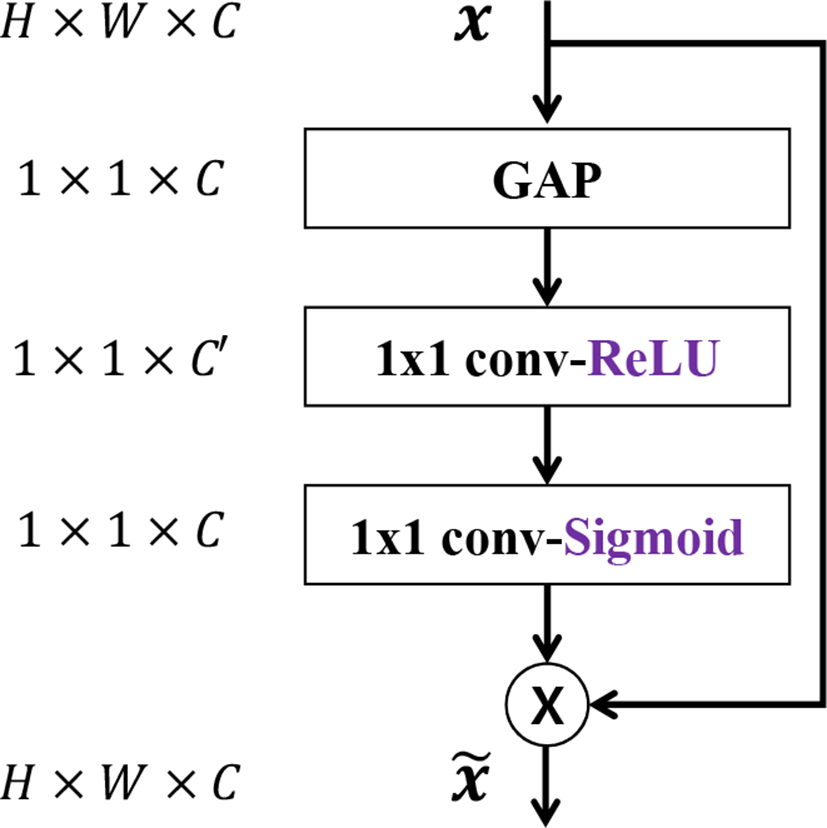
Fig. 1에서 보는거와 같이, 먼저 GAP를 이용하여 채널별 입 력 특징맵의 각 채널인 xc에 대해 압축된 전체 공간 정보 (global spatial information) zc를 얻을 수 있다.
위의 식으로부터 얻은 정보를 두 개의 1 × 1 합성곱 층과 두 개 의 비선형 활성화 함수인 ReLU와 Sigmoid를 통해 채널 사이의 의존성을 계산하는 데 사용한다.
여기서 σ 및 죠는 각 Sigmoid와ReLU 비선형 활성 함수를 나타내 며, W1 ∈ RC×C/r 및 W2 ∈ RC×C/r는 1 X 1 합성곱 층의 가중 치들을 의미한다. W1의 필터 개수를 C′/r만큼 줄이고 W2의 필터 개수를 다시 C만큼 증가시킨다. Fig. 1의 C′은 C/r을 의미한다. 감소비 r를사용하여, C개의 필터를 갖는 1 × 1 합성곱 층 하나만 사용하는 것보다 파라미 터를 적게 사용할 수 있다. 그뿐만 아니 라 [20]에서는 r이 16일 때 r이 1 일 때와 성능 차이가 거의 없으며, 파라미터의 개수를 줄일 수 있음을 입증하였다. 우리도 마찬가 지로 제안한 방법 에서 r을 16으로 사용한다. 아래의 방정식으로 구한 스케일링 팩터 s를 각 채널의 입 력 특징맵에 곱해주게 된다.
여기서 x̂c는 재조정된 특징맵의 C번째 채널이다.
우리는 입력 영상의 비국부적 정보를 이용하기 위해 모델에 서 채널 어텐션 모듈을사용하였다. 이 뿐만 아니라, 채널 어텐션 모듈을 통해 재조정된 스케일링 팩터 s를 이용하여 열화 제거에 중요한 채널에는 높은 값들이, 덜 중요한 채널에는 낮은 값들이 곱해지게 된다.
Fig. 2는 우리가 제안한 네트워크의 전체적인 구조이다. 제안한 모델은 열화된 칼라 영상을 입력으로 받고 네트워크의 결과와 입 력 영상을 더 하여 최종적 인 복원 결과를 도출한다. 이와 같이 우리 는 제안한 네 트워 크에 잔여학습 방법을 적용하였고, 이 미 잔 여학습에 대한 효과는 여 러 논문들 [9, 23]에서 입증되 었다.
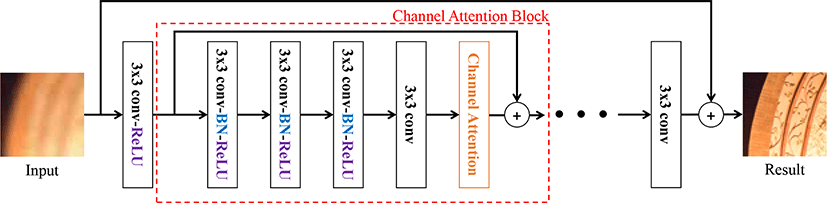
본 논문에서 제안한 모델은 특징 추출기 (feature extractor), 채 널간 어 텐션 블락, 특징 재구성 기(feature reconstruction)로 구성 되 어 있다. 특징 추출기는 128개의 필터를 갖는 3 × 3 × 3 크기의 합성곱 층과 ReLU 활성화 함수로 구성되어 있다. 여 러 가지 열 화를 다루기 위해서 128개의 필터를 사용하였다. 채널간 어텐션 블락은 총 4개의 128개의 필터를 갖는 3 × 3 × 128 크기의 합성곱 층을사용하였고 마지막에는 3.1 절에서 소개한 채널 어텐션 모듈 을 적용하였다. 앞 3개의 합성곱 층에서는 배치 정규화와 ReLU 활성화 함수를 같이 사용하였고, 마지막 4번째 합성곱층은 합성 곱 연산만 적용되도록 구성하였다. 우리는 총 5개의 채널 어텐션 블락을 사용하였다. 마지막으로 3개의 필터를 갖는 3 × 3 × 128 크기 의 합성곱 층으로만 구성 된 특징 재구성 기 를 사용하여 입 력 영상의 채널수와 맞추어 주었고 특징 재구성기 에서 나온 특징맵 과 입력 영상을 더해주어 최종 결과를 얻는다.
손실 함수. 우리는 제안한 모델을 학습하기 위 해 L1 손실 함수를 사용하였다. i번째 열화 영상과 깨끗한 영상을 각각 I(i) 와 J(i) 로, 학습 데이터 셋을 D = {...,(I(i), J(i)),...}라 할때, 아래 식 을 최소화하여 학습을 진행하였다.
위 의 식에서 Θ는 네트워크의 파라미 터, f (I(i); Θ)는 네트워크 출 력 값을 나타낸다.
학습 및 테스트 데이터셋. 제안한 네트워크를 학습하기 위해 [11] 에서 설명한 실험 절차를 따랐다. 800개의 높은 질의 영상이 담 긴 DIV2K 데이터셋을 이용하였다. 이 800개 데이터셋을 학습을 위한 750개의 영상과 테스트를 위한 50개 영상으로 나누어서 사 용하였다. 먼저 학습을 위한 750장의 영상을 1/2,1/3,1/4배 다운 샘플링한다. 그런 다음 학습을 위한 영상과 테스트를 위한 영상 모두 56 픽 셀 간격 으로 63 × 63 크기 로 나눈다. 우리 가 얻는 총 학 습 데이터셋은 230,080장, 테스트 데이터셋은 3,594장이다. 우리 는 학습 및 테스트 데 이 터 셋을 얻 기 위 해 Yu et al.[11] 가 제공한 코드를 이용하였다. Yu et al.[11]가 제공한 코드를 사용했지 만 저 자가 사용한 249,344장보다 적은 학습 데 이 터 셋을 얻 었다. 위 와 같이 영상을 분할한 다음 각 영상에 여 러 가지 열화를 적용했다. 가우시안 블러, 가우시 안 잡음, JPEG 압축을 순서 대로 열화를 적 용했으며 가우시 안 블러와 가우시 안 잡음은 각 표준 편차가 [0, 5] 와 [0, 50] 사이 임의의 값으로, JPEG 압축의 질은 [10, 100] 사이 임의의 값을 사용하였다. Yu et al.[11]은 복합 열화를 extremely mild부터 exttemely severe까지 총 5가지로 구분하였다. Table 1 은 열화 정도에 따라 각 열화마다 level를 나타낸 표로, 각 열화마 다 정도에 따라 1부터 W까지로 level을 분류하였다. 이 표를 기 준으로 3가지 열화의 level 합이 [3, 1이이면 extremely mild, [11, 13]이 면 mild, [14, 19]는 moderate, [20, 22]는 severe, [23, 30]은 extremely severe라고 명명하였다. 우리는 RL-Restore와 OWAN 방법들과 마찬가지로 학습 데 이 터셋에는 열화 정도를 moderate 만 적용하였고, 테스트 데이터셋에는 일반화능력을 검증하기 위 해 moderate 뿐만 아니 라 mild, severe 총 3개 종류의 열화 정도를 적용하였다.
우리는 최적화 방법으로는 β1= 0.9, β2 = 0.999, є = 10−8 의 변수를 가지는 Adam 최적화 방법 [25]을 배치 사이즈는 64 사용하여, 위 에서 언급한 학습 데 이 터셋을 가지고 학습을 진행하 였다. 총 60 에폭(epoch) 동안 학습을 진행하였으며, 초기 학습률 (learningrate)를 1e−3으로 설정하고 15 에폭마다 5배씩 감소하도 록 하였다. 우리는 모델을 구현하기 위해 PyTorch [26]를 사용했 다. 학습에는 약 2일 정도가 걸렸으며, 학습 및 테스트시 CPU는 Intel Zeon E5-2620 @ 2.0 GHz을, GPU는 NVIDIA TITAN RTX (24GB) 을 사용했다.
4. 실험 결과 및 분석
이번 절에서 우리는 제안한 네트워크의 구조를 분석한다. 네트 워크 구조는 성능을 결정하는 중요한 요소 중 하나이 다. 이 에 따 라, 우리는 여러 네트워크 구조에 대해 비교를 진행하였다. 여러 네트워크 구조의 성능을 비교하기 위해 테스트 데이 터셋중 mod-erate 를 사용하여 영상 평가 척도인 Peak Signal-to-Noise Ratio (PSNR) 을 측정하였다.
먼저, Table 2은 합성곱 층의 필터 개수를 64개로 고정하고 다 른 4가지 네트워크 구조에 따른 성능을 보여준다. 첫 번째와 두 번째 네트워크 구조는 채널 어텐션 블락안에 합성곱 층이 2개 인 구조로 4개 인 구조와 총 합성곱 층의 개수를 같게 하기 위 해 총 W개의 블락을 사용하였다. 두 번째와 네 번째 네트워크 구조는 채널 어텐션 블락안의 마지막 합성곱 층에 배치 정규화와 ReLU 활성화 함수를 사용하지 않았고, 반대로 첫 번째와 세 번째 네 트워크 구조는 마지막 합성곱 층에 배치 정규화와 ReLU 활성화 함수를 사용했다. 실험을 통해 우리는 네 번째 네트워크 구조의 성능이 가장 좋음을 입증하였고, 이 구조를 기 반으로 다음 실험을 진행하였다.
| Architecture of network | PSNR |
|---|---|
| Conv-BN-ReLU ×2 | 26.90 |
| Conv-BN-ReLU + Conv | 26.52 |
| Conv-BN-ReLU ×4 | 26.79 |
| Conv-BN-ReLU ×3 + Conv | 26.97 |
그 다음 실험 으로는 채널 어 텐션 모듈의 효과를 검증하기 위 해 채널 어텐션 모듈이 없는 네트워크 구조와 있는 네트워크 구조를 비교하였다. 추가적으로 합성곱 층의 필터 개수에 대한 효과도 검증하기 위해 각 64개와 128개의 필터 개수를 사용하여 비교 하였다. 먼저 첫 번째와 두 번째 네트워크 구조는 채널 어텐션 모듈을 사용하지 않았고, 세 번째와 네 번째 네트워크 구조에서 는 사용하였다. 첫 번째와 세 번째 네트워크 구조에서는 합성곱 층의 필터 개수를 64개를 사용하였고, 두 번째와 네 번째 네트워 크 구조에서는 128개를 사용하였다. Table 3는 네트워크 구성에 따른 성능을 나타낸 것이다. 세 번째와 네 번째 네트워크 구조의 성능이 첫 번째, 두 번째 네트워크 구조 성능에 비해 각 0.15dB, 0.21dB가 상승되었다. 또한 합성곱 층의 필터 개수가 2배로 증가 하면서, 각 0.1dB 이상씩 성능이 증가하였다. 우리는 이 실험을 통해 합성곱층의 필터 개수가 128개이고, 채널 어텐션 모듈을 적 용한 네 번째 네트워크 구조의 성능이 가장 좋음을 입증하였고, 그래서 우리의 최종 네트워크 구조로 채택하였다.
우리는 3.1 절에 소개한 채널 어텐션 모듈뿐만 아니라, 다른 채 널 어텐션 모듈을추가적으로 적용해보았다. [22]에서 제안한 average pooling과 max pooling을 같이 적용한 채널 어텐션 모듈 을 적용하여 실험을 진행하였다. 이 모듈을 사용한 결과 오히 려 average pooling만 있는 모듈을 적용한 네트워크 비해 성능 이 0.04dB 하락하였다. 이를 통해, 복합 열화 복원에서는 average pooling으로부터 얻은 정보가 max pooling의 정보보다 큰 역할을 한다고 볼 수 있고, 최종적으로 우리는 average pooling만 사용한 채 널 어 텐션 모듈을 사용했다.
이번 절에서는 우리가 제안한 네트워크의 타당성을 입증하기 위 해 다른 방법과 성능을 비교한다. 성능을 측정하기 위해 3.3절에 서 언급한 세 종류의 테스트 데이 터셋을 이용하였고, 비교 대상으 로는 최신 복합 열화 제거 방법 인 RL-Restore [11]와 OWAN [12] 과 RL-Restore 논문에서 비교 방법으로 사용한 DnCNN [9]를 채 택했다. 성능 비교를 위해 질적 평가와 양적 평가를 진행하였다. 양적 평 가와 질 적 평 가를 위 해 사용된 코드 및 저 장된 파라미 터 는 저자가 직접 올려 놓은 공식 코드를 사용하였다.
우리는우선 영상 평가에 널리 사용되는 척도인 PSNR 및 sttuctural similarity (SSIM)를 이용해 우리 의 모델을 최신 방법들과 정 량적으로 비교한다. 각 방법들의 PSNR 및 SSIM 수치는 [12]에서 가져온 수치이다.Table 4는 각 방법들과의 정량적으로 비교를 한 결과이다. 이 표를 통해 모든 테스트 데이터셋에 대해 본 논문에 서 제안한 방법의 성능이 가장 우수함을 알 수 있다. 특히, mild 테스트 데이터셋에서는 제안한 방법이 다른 방법들을 큰폭으로 능가한다는 것을 보여준다.
| Dataset | DnCNN [9] | RL-Restore [11] | OWAN [12] | Ours |
|---|---|---|---|---|
| Mild (unseen) | 27.51/0.7315 | 28.04/0.7313 | 28.33/0.7455 | 28.54/0.7493 |
| Moderate | 26.50/0.6650 | 26.45/0.6557 | 27.07/0.6787 | 27.12/0.6793 |
| Severe (unseen) | 25.26/0.5974 | 25.20/0.5915 | 25.88/0.6167 | 25.89/0.6170 |
Fig. 3는 mild 테스트 데이터셋에 대한 여러 방법들과의 질적 비교 결과이다. 첫 번째 행은 원본 영상이고, 두 번째 행은 열화 된 영상, 세 번째와 네 번째, 다섯 번째 행은 각 DnCNN 방법과 RL-Restore 방법, OWAN 방법 의 결과이 다. 마지막으로 여섯 번 째 행은 본 논문에서 제안한 네트워크의 결과이다. DnCNN 방법 은 주로 블러한 영상을 만들어 낸다. RL-Restore 방법의 결과들은 대체적으로 아티팩트들이 많다. 또한 다른 방법들에 비해 블러한 영상들이 많다. OWAN 방법은 색 부분에 대한 복원이 잘 이루어 지지 않는다. 첫 번째와 세 번째 열을 보면, 원본 영상보다 진한 색으로 복원이 이루어지는 것을 볼 수 있다. 우리 방법의 결과는 두 방법에서 문제된 부분이 해결된 것을 볼 수 있다.

이번 절에서는 채널 어텐션 모듈에 대해 분석을 진행한다. 우리는 Table3에서의 실험을통해 복합 열화복원에 채널 어텐션 모듈이 효과적임을 입증하였다.
채널 어 텐션 모듈이 어 떻게 동작하는지 확인하기 위해, 우리는 네트워크에 각 하나의 열화만 적용된 영상을 입력으로 받아 채널 어 텐션 모듈의 가중치 값을 비교한다. Fig. 4은 채널 어 텐션을 분 석하기 위해 사용한 영상들이다. 각 열화정도는 Table 1에서의 강도 5를 적용하였다.
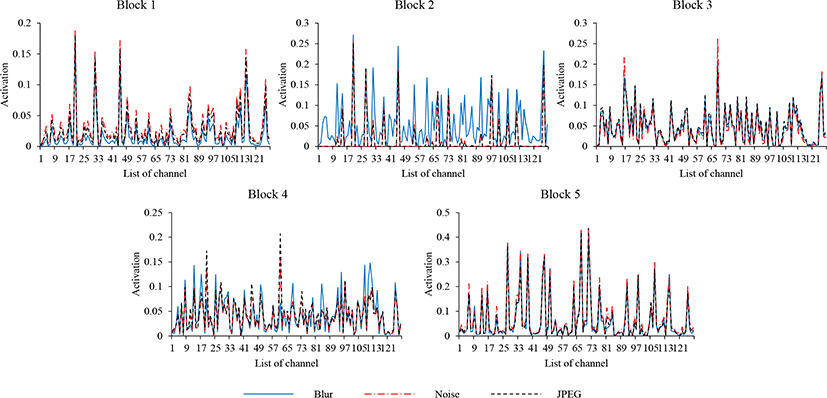
Fig. 5은 열화별로 각 채널 어텐션 블락별 채널 어텐션 모듈에 서 얻은 가중치들을 나타낸다. 먼저 첫 번째와 세 번째, 다섯 번째 블락을 보면 각 열화별로 같은 형태의 가중치 분포를 가지고 가 중치들의 값에서 약간씩만 차이가 있다. 특히, 다섯 번째 블락에 서는 값에도 거의 차이가 없어, 높은 가중치들을 갖는 채널들이 열화를 복원하기 위 해 특징 재구성 에 주로 사용된 채 널이 라고 유 추할 수 있다. 두 번째 블락에서는 블러를 제외한 잡음과 JPEG 압축의 경우 대부분의 가중치들이 0의 값에 수렴해있다. 이를통 해, 두번째 블락에서의 채널들은 대부분 블러를 제거하기 위해 작동한다고 볼 수 있다. 네 번째 블락에서도 열화 별로 약간씩 다 른 가중치 분포를 갖는다. 4. 1절에서의 실험을 통해 복합 열화 복원에 채널 어텐션 모듈을 적용한 네트워크가 높은 성능을 내는 것을 보였고 이번 절의 분석을 통해 우리는 채널 어텐션 모듈이 열화에 따라 다르게 작용하는 것을 입증하였다.
5. 결론 및 향후 계획
본 논문에서는 채널 어텐션 모듈을 적용한 합성곱 신경망을 이 용하여 영상내 복합 열화를 복원하기 위한 방법을 제안하였다. 기존에 제안된 영상 복원 방법들은 영상의 열화종류를 인지하는 상황에만 적용이 가능하기 때문에 자율주행 자동차나 로봇 시스 템과 같은 영상 열화 방법을 인지할 수 없는 상황에는 기존의 영 상 복원 방법을 적용하는데 무리가 있다. 열화를 인지할 수 없는 상황을 해결하기 위해 여러 복합 열화복원 방법들이 제안되었지 만 낮은 영상 품질로 인해 실생활에 적용하기에는 무리가 있다. 우리는 추가 실험을 통해 채널 어텐션 모듈이 복합 열화 복원에 매우 효과적 임을 입증하였고 채널 어텐션 모듈을 적용한 방법의 성능이 기존의 방법들보다 뛰어남을 입증하였다.
하지만 본논문에서 제안한 방법의 한계점도 몇 가지 존재한다. 자율 주행 자동차나 소방 로봇과 같은 시 스템 에 적용하기 위 해서 는 실시간으로 동작해야지만 본 논문에서 제안한 방법은 많은 파라미터가 필요하기 때문에 실시간에 사용하기엔 아직 무리가 있다. 또한 실제로 사용하기 에는 성능이 부족하기도 하다. 영상 열화 종류도 잡음, 블러, JPEG 압축등과 같이 세 가지만 다루어 해상도 저하와 같은 다른 열화에 대한 문제는 여전히 남아있다.
향후에는 복합 열화에 효율적인 새로운 채널 어텐션 모듈을 적용함으로써 성능을 향상시 키 고 네트워크의 경량화를 통해 실 시간으로 적용될 수 있음을 기대한다.

