
1. 서론
컴퓨터 그래픽스의 발전으로 인해 실세계 장면과거의 차이가 없는 가상 장면에 대한 사실적 렌더링(photo-realistic rendering) 영상을 얻는 것이 가능해졌다. 사실적 렌더링 영상을 얻기 위해서는 일반적으로 삼차원 장면을 구성하는 여러 가상 객체와 광원 간의 일어나는 빛의 상호작용을 전역 조명(global illumination) 알고리 즘으로 근사하는 물리 기반 렌더링(physically-based rendering)을 활용한다 [1]. 이러한 물리기반 렌더링은 Maya, 3ds Max, Blender 등과같은 삼차원 그래픽 저작 도구를 이용해 삼차원 장면을 구성 하는 형상, 재질, 조명 조건 등을 각종 장면 요소를 사용자가 직접 조절하여 높은 품질의 영상을 만들어 낼 수 있는 장점이 있지만 방대한 양의 직간접 광원을 모두 고려해야 물리적으로 정확한 영상을 획득할 수 있기 때문에 오랜 렌더링 시간이 걸리는 단점이 있다.
비교적 짧은 렌더링 시간을 가지면서도 고품질의 영상을 얻을 수 있는 사실적인 렌더링 방법의일환으로 뉴럴 렌더링(neural rendering) 기법에 관한 연구가 최근 활발히 진행되고 있다 [2]. 뉴럴 렌더링은 다수의이차원 렌더링 영상을 통해 삼차원 장면의 은닉 정보를 학습하는 뉴럴 렌더러(neural renderer)를 훈련시킨 다음, 훈련된 뉴럴 렌더러를 이용해 훈련에 등장하지 않았던 조건에 대응하는 이차원 렌더링 영상을 추론하는 방식으로 동작한 다. 뉴럴 렌더러가 학습한 삼차원 장면의 렌더링 정보는 신경망의 텐서 구조로 은닉되어 표현되기 때문에, 삼차원 물체의 형상, 빛 의 위치, 물질의 재질 정보 등이 명시적인 형태로 표현되지 않는 것이 특징이다.
본 논문에서는 사용자가 제공하는 반사 하이라이트 맵을 가이 드 영상으로 하는 뉴럴 재조명(neural relighting) 기법을 제안한다. 삼차원 장면에 대한 초기 렌더링에 해당하는 기저 영상(base image)이 주어지면 사용자는 반사 하이라이트가 비치길 원하는 부분을 화면 공간에 맵 형태로 그린다. 제안하는 뉴럴 재조명 기 법은 사용자가 제공한 반사 하이라이트 맵이 반영된 최종 렌더링 결과물과 함께 해당 하이라이트를 발생시키는 광원의 삼차원 위치를 동시 추정(joint estimation)한다.
이를 위해 다양한 조명 위치에서 렌더링 된 영상을 통해 학습 된 백본 뉴럴 렌더러(backbone neural renderer)를 기반으로 기저 영상과 렌더링 결과물의 차이가 사용자가 가이드한 하이라이트 맵과 유사하도록 역전파(back propagation)를 수행함으로써 명시 적인 조명 위치가 추론되도록 신경망을 설계하였다.
제안 네트워크의 성능을 평가하기 위해 두 가지 실험 상황을 수립하였다. 먼저 본 논문의 프레임워크가 사용자의 하이라이트 맵을 얼마나 잘 반영하는지를 측정하기 위해 테스트셋에 있는 렌 더링 영상과 기저 영상의 차이를 실제(Ground Truth, GT) 값으로 간주하고 실제 조명 위치를 추정하는 기준 방법(baseline) 네트 워크를 학습하였다. 이 기준 방법 네트워크가 사용자 하이라이트 맵에 대해 추정한 조명 위치로렌더링한 결과와 기저 영상의 차이 맵과 사용자 하이라이트 맵의 PSNR을 측정하였다. 같은 방식으로 본 논문의 프레임워크가 추정한 재조명 영상과 기저 영상의 차이 맵과 사용자 하이라이트 맵의 PSNR을 측정하고 비교해 본 프레임워크가 사용자의 의도를 반영한다는 사실을 보였다. 또한 본 프레임워크의 정확도를 측정하기 위해 실제 하이라이트 맵으 로 조명 위치와 재조명 영상을 추론한 뒤, 이 추론 결과들의 오차 값을 비교하였다. 실험 결과 추정 광원의 위치 오차율은 삼차원 장면의 크기 대비 0.11 오차율을 가진다.
제안하는 방식은 일러스트레이터 아티스트들이 이차원 화면 공간에서 음영 조절을 하는 방식과 매우 유사한 인터페이스를 가지면서도 기존 렌더링 소프트웨어에서 적용할 수 있는 삼차원 광원 위치를 직접 추론할 수 있다는 장점이 있다. 따라서 삼차 원 렌더링 소프트웨어에 익숙하지 않은일반 사용자뿐만 아니라 전문가들에게도 자신이 원하는 고품질의 렌더링 결과에 쓰일 광 원의 위치와 그에 따른 렌더링 결과물을 예측하는데 활용될 수 있을 것으로 기대한다.
2. 관련 연구
딥러닝의 발전으로 삼차원 장면에 대한 렌더링 영상을 생성 네트웍을 통해 만들어 내는 방법들이 새롭게 제안되고 있다 [2]. Sakurikar 등 [3]은 단일 시점으로 바라본 삼차원 장면의 물체에 대해, 재질이나 빛의 위치 변화에 따라 해당 물체에 대한 광선 추적(ray tracing) 렌더링 영상의 근삿값을 얻어낼 수 있는 뉴럴 렌더러를 제안하였다. 이 렌더러는 시간이 오래 걸리는 광선 추 적 렌더링을 네트워크를 통해 추론하여 빠른 시각화를 가능하게 한다. 이를 위해 재질과 조명의 시각화와 편집이 가능한 대화형 도구를 개발하였고, 광선 추적 렌더링 영상을 포함한 대규모 데 이터셋을 공개하였다.
Thies 등 [4]은 뉴럴 텍스쳐(neural texture)를 이용한 지연 렌더 링(deferred rendering)으로 새로운 시점에 대한 영상을 합성할 수 있는 뉴럴 렌더링 기법을 제안하였다. 이 방법은 삼차원 장면에 있는 물체의 텍스쳐 공간으로부터 최종 화면에 이르는 지연 렌더링 파이프라인을 신경망을 도입하여 구축한 다음, 주어진 삼차원 장면을 여러 각도로 바라본 훈련 영상으로부터 역전파를 통해 물체의 뉴럴 텍스쳐를 학습하는 방식으로 이루어져 있다. 이렇게 학습된 뉴럴 텍스쳐는 물체의 디테일한 형상, 재질, 빛 조건 등 에 대한 정보를 함축적으로 은닉하고 있기 때문에 물체의 프록시 삼차원 형상(proxy 3D geometry)만으로도 새로운 시점에 대한 사실적인 합성 결과를 얻을 수 있다.
Zhang 등 [5]은 영상을 환경 조명(environment lighting)과 물 체의 내재적인 특성(object intrinsic attribute), 빛 전달 함수(light transport function)의 세 가지 요소가 상호조합된 결과로 해석하고, 렌더링 영상 데이터를 기반으로 이들 요소를 학습하는 뉴럴 렌더러를 제안하였다. 제안하는 뉴럴 렌더러와 기존 물리 기반 렌더러를 통합해 재조명뿐만 아니라 새로운 시점에 대한 영상 합성도 가능함을 보였다.
본 연구는 삼차원 장면에 대한 다양한 렌더링 조건을 신경망의 텐서 형태로 학습한 뉴럴 렌더러를 백본 네트웍으로 활용하여 사 용자가 입력으로 준 반사 하이라이트 맵을이용해 광원의위치를 직접적으로 추정한다는 점에서 기존 연구들과 차별점을 가진다.
뉴럴넷을 통해 주어진 영상에 대한 물체의 표면 재질과 빛의 방향을 알아내는 연구가 활발히 진행되었다. 이러한 연구들은 라이트 프로브(light probe) 등과 같은 중간 단계의 광원 표현을 알아내는 방법 [6, 7, 8, 9]과 이러한 중간 단계 표현 없이 빛의 위치나 방향을 바로 알아내는 방법 [10]으로 나눌 수 있다.
Gardner 등 [7, 6]은 실세계의 구조화되지 않은 조명들을 파라 미터화한 후 이미지로부터 정의한 파라미터를 추론하는 네트워 크를 제안하였다. Wang 등 [8]은 같은재질이 여러 조명에서 관측 된 영상들과 다른 재질이 하나의 조명에서 관측된 영상들을 행렬 구조의 정형화된 훈련 데이터로 모아 물체의재질과 조명을 동시에 추정하는 신경망을 제안하였다. Zhou 등 [9]은 얼굴 사진들에 대해 알고리즘적인 방법으로 데이터셋을 만들고, 이를 이용해 재조명 처리된 인물 사진을 생성하는 네트워크를 제안하였다. Kán 등 [10]은 상대적 오일러 각도 표현(Euler angle representation)을 이용해 RGB-D 영상으로부터 3차원 좌표계 상의 조명 방향을 실 시간으로 알아내는 방법을 제안하였다.
본 논문에서 제안하는 방법은 화면 공간에서 사용자가 하이라 이트 맵을 가이드해 줄 수 있다는 점에서 기존의 영상 기반 광원 추정 방식에 비해 보다 효과적인 사용자인터페이스를 제공한다 는 점에서 차별성을 가진다.
사용자 스트록에 기반하여 주어진 영상의 쉐이딩(shading)을 업 데이트하는 연구가 스타일라이즈드 렌더링(stylized rendering) 분야에서 진행되었다 [11, 12, 13, 14]. Sloan 등 [11]과 Fišer 등 [14]은 사용자가 구체 등 간단한 기하도형에 적용한 쉐이딩 예제로부터 해당 쉐이딩이 복잡한 모델에 적용되었을 때의 결과를 만들어 내는 예제 기반(example-based shading) 기법을 제안하였 다. 이 방법들은 단순한 기하 도형에 사용자가 쉐이딩한 예제의 법선(normal) [11], RGB 색상 [13, 12], 빛 전달(light propagation) [14] 정보 등이일치하는 패치를 복잡한 모델이 그려진 영상에서 찾아 쉐이딩을 업데이트한다. 최근 Zhang 등 [15]은 아티스트가 부여한 스트록의 밀도로부터 광원 효과를 추정할 수 있다는 가정 하에, 스트록 밀도맵(stroke density map)을 생성하고 이를 이용해 이차원영상을재조명하는 방법을 제안하였다. 볼록 껍질 기반 색상 팔레트(convex-hull based color palette)를 사용하여 영상에서 사용된 색상 조합을 알아내고, 이를 기반으로 생성한 스트록 밀 도 맵을일종의 높이 함수로 해석하여 주어진 광원의위치에 대한 재조명 영상을 생성한다. 이 방법은 아티스트에게 친숙한 인터페 이스를 제공하고 있지만, 데이터에 기반한 방법이 아니기 때문에 아티스트가 직접 쉐이딩한 결과와는다소 차이가 있다는 한계가 있다.
3. 프레임워크
본 논문에서는 기저 영상 위에 사용자가 지정(annotation)한 반사 하이라이트 맵을 이용해, 반사 하이라이트 맵을 반영하는 조명 위치와 재조명 영상을 추론한다. 이를 위해 [3]에서 제안하는 뉴 럴 렌더러를 백본 네트워크로 활용하였다. 백본 네트워크의 모 든 파라미터는 고정하고, Fig. 1에 빨간색 박스로 그려진 요소를 역전파로 변화하도록 만들어 최적화를 수행한다. 이 때, 뉴럴 렌더러의 은닉 정보는 렌더링된 영상과 기저 영상의 차이가 반사 하이라이트 맵과 유사하도록 최적화되며 사용자의 의도를 반영 하는 명시적조명 위치는 동시 최적화 된다.
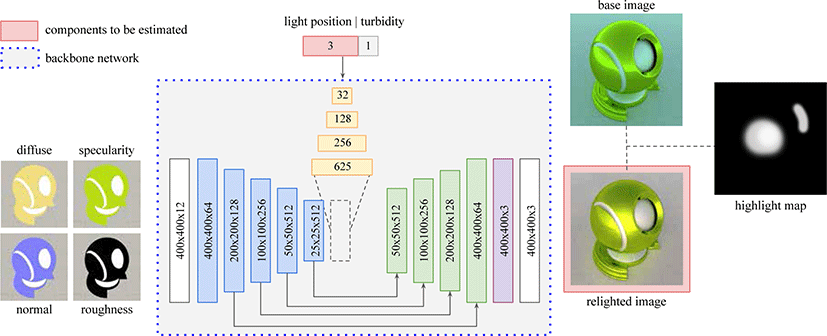
본 논문에서 사용하고 있는 백본 뉴럴 렌더러는 재질의 시각화를 위해 고정된 형상 및 시점에 대해 다양한 재질과 조명을 적용한 광선 추적 기반 렌더링 결과를 학습하는 신경망이다 [3]. 고정된 형상에 대해 5,000개의재질과 각각에 대한 5개의 랜덤 조명 위치를 하나의 시점으로렌더한 영상들을 학습 데이터로 사용해학습 한 다음, 테스트 시에는 학습에 포함되지 않은 입력이 주어져도 해당 입력에 대응하는 렌더링 결과를 빠르게 추론한다.
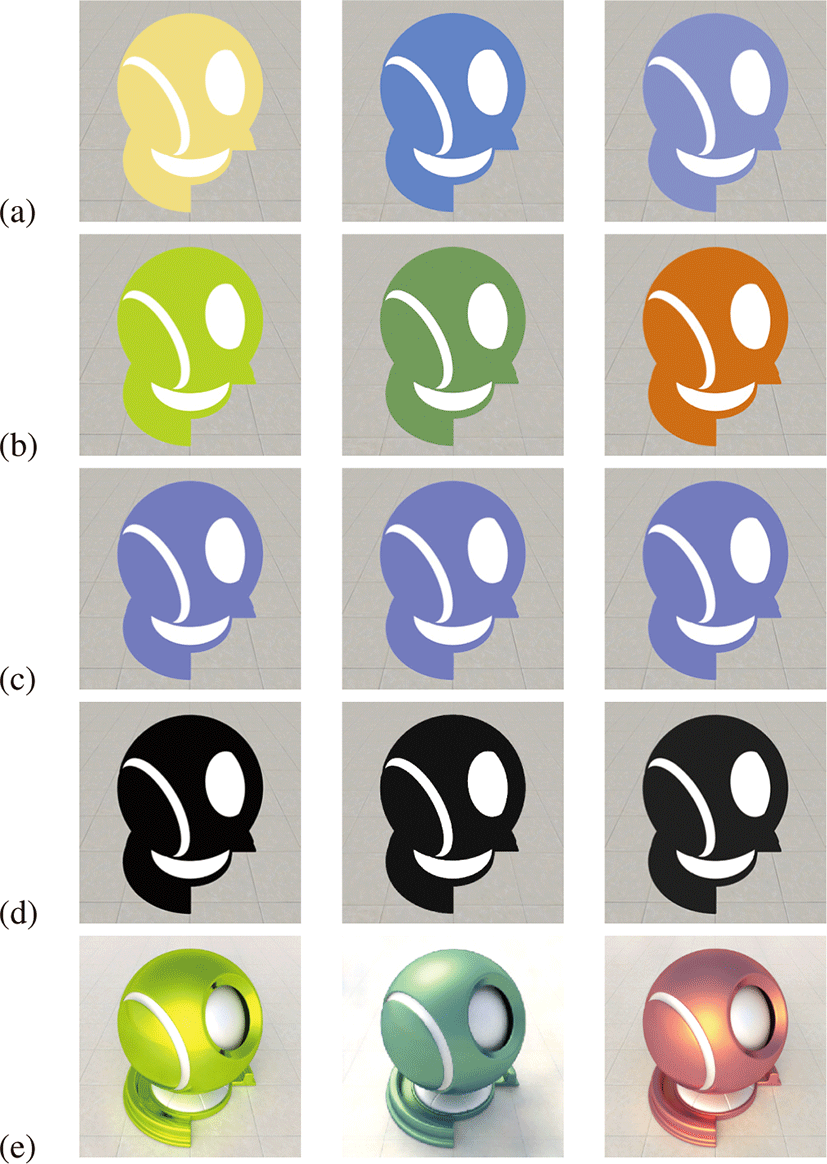
본 논문의 프레임웍에 입력으로 사용되는 렌더링 정보의 표 현법은 뉴럴 렌더러 [3]에서 사용하는 것을 그대로 따른다. 재질은 Fig. 2에서 보이는 것처럼 분산(diffuse), 반사(specular), 거칠기(roughness), 법선(normal)맵들의 조합으로 표현한다. 조명은 Hosek-Wilkie 하늘 모델(sky model) [16]을 사용해 환경 조명(environment light)을 조명의 3차원 위치와 흐림 정도(turbidity)의 조합으로 표현한다. 따라서 백본 네트워크는 해당 재질을 표현 하는 4개의 맵과 조명을 표현하는 4차원 벡터를 입력으로 하여 뉴럴 렌더링된 영상을 출력한다.
본 논문에서는 이 뉴럴 렌더러 [3]를 제안하는 뉴럴 재조명 프레임워크의 백본 신경망으로 사용한다.
제안하는뉴럴 재조명 프레임워크는 사용자가 지정한 반사 하이 라이트 맵으로부터 이를 반영하는 Hosek-Wilkie 하늘 모델 [16] 의 조명 위치를 최적화하고 대응되는 재조명 영상을 생성한다.
백본 뉴럴 렌더러의입력으로 들어가는 조명 위치를 변경가능 하게 하여 백본의은닉층으로부터 조명 위치를 명시적으로 추론 할 수 있게 된다. 추론한 결과의 정확도는 재조명된 영상과 기저 영상의 차이와 유저의 하이라이트 맵에 대해 패치 기반 평균 제곱 오차(Mean Squared Error, MSE)로 측정한다.
네트워크 구성Fig. 1에 보이듯이 우리의 프레임워크의입력은 특정 재질에 대한 4 가지 재질 맵 (Fig. 2), 조명 정보, 기저 영상, 그리고 사용자가 화면 공간(screen-space) 인터페이스로 지정한 반사 하이라이트 맵이다. 이 영상들을입력으로 받아 반사 하이라 이트 맵을 반영하는 조명의위치와 해당 조명을이용해 재조명된 영상을 출력한다. 백본 신경망의 입력인 재질 맵과 조명 정보 중 조명의 위치를 변화할 수 있게 하였고 백본 신경망의 모든 파라 미터는 고정하여 전체 프레임워크에서 조명의 위치만 역전파를 통해 변화하도록 하였다. 재질 맵과 조명 위치가 입력으로 주어 지면 네트워크는 출력 이미지를 생성하고, 역전파를 통해 조명의 위치를 최적화한다.
사용자 가이드 반사 하이라이트 맵Fig. 1에서 기저 영상(base image)은 특정 재질에 대해 조명 위치를 원점 (0, 0, 0)T 으로 설정 하고 렌더링한 영상이다. 사용자가 기저 영상 위에 반사 하이라 이트를 표시하면 사용자의 입력으로부터 Fig. 1의 하이라이트 맵 (highlight map)을 획득한다. 우리의 프레임워크는 반사 하이라이 트 맵을 만족하도록 재조명 영상과 조명의위치를 최적화한다.
손실 함수 입력으로 모델의 재질에 대한 분산맵 D, 반사맵 S, 노말맵 N, 거칠기맵 R, 그리고 조명의 위치 l가 주어지면 뉴럴 렌더러 𝓕(·)로 입력을 반영하여 이미지를 렌더링한다. 렌더링된 이미지에서 기저 이미지 B를 뺀 이미지가 반사 하이라이트 맵 A 과 유사해지도록 조명의 위치 l가 최적화된다. 손실함수는 사용 자의 지정한 반사 하이라이트 맵 A을 최대한 반영하기 위해 패 치 기반 평균 제곱 오차(Mean Squared Error, MSE)를 사용한다. 이미지를 작은 패치 단위로 나누어 사용자의 지정한 반사 하이라 이트가 지나가는 영역에 해당하는 평균 제곱 오차만 손실함수에 반영한다.
여기서 θ는 뉴럴 렌더러 𝓕(·)의 파라미터를 의미하고, 최적화 과정전에 미리 학습되어 최적화 과정에서는 업데이트 되지 않는다. 𝟙(·)는 지시 함수로 반사 하이라이트 맵 A의 i 번째 패치 영역에 사용자가 지정한 반사 하이라이트가 있으면 1, 아니면 0을 출력 한다. Npos는 사용자가 지정한 반사 하이라이트가 있는 패치의 개수이다.
4. 실험
본 논문에서 제안하는 프레임워크는 뉴럴 렌더러1 [3]를 활용해 서 구성하였다. 네트워크의 입력 맵들과 출력 영상의 해상도는 400 × 400 픽셀이며, 조명 벡터의 차원은 3차원으로 하였다. 뉴럴 렌더러는 [3]에서 제안된 학습 방법으로 미리 학습 시켜 사용하 였다.
주어진 반사 하이라이트 맵(specular highlight map)을 만족 하도록 조명의 위치와 재조명 영상을 최적화하기 위해, Adam optimizer를 사용하여 0.001의 학습률(learning rate)을 사용하여 6,000번 반복하여 최적화한다. 미리 학습된 뉴럴 렌더러의 파 라미터들은 변화되지 않도록 했으며, 조명의 위치만 최적화한 다. 조명의 위치와 재조명 영상을 최적화하는 데 걸리는 시간은 NVidia GTX 2080을 사용한 환경에서 약 4분 정도 소요된다.
제안하는 프레임워크의 백본 뉴럴 렌더러를 학습하기 위해 [3]에 서 제공한 쉐이더볼 (shaderball)과 더불어 유타 찻주전자 (Utah teapot), 파라오 (Pharaoh) 모델에 대한 장면 데이터셋을 각각 구 성하였다. 백본 뉴럴 렌더러는 각 장면마다 별개로 학습되며, 각 장면에 대한 학습 데이터셋 구성은 다음과 같다. 데이터셋은 단 일 시점과 형상에 대해 Fig. 2과 같이 물체 표면의 재질(material)을 구성하고, 여러 재질에 대해 랜덤한 위치에 설정한 광원으로 렌더링한 Fig. 2의 (e)와 같은 영상들을 제공한다. 데이터셋이 제 공하는 재질의 수는 5,000개이며 각 재질에 대해 5개의 조명을 적용해 총 25,000개의 영상을 구성한다. 재질 영상과 렌더링 된 영상의 크기는 400 × 400이다. 추가로 각 재질에 대해서 광원 위치를 원점으로 설정하고 Blender [17]의 Cycle 렌더러로 렌더링 하여 생성한 5,000개의 기저 영상을 본 연구의 성능을 평가하는데 사용하였다.
제안하는 방법으로 뉴럴 재조명된 영상과 추정되는 조명의위치가 사용자의 입력으로 만든 반사 하이라이트 맵을 얼마나 정확하 게 반영하는지를 실험을 통해 확인한다.
기준 방법 제안하는 방법과의 비교를 위한 기준 방법(baseline method)으로 조명의 위치를 추정하는 네트워크를 구성하였다. 기준 방법은 기저 영상과 반사 하이라이트 맵을 입력으로 받아 광원의위치를 추정한다. 데이터셋으로부터 기저 영상과 렌더링 된 영상(GT image)의 차이 맵을 계산하여 Fig. 6(b)과 같은 실제 하이라이트 맵(GT highlight map)을 구성했다. 네트워크는 기저 영상과 실제 하이라이트 맵을입력으로 받아 광원의위치를 추정 한다. 이를 위해 뉴럴 렌더러 [3]의인코더 부분을 변경하여 구성 하였다. 25,000개의입력 영상과 조명 위치로 구성된 데이터셋을 이용하여, Adam optimizer를 사용해 30 epoch으로 학습시켰다.
평가Fig. 3은 기저 영상(Fig. 3(a))을 사용자가 지정한 반사 하 이라이트 맵(Fig. 3(b))을 이용해서 제안하는 방법으로 재조명한 영상(Fig. 3(d))과 추정된 조명의 위치를 이용해 렌더링한 영상 (Fig. 3(e)), 그리고 기준 방법으로 추정한 조명의 위치를 이용해 렌더링한 결과(Fig. 3(c))를 보여준다. 제안하는 방법으로 재조명 되는 영상과 추정되는 조명 위치의 결과가 기준 방법의 결과보다 하이라이트 맵을잘 반영하는 것을 확인할 수 있다.

우리는 각 방법으로 추정한 영상과 기저 영상의 차이 맵과 사용 자가 지정한하이라이트 맵의 차이를 PSNR(Peak Signal-to-Noise Ratio)로 계산하였다. PSNR이 높을수록 추정한 결과가 반사 하 이라이트 맵을 잘 반영한다고 할 수 있다. Table 1에서 제안하는 방법이 기준 방법과 비교하였을 때 높은 PSNR을 나타내는 것을 확인할 수 있다.
| Method | shaderball | |
|---|---|---|
| PSNR (dB) ↑ | ||
| Mean | Med. | |
| baseline | 09.42 | 09.18 |
| Ours | 10.52 | 10.51 |
Fig. 4와 Fig. 5은 유타 찻주전자와 파라오 모델로 구성된 장면에 대해 동일한 실험을 수행한 결과이다. Fig. 4와 Fig. 5의 (a) 와 (b)는 각각 해당 장면의 기저 영상과 사용자가 지정한 반사 하이라이트 맵을 보여주며, (c)와 (d)는 각각 제안하는 방법으로 재 조명된 영상과 추정된 조명 위치의 결과를 이용해 Blender [17]의 Cycle 렌더러로렌더링한 결과를 보여주고 있다. Fig. 4와 Fig. 5의 (c)와 (d) 의 렌더링 결과가 서로 유사한 것을 확인할 수 있었으며, 이를 통해 본 논문에서 제안하는 뉴럴 재조명 기법이 사용자 지 정 반사 하이라이트 맵을 반영하는 재조명 결과와 이에 해당하는 삼차원 조명 위치에 대한 동시 추정이 가능함을재확인하였다.


테스트 데이터셋 제안하는 방법이 추정하는 조명의 위치에 대한 정확도를 측정하였다. 먼저 실제 조명 위치에 대한 테스트 데이터셋을 구성하였다. Fig. 6(a)와 같이 기저 영상(base image)을 선택하고 기본 이미지를 렌더링한 재질과 임의의 위치에 대한 광원을 이용해 Fig. 6(c)와 같이 반사광이 적용된 영상을 렌더링 하였다. Fig. 6(b)와 같은 반사 하이라이트 맵은 실제 조명의 위 치를 적용해 렌더링한 영상(Fig. 6(c))과 기저 영상(Fig. 6(a))의 차이로 생성하였다. 실험을 위해 100개의 기저 영상, 실제 반사 하이라이트 맵, 그리고 실제 조명의 위치와 이로 렌더링한 실제 영상을 생성하였다. 테스트셋은 훈련 데이터셋과 마찬가지로 각 재질에 대해 Hosek-Wilkie 하늘 모델 [16]로 표현되는 조명 조건 으로 Blender [17]의 Cycle 렌더러를 이용해 생성했다.
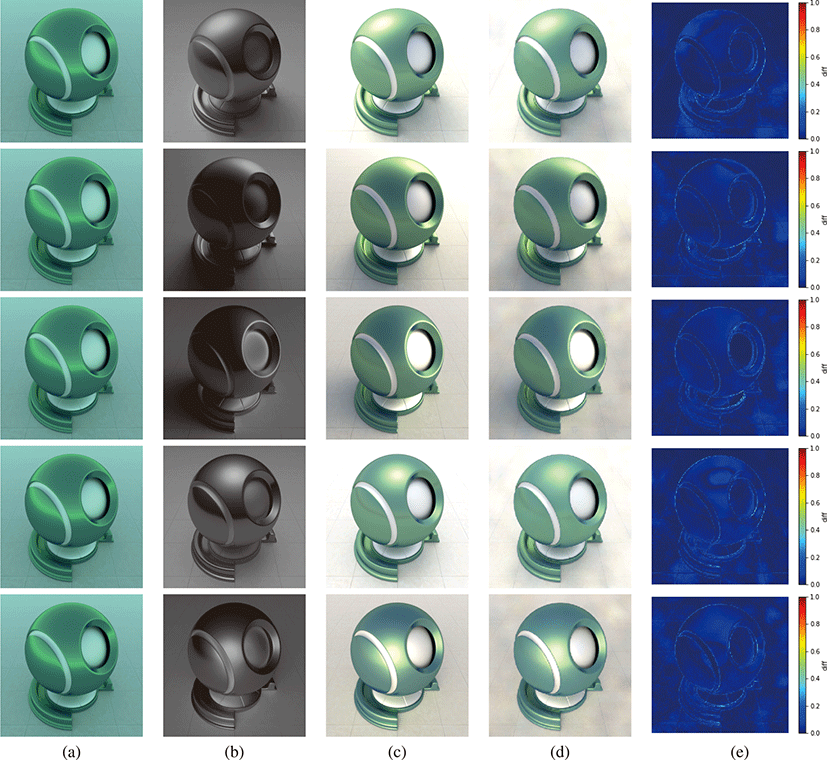
평가 위의 방법으로 계산된 반사 하이라이트 맵을입력으로 조명의 위치와 재조명된 이미지가 실제 조명의 위치, 이미지와 얼 마나 동일한지 측정하였다. 실제 조명과 추정된 조명의 위치는 유클리디안 거리(Euclidean distance)로 차이를 측정하고, 실제조 명의위치를 포함하는 장면의 바운딩 박스(bounding box)의 대각 선 길이에 대한 비율을 계산하였다. 실제 영상과 재조명된 영상의 차이는 PSNR로 측정하였다.
Fig. 6는 제안하는 방법으로 테스트 데이터셋에 대해서 조명의 위치를 추정하고 재조명한 결과를 보여준다. Fig. 6(e)는 실제 영상 Fig. 6(c)과 재조명한 영상 Fig. 6(d)의 차이를 나타낸 것으로, 제안하는 방법이 실제 영상과 유사하게 재조명한 것을 확인할 수 있다. Table 2에서 추정한 조명의 위치의 차이는 평균 0.11이고 PSNR은 평균 28.89 dB인 것을 확인할 수 있다. 이 때 실제 조명 위치를 포함한 바운딩 박스를 설정해 이에 대한 대각선 길이를 기준으로 추정한 조명 위치를 정규화하여 오차를 측정하였다.
| Method | light position | PSNR (dB) | ||
|---|---|---|---|---|
| Mean | Med. | Mean | Med. | |
| Ours | 0.11 | 0.13 | 28.89 | 28.46 |
Fig. 7은 조명의 위치에 따른 PSNR 수치의 변화를 시각화한 결과이다. 실험을 위해 100개의 실제 조명 위치를 전역좌표계를 기준으로 방위각(azimuth)과고도각(elevation)에 따라 배치한 후, 각 위치에서 실제 영상과 재조명된 영상의 차이를 PSNR로 측정 하였다. Fig. 7에서 상대적으로 큰 원은 높은 PSNR을 나타내고, 작은 원은 낮은 PSNR을 나타낸다. Fig. 7을 통해 고도각이 PSNR 에 영향을 미치고 있으며, 특히 바닥 평면 대비 조명의 고도가 낮을 수록 결과 영상의 PSNR이 높아지는 것을 확인할 수 있다.
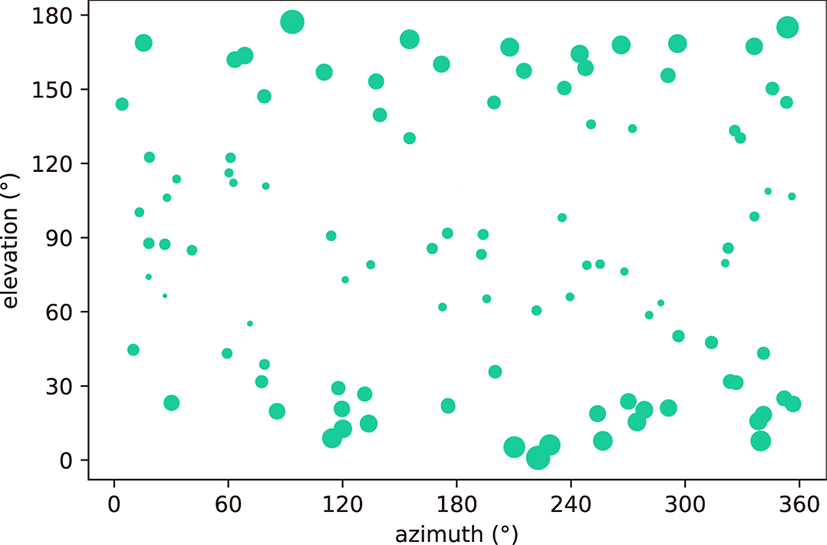
Fig. 8은 조명의 실제 위치에 대한 방위각과 고도각을 각각 [0.2, 1.2, 2.2, 3.2, 4.2, 5.2]과 [0.2, 0.7, 1.2, 1.7, 2.2, 2.7] 라디안 (radian)으로 변화시키며 얻은재조명 결과를 보여주고 있다. Fig. 9은 Fig. 8을 만들어내기 위한 실제 영상과 반사 하이라이트 맵을 보여준다. Fig. 9의 2번째,3번째,4번째 행에서 보이는 것처럼 바닥 평면 대비 실제 조명의 고도가 높으면 실제 영상이 기저 영 상에 비해 밝아지기 때문에 반사 하이라이트 맵이 배경을 포함한 영상 전체에 대해 생성된다. 이 경우 실제 반사 하이라이트 맵이 거의 대부분의 픽셀에서 형성되기 때문에 제안하는뉴럴 재조명 이이를만족하도록 최적화를 진행하게 되어 최종 재조명 결과의 PSNR은 상대적으로 낮아지게 된다. 반면에 실제 조명의 고도가 낮으면 실제 영상과 기저 영상의 밝기 차이가 일부의 픽셀에서만 드러나기 때문에 제안하는뉴럴 재조명 기법이 실제 반사 하이라 이트 맵의 특정 부분에 대해서만 최적화를 진행하게 되어 재조명 결과 영상의 PSNR이 상대적으로 높아지게 된다.


5. 결론 및 향후 연구
본 논문에서는 사용자가 지정한 반사 하이라이트 맵을 가이드 영상으로 하는 신경망 기반 재조명 기법을 제안하였다. 기저 영상과 렌더링 영상의 차이가 사용자가 제공한 반사 하이라이트 맵과 유사하도록 역전파에 의해 광원의위치와 관련된 재조명 이미지를 동시 최적화하는 방식으로 아티스트가 선호하는 이차원 화면 공간 인터페이스를 제공하면서도 삼차원 조명의 위치를 명시적으로 추론할 수 있는 장점이있다.
향후 본 논문에서 제안하는 기법을 아티스트의 편의성을유지 하면서 보다다양한 삼차원 장면에 대한 결과를 예측할 수 있도록 다양한 방식으로 확장할 계획이다. 현재 하나의 모델과 시점에 대해서만 작동하는 프레임워크를 다양한 모델과 시점에서도 동 작이 가능하도록 확장할 계획이다. 다음으로 여러개의 조명을 추정하는 연구와 사용자가 반사 하이라이트뿐만 아니라 그림자를 지정하면 이를 만족하는 조명 조건을 추정하는 연구를 진행 중이다.



