
1. 서론
3차원 형상 복원(3D reconstruction)은 이미지 또는 영상 속 물체 의 형상을 3차원 모델로 복원하는 기술이다. 전통적인 3차원 형 상 복원은 여러 시점에서 획득한 이미지를 사용하는 다중시점 스테레오(multi-view stereo) 알고리즘들 [1]을 기반으로 발전해 왔으며, 단일 이미지로 부터 물체 형상을 복원하는 것은 도전적 인 문제였다. 하지만, 딥러닝 기반의 인공지능 기술의 발전에 힘 입어 단일 이미지 기반 3차원 형상 복원 기술이 크게 발전하였 다 [2, 3, 4, 5].
인공신경망을 이용한 3차원 형상 복원 기술은 네트워크의 출 력 형태에 따라 크게 명시적 표현 기법과 음함수 기반의 암묵적 표현 기법으로 분류할 수 있다. 명시적 표현 기법은 복셀(voxel), 포인트(point), 메시(mesh) 등 과 같은 기하 객체를 이용하여 형 상을 표현하는 기법으로, 형상 표현이 직관적이고 사용이 쉽다는 장점을 가진다 [6, 3, 2, 7, 8, 9, 10, 4]. 하지만, 명시적 표현 방 법을 사용하는 기술들은 제한적인 해상도 또는 낮은 토폴로지 (topology) 표현의 한계를 가진다.
물체의 내외부 경계면을 표현하는 음함수(implicit function)를 기반으로 물체의 형상을 복원하는 암묵적 표현을 사용하여, 명시 적 표현 기법의 한계인 해상도 문제를 해결할 수 있다. Mescheder 등 [11]은 주어진 좌표(또는 포인트)의 물체 내부(점유) 여부(확 률)를 출력하는 점유 네트워크(occupancy network, ONet)를 제 안하였다. ONet은 입력 포인트의 점유 여부만 판단하기 때문에, 입력 포인트의 개수에 제한이 없이 원하는 해상도로 물체 형상을 복원 할 수 있다는 장점을 가진다. 그 결과, ONet은이미지 속 물 체 종류에 맞추어 전반적인 형상을 성공적으로 복원하는 결과를 보여주었다. 하지만, 복원된 물체의 세부 모습(예, 의자 등받이의 기둥들)은잘 표현되지 않는 한계를 가진다.
본 연구는 물체의 세부적 모습까지 복원할 수 있도록 표현력 을 높인 점진적 점유 네트워크(progressive occupancy network) 를 제안한다. 이미지 전체의 정보를 담고 있는 전역 특징(global feature)을 사용해서 물체의 형상을 추론하는 ONet [11]과 달리, 본 연구는 수용 역영(receptive field)의 크기에 따른 다양한 수준 의 이미지 특징을 추출해서 사용함으로서, 물체의 세부적 모습 복원에 대한 네트워크의 표현력을 높인다(3.3장 및 3.4장). 또한, 다양한 수준의 이미지 특징을 단계적으로 사용함으로서,3차원 형상 복원 품질을 점진적으로 향상시키는 점진적점유 네트워크 구조를 제안한다(3.2장). 그리고 물체 세부 형상 복원 과정에서 전역적 특징이 깨지는 문제를 해결할 수 있도록 서로 다른 수준 의이미지 특징을 조합해서 사용하는 디코더 네트워크 및 디코더 블록 구조를 제안한다(3.5장).
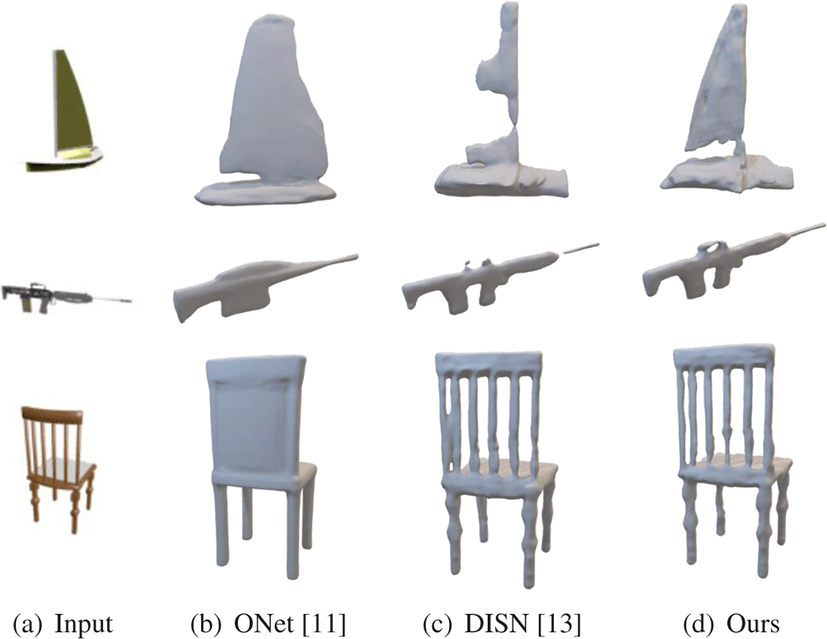
본 연구는 제안하는 네트워크를 ShapeNet [12] 데이터 세트를 사용하여 학습시켰으며, 그 성능을 두 가지 기존 연구(ONet [11], DISN [13])와 비교 하였다(4장). 그 결과,3차원 복원 품질을 측정 하는 세 가지 지표 모두에서 ONet대비 높은 성능을 달성하였으 며, DISN와 대등한 수준의 점수를 얻었다. 또한, 시각적 복원 결 과 비교를 통해 ONet 및 DISN이 표현하지 못한 물체의 세부적 형 상을잘잡아내는 모습을 확인 할 수 있었다(Figure 1과 Figure 5).
2. 관련 연구
한장의 이미지로 부터 3차원 형상을 복원하는 인공신경망 기술 은 출력의 형태에 따라 명시적 표현 기법과 음함수(implicit function) 기반의 암묵적 표현 기술로 구분된다. 명시적 표현 기법 은 사용하는 기하 객체(geometric primitive)에 따라 다시 복셀 (voxel) 기반 [6, 3], 포인트 클라우드(point cloud) 기반 [2, 7, 8, 9], 그리고 메시(mesh) 기반 [10, 4, 14] 기법으로 구분된다.
복셀은 데이터 구조가 단순하고 사용이 쉽다는 장점을 가지며, 복셀의 격자에 대한 3차원 합성곱 신경망을 이용한 3차원 형상 복원 기술들이 연구되었다 [6, 3]. 하지만 복셀은 해상도 향상에 따른 메모리 부하 크다는 단점을 가지며, 복셀 기반의 인공 신 경망을 통해 처리할 수 있는 격자의 해상도가 상대적으로 낮다 (예, 323 또는 643)는 한계를 가진다. 최근에는 팔진트리(octree) 와 같은 적응형 데이터 구조를 사용하는 등의 방법으로 이러한해 상도의 한계를 극복하기 위한 연구들이 진행되었다 [15, 16, 17]. 하지만, 여전히 해상도가 일정 수준으로 제한되며(예, 2563) 얕 은 구조(shallow architecture)에서 작은 크기의 배치를 사용해야 한다는 단점을 가진다.
복셀 기반 3차원 형상 복원 기법의 대안 중 하나로, 물체의 형 상을 포인트 클라우드 형태로 출력하는 인공신경망 기술들이 연 구되었다 [2, 7, 8, 9]. 포인트는 필요한 부분에만 위치하면 되기 때문에 해상도(포인트의 수)에 따른 메모리 부하가 복셀에 비해 적다는 장점을 가진다. 하지만, 포인트는 위치에 대한 자유도가 높고 연결성(connectivity)을 갖지 않기 때문에 물체의 형상을 정 확히 표현하는데 한계를 가진다. 또한, 물체의 표면(surface)을 표 현하기 위해서는 마칭큐브(marching cube) [18] 등과 같은 후처 리를 필요로 한다.
메시는 3차원 형상을 표현하기 위해 가장 널리 사용되는 기학 객체 중 하나로, 직접 메시를 생성하는 3차원 형상 복원 인공신경 망 기술들도 연구되었다 [10, 4, 14]. Wang 등 [4]은 템플릿 도형 (예, 타원체)을 형상에 맞추어 변형(메시를 구성하는 정점의 이 동)하고 메시의 해상도를 업-샘플링(up-sampling)하는 과정을 반 복하는 Pixel2Mesh 방법을 제안하였다. 그들은 카메라 정보를 이 용하여 3차원 공간 상 정점을 이미지 평면으로 투사(projection) 하고, 해당 위치에 대한 이미지 특성인 지각적 특성(perceptual feature)을 추출하여 사용하였다. 그 결과, 3차원 형상의 세세한 부분까지 높은 품질로 복원하는 결과를 보여주었다. 하지만, 낮 은 토폴로지의 간단한 템플릿 도형을 사용하며 템플릿과 다른 토폴로지를 가지는 형상을 복원할 수 없다는 아쉬움을 가진다. Groueix 등 [14]은 파라메트릭 표면(parametric surface)들을이용 하여 물체의 3차원 형상을 복원하는 AtlasNet을 제안하였으며, 다양한 토폴로지의 물체 형상 을 높은 품질로 복원하였다. 하지 만, 폴리곤 패치를 붙인 형태로 메시 사이의 연결성 정보를 표 현하지 못하고 서로 중첩이 발생 가능하다. 그 결과, 결과물들의 표면이 매끄럽게 표현되지 못한다는 단점을 가진다.
위에서 살펴본 것과 같이, 기하 객체를 사용한 명시적 표현 방 법을 사용하는 기술들은 제한적인 해상도 또는 낮은 토폴로지 표현의 한계를 가진다. 음함수 기반의 형상 표현은 이러한 한계 를 극복할 수 있는 대안 중 하나다 [11, 19, 20, 13, 21]. Mescheder 등 [11]은 주어진 3차원 포인트가 물체의 내부(점유)일 확률을 추 론하는 점유 네트워크(ONet)를 제안하였다. 그들은 3차원 격자 의 각 셀의 점유를 예측하고, 점유 셀을 분할 및 다시 점유예측을 수행하는 것을 반복함으로서 해상도 향상에 따른 메모리 부하 문제를 해결하였다. 또한, 마칭 큐브를 이용하여 최종 메시를 생 성함으로써 메시 중첩 및 연결성 정보 부재 문제를 해결하였다. 그 결과, ONet은입력 이미지 속 물체의 형상을 높은 해상도를 가 지는 메시로 복원해 냈다. 하지만, 이미지의 전체의 정보를 담고 있는 특성 벡터(전역 특성)로 잠재 공간(latent space)을 조절함 으로서, 물체의 세부 상세를 잘 표현하지 못하는 한계점을 가진 다(Figure 1(b)). Saito 등 [19]은 지역적 이미지 특성(local image feature)을 사용하여 옷을 입은 사람의 형상을 세부 상세까지 높 은 품질로 복원하였다. Xu 등 [13]은이미지의 전역적 특성(global feature)과 지역적 특성(local feature)을 동시에 사용하여 부호가 있는 거리 장(signed distance field, SDF)을 예측하는 DISN(Deep Implicit Surface Network)을 제안하였다. DISN은 전역적 특성과 지역적 특성 각각으로 예측한 SDF를 합하여 최종 SDF를 예측하 며, 마칭큐브 알고리즘으로 복원한 물체의 형상이 세부 상세까지 잘 잡아내었다. 하지만, 물체의 매우 얇은 부분이 복원 시 손실 되는 경우가 종종 있다는 한계를 가진다(Figure 1(c)).
본 연구가 제안하는 네트워크는 ONet 구조 [11]에 기반을 두고 있다. 하지만, 이미지 전체 정보를 담은 전역적 특성뿐만이 아닌 3 차원 포인트의위치에 기반을 둔 지역적 특성을 추출하고 전역적 특성과 함께 사용한다는 점에서 ONet과 차별성을 가진다. 또한 본 연구는 지역적 특성을 사용한다는 측면에서는 Saito 등 [19] 및 DISN [13]과 유사하지만, 전역적 특징에서 시작하여 점점 더 세 부적인 지역적 특징을 점진적으로 사용한다는 점에서 차별성을 가진다.
3. 제안하는 방법
본 연구는 ONet [11]에서 제시한 3차원 형상 복원 시스템을 기반 시스템으로 사용한다. ONet은 3차원 적응형 격자(예, 팔진트리), 점유 네트워크(occupancy network), 그리고 메시 생성 모듈로 구 성된다. 최초의 격자는 낮은 해상도를 가지며, 격자의 각 포인트 를 점유 네트워크로 전달한다. 점유 네트워크는 이미지와 3차원 좌표(포인트)를 입력으로 받고, 해당 포인트가 물체 형상의 내부 (점유)일 확률을 출력한다. 격자 포인트 중 임계값 이상의 점유 확률을 가지면 포인트 주변의 복셀은 8분할 되며, 분할된 격자의 점들은 다시 점유 네트워크로 전달되어, 점유 여부가 결정된다. 목표 해상도에 도달할 때까지 위 과정이 반복되며, 목표 해상도 에 도달한 격자는 메시 생성 모듈로 전달된다. 메시 생성 모듈은 주어진 격자에 마칭큐브(marching cube) 알고리즘 [18]을 적용하 여 결과 메시를 생성한다.
본 연구는 ONet의 점유 네트워크 대비, 물체 형상의 세부를 정 확히 표현할 수 있는 점진적점유 예측 네트워크를 제안한다.
본 연구가 제안하는 점유 예측 네트워크는 입력 이미지 촬영에 사용된 카메라 정보를 알고 있는 경우를 대상으로 한다. 즉, 네트 워크의 입력은 이미지, 카메라 정보, 그리고 3차원 좌표(포인트) 이며, 출력은 해당 포인트 위치의 점유 여부(확률)다. 이미지로 부터의 얻은 정보(관측)를 x ∈ X , 주어진 포인트를 p ∈ ℝ3, 그 리고 카메라 정보를 c ∈ C라고 했을 때, 제안하는 네트워크가 표현하는 함수는 수식 1과같다.
Figure 2는 본 연구가 제안하는 점진적 점유 네트워크의 전체 구조를 보여준다. 제안하는 네트워크는 인코더, 지역 특징 추출 기, 디코더 블록들, 그리고 점유 추론 블록으로 구성되어 있다. 입력 이미지는 224 × 224 크기로 전처리되어 인코더의입력으로 들어간다. 인코더(encoder)는 합성곱 신경망(convolution neural network, CNN)을 사용하며, 입력 이미지에서 특징을 추출하는 역할을 한다(3.3장). 지역 특징 추출기(local feature extractor)는 카메라 정보와 포인트 위치 정보를 기반으로 이미지에서 해당 포인트 위치에 대응되는 이미지 특징인 지역적 특징(local feature)을 추출하는 역할을 한다(3.4장). 디코더(decoder) 블록들은 지역 특징들을 반영하여 포인트 특징(point feature)을 갱신한다 (3.5장). 디코더 네트워크는 총 다섯 개의 디코더 블록으로 구성 되어 있으며, 각 디코더 블록을 서로 다른 수준의 지역적 특징들 을 사용하여 포인트 특징을 점진적으로 갱신한다. 마지막 점유 추론 블록은 디코더 블록들을 거쳐 나온 포인트특징을입력으로 받아 점유 여부를 출력한다(3.6장).
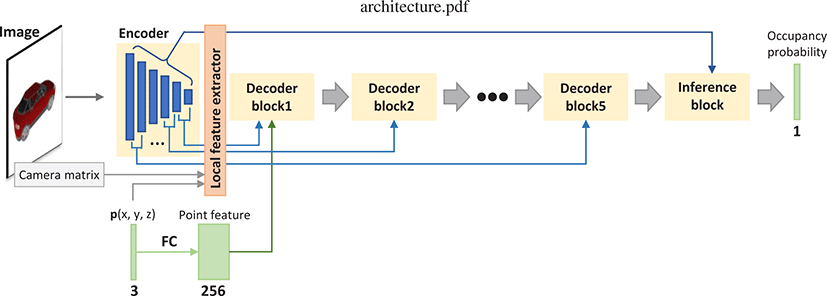
본 연구에서 사용하는 인코더 네트워크는 여섯 개의 합성곱 블록 (convolution block)으로 구성된 합성곱 신경망으로, Table 1은 각 합성곱 블록 및 네트워크 전체의 구조를 요약한 것이다. 각 합성 곱 층(Conv2D)은 활성 함수로 ReLU를 사용하였으며, Table 1에 는 간결성을 표기를 생략하였다. 각 합성곱 블록의 출력(Table 1 의 굵은 폰트)은 서로 다른 수용 영역을 가진 특징 맵으로, Conv. block1에서 Conv. block5로 진행할수록 수용영역이 넓어진다. 수 용 영역이 좁을수록 특징 맵의 각 원소는 이미지의 좁은 영역에 대한 지역적 정보를 담게 되며, 수용 영역이 넓어지면 각 원소가 이미지의 넓은 영역에 대한 정보를 담게 된다. 마지막 합성곱 블 록(Conv. block6)의 출력은이미지 전체에 대한 정보를 담고 있으 며, 본 연구는 이를 전역적 특징(global feature)로 정의한다. 또한, Conv. block1에서 Conv. block5의 특징맵을 지역적 특징맵(local feature map)으로 정의한다.
본 연구는 카메라의 정보를 이용하여 지역적 특징맵으로 부터 입력 포인트의 위치(x,y,z 좌표)에 대응하는 특징들을 추출하여 사용한다(3.4장).
지역적 특징맵으로 부터 포인트 위치에 대응하는 지역적 특징을 추출하기 위해 본 연구는, Wang 등 [4]의 연구에서 제안한 지각적 특징 풀링(perceptual feature pooling) 방법을 사용한다. Figure 3 은 포인트에 대응하는 지역 특징 추출 방법을 보여주며, 그 과정 은 다음과 같다. 우선, 이미지 상에서 포인트가 대응되는 위치를 얻기 위해 카메라 정보를 이용하여 3차원 포인트를 2차원 이미 지 평면으로 투영한다. 그리고 지역적 특징맵의 크기에 맞추기 위한 축소 연산을 수행하여, 특징맵 상에서 포인트의 대응 위치 를 얻는다. 마지막으로 특징맵에서 포인트에 대응하는 특징을 추 출한다. 특징맵 상의 포인트 위치는 정수가 아닐 수 있으며, 그 경우 포인트 주변 네 개 특징점의 특징값을 쌍-선형보간(bilinear interpolation)하여 계산한다.
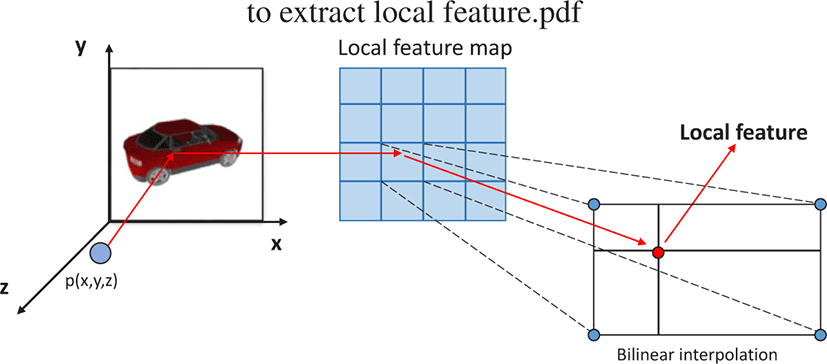
포인트에 대응하는 지역적 특징 추출은 모든 지역적 특징맵에 대해 적용되어 계산되며, 그렇게 추출된 지역적 특징들은 디코더 로 전달되어 점유 네트워크 표현력 향상을위해 사용된다(3.5장).
본 연구가 제안하는 점진적 점유 예측 네트워크의 디코더는 다 섯 개의 디코더 블록으로 구성되어 있으며, Figure 4는 디코더 블록의 구조를 보여준다. 디코더 블록의 입력은 256차원의 포 인트 특징과 지역적 특징 추출기를 통해 추출된 지역적 특징들 이다. 최초의 포인트 특징은 3차원의 입력 포인트를 완전 연결 계층(fully connected layer)을 통과 시켜 256차원으로 확대하여 생성한다(Figure 2). 디코더로 들어온 포인트 특징은 조건부 배 치 정규화(conditional batch normalization, CBN) 후, ReLU 활성 함수층과 합성곱 층(Conv1d)을 통과한다. 이 과정(CBN → ReLU → Conv1d)는 한차례 더 반복된다. 디코더 블록의 최초 입력 포인 트 특징은 잔차(residual)을 통해 전달되어, 위 과정을 거쳐 나온 포인트특징에 더해져서 디코더 블록의 최종 출력을 생성한다.
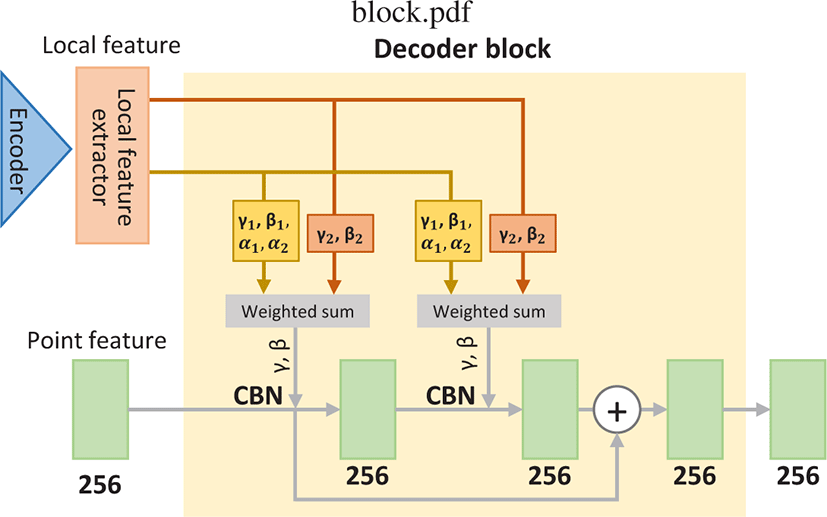
ONet [11]는 조건부 배치 정규화를 위한 매개변수 γ와 β 를 인 코더의 최종 출력(예, Conv. block6의 출력)을 통해 추론하고 사용 하였다. 그 결과, 물체의 전체적 형상은 잘 복원해내지만 세부적 인 모습까지는 잘잡아내지 못하는 한계를 보여주었다. 본 연구는 이러한한계를 극복하기 위해 조건부 배치 정규화 매개변수 추론 을위해 다양한 수준의 지역적 특징을 사용한다. 디코더 블록에는 두 개의 지역적 특징이 입력으로 들어오며, 각 블록으로 들어오 는 지역적 특징들은 서로 다르다. 첫 번째 디코더 블록(decoder block1)은 인코더의 가장 후미에 있는 합성곱 블록에서 출력된 특성맵(Conv. block5와 Conv. block6의 출력)에서 추출된 지역적 특징이입력으로 주어지며, 두 번째 디코더 블록(decoder block2) 은 인코더의 네 번째와 다섯 번째 지역적 특징맵(Conv. block4 와 Conv. block5의 출력)에서 추출된 지역적 특징을입력으로 받 는다. 동일한 규칙으로 마지막 디코더 블록까지의 지역적 특징 입력이 결정된다(Figure 2). 두 개의 지역적 특징은 조건부 배치 정규화의 매개변수를 추론하는데 사용되며, 그 과정은 다음과같 다. 우선, 각 지역적 특징을 통해 (γ1, β1)과 (γ2, β2)를 추론한다. 그리고 두 추론 결과를 가중치 합하여 최종γ와 β를 결정한다. 가중치 합을 위한 가중치 α1과 α2는 두 지역적 특징 중 더 넓은 수용영역을 가지는(인코더 뒤쪽의) 지역적 특징을 사용하여 추 론하도록 하였다. 매개변수 및 가중치를 추론하는 네트워크는 두 개 층으로 이루어진 합성곱 신경망을 사용하였으며, ReLU활성 함수를 사용하였다. 가중치 합을 위한 공식은 다음 수식 2과 3와 같다.
인코더의 전반부(예, Conv. block1)에서 생성된 지역적 특징맵 의 각 원소는 이미지의 국지적 영역에 대한 정보를 담고 있으며, 후반부(예, Conv. block6)로 갈수로 점점 이미지의 전체적 특징을 담게 된다. 따라서, 디코더 블록에 입력으로 들어오는 지역적 특 징에 따라 각 디코더 블록이 내포하는 표현력도 물체의 세부적 모습에서부터 물체의 전체적 형상까지 서로 달라진다. 본 연구는 물체의 전체적 형상을 추론하는 디코더 블록을 앞쪽에, 그리고 물체의 세부 형상을 추론하는 블록을 뒤쪽에 배치하는 구조를 선택하여, 네트워크가 물체의 전체적 형상을 먼저 추론하고 점진 적으로 세부적인 모습을 추론할 수 있도록 설계하였다(4.4장).
디코더에서 출력된 최종 포인트특징은 점유 추론 블록에 전달 되어, 포인트 위치에 대한 점유 확률 예측을위해 사용된다.
점유 추론 블록은 디코더에서 생성한 포인트특징과 인코더의 모 든 블록에서 추출된 지역적 특징(Conv. block6경우, 전역적 특징) 을 결합(concatenation)한 종합적 이미지 특징 벡터를 입력으로 받는다. 포인트 특징은 종합적 이미지 특징 벡터를 기반으로 한 조건부 배치 정규화를 거친 후, 완전 연결층으로 전달된다. 마지 막으로, 완전 연결층은 점유 확률을 출력한다.
본 연구는 디코더의 출력을 바로 완전 연결층으로 전달하는 경 우, 카메라의 시점에 대한 종속성이 강하게 작용한다는 것(예, 가 려진 부분의 형상 표현을 못함)을 경험적으로 발견하였다. 그리 고 종합적 이미지 특징 벡터의 사용이이런 현상을 완화해준다는 것을 확인하였다.
4. 구현 및 결과
본 연구는 제안하는 점진적 점유 네트워크의 성능을 확인하고 기존 연구들과의 비교를 위해, 3차원 형상 복원 연구를 위해 널 리 사용되는 ShapeNet [12] 데이터 세트를 사용하였다. 그 중, Choy 등 [6]과같은 13가지 종류에 대한 데이터 세트를 사용하여 학습 및 테스트를 진행하였다. 전체 데이터 샘플은 43,755개로 학습(training), 검증(validation), 테스트(test) 데이터로 각각 70%, 10%, 20%의 샘플을 사용하였다.
제안하는 모델은 PyTorch를 기반으로 구현하였으며, 최적화 방법(optimizer)으로는 Adam 알고리즘(learning rate = 0.0001, β1 = 0.9, β2 = 0.999,∈=10-8)을 사용하였다. 조건부 배치 정규화의 µ와 σ 운동량(momentum)은 0.1, ∈는 10-5를 사용하였다. 최종 메시 생성에는 Mescheder 등 [11]이 제안한 다중 해상도 등가면 추출(multiresolution isosurface extraction, MISE) 방법을 사용 하 였다. MISE를 위한 최초 해상도는 323이며 활성 복셀에 대한 최 대 해상도는 2563으로 ONet [11]과 동일하게 설정하였다.
본 연구는 기존 인공신경망 기반 3차원 복원 네트워크 중, 대표 적인음함수 표현 모델인 ONet [11]과 이미지에서 추출한 전역적 정보와 지역적 특징을 함께 사용하는 특징을 가지는 DISN [13] 와 성능을 비교한다. 두 모델 모두 저자가 github에 공개한 코드 를 사용하였으며, 제안하는 모델과 동일한 데이터 세트와 컴퓨팅 환경에서 학습을 진행하였다.
본 연구는 3차원 복원 연구에 널리 사용되는 세 가지 지표인, Chamfer distance, IoU, 그리고 법선 일관성(normal consistency) 지표를 사용하여 제안하는 네트워크의 성능을 검증하였다 [11].
Chamfer distance는 포인트 클라우드 사이의 유사도를 측정하 는 지표 중 하나로, 가장 가까운 점들 사이의 거리를 기준으로 사용한다. 따라서, 값이 낮을 수록 높은유사도를 의미한다. 본 연 구는 정답 메시와 네트워크를 통해 추론된 메시의유사도를 분석 하기 위해, 각 메시에서 10만 개의 포인트를 임의 샘플링(random sampling)하여 포인트 클라우드들을 만들고, Chamfer distance를 계산하였다.
IoU(Intersection over Union)는 두 메시 사이의 유사도를 측정 하는 지표로, 두 메시의 부피(volume)합 대비 두 메시가 겹치는 부분의 부피 비율을 계산하는 방법으로 유사도를 측정한다. 따라 서, IoU는 높을 수록 높은유사도를 의미한다.
법선 일관성(normal consistency)은 두 메시 표면 사이의 법선 유사도를 표현하는 점수로, 두 메시 사이의 고차원 유사도를 측정 하는 지표다 [12]. 따라서 법선 일관성은 높을 수록 높은유사도를 의미한다.
Table 2는 본 논문이 제안하는 점진적 점유 네트워크(Ours)와 두 가지 비교대상 모델인 ONet과 DISN의 테스트 데이터 세트에 대 한 Chamfer distance, IoU, normal consistency 점수다. 이미지의 전역적 특징과 지역적 특징을 함께 사용하는 DISN과 Ours가 모 든 지표에서 ONet보다 평균적으로 좋은 성능을 보여주는 것을 확인 할 수 있다. Figure 1와 Figure 5는 입력 이미지와 복원된 형상의 예를 보여주고 있으며, ONet에 대비하여 DISN과 Ours가 물체의 세부적 형상을 잘 표현하는 모습을 볼 수 있다. Figure 1 에서 총의 손잡이 부분, 의자 등받이의 구멍과 다리의 굴곡 등이 그 대표적인 예들이다. 이러한 결과는 이미지에서 지역적 정보 를 추출해서 사용하는 것이 물체의 세부적인 형상을 추론하는데 도움이 된다는 것을 보여주는 결과다.

DISN과 비교하여 Ours는 Chamfer distance와 IoU에서는 조금 좋은 성능을, 그리고 normal consistency에서는 조금 낮은 성능을 보이는 등 세 가지 평가지표에서 대등한 수준의 성능을 보여준 다. 하지만, 복원 결과물의 시각적 품질에서는 차이를 확인할 수 있다(Figure 1와 Figure 5). DISN은 형상 복원 과정에 물체의 얇은 부분(예, Figure 1에서 배의 돛, 총의 가늠쇠 및 총구)을 복원하는 데 실패하는 모습을 확인 할 수 있다. 본 연구가 제안하는 점진적 점유 네트워크는 DISN이 놓친 얇은 부분까지 잘 복원해 내는 모 습을 확인할 수 있다(Figure 1와 Figure 5). 이는 제안하는 점진적 점유 네트워크의 디코더 내 각 디코더 블록이 내포하는 표현력 이 물체의 전역적 특성과 세부적 특성을 모두 아우르고 있으며, 단계별로 포인트특징을 갱신함에 따라 얻을 수 있는 결과다(4.4 장).
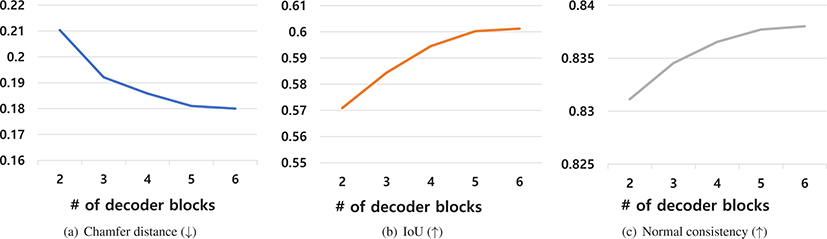
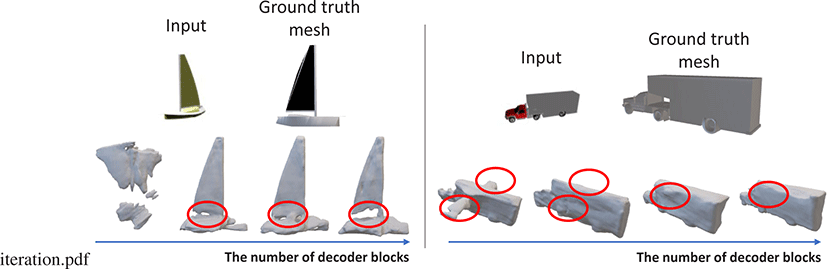
본 연구는 디코더에서서로 다른 수준의 지역적 특징을 활용하는 디코더 블록의 효과 확인 및 디코더 블록 수에 따라 성능 변화 를 분석하기 위해, 각 디코더 블록에서 나온 포인트 특징을 사용 하여 3차원 복원을 수행해 보았다. Figure 6는 각 디코더 블록의 출력을 사용하여 측정한 세 가지 지표에 대한 점수를 보여준다. 그래프에서 볼 수 있듯, 디코더 블록을 지나감에 따라 세 가지지 표 모두에서 점진적으로 성능이 향상됨을 확인 할 수 있었다. 본 연구는 또한, 인코더 블록의 수와 디코더 블록의 수를 더 늘려보 았지만, 일곱개 이상의 블록에서는 유의미한 성능 향상이 없음을 확인하였다. Figure 7은 배와 트럭 두 가지 샘플에 대해 디코더 블 록의 수 증가에 따른 복원 결과를 가시화 한 결과다. 배의 경우 초기 디코더 블록이 배의 전체적 윤곽을 잡아냈으며, 뒤쪽으로 갈수록 세부적인 모양이 점진적으로 개선되는 것을 확인 할 수 있다. 트럭의 경우도 초기에는 배와 비행기의 중간 모습을 표현 하다가, 후반으로 갈수록 트럭의 모습으로 세부 형상이잡혀 가는 것을 확인할 수 있다. 이러한 결과는 본 연구가 제안하는 디코더 내 디코더 블록들이 물체 형상을 전역적 모습에서 지역적 특징 표현으로 점진적으로 개선하고 있음을 확인할 수 있는 결과다.
본 연구는 제안하는 네트워크를 구성하는 주요 요소의 효과를 분석하기위해 각 요소를 배제하고 성능을 측정하는 삭마 연구를 진행하였다. 삭마 연구에 사용된 네트워크는 아래와 같다.
-
CBNconcat: 디코더 블록마다 다른 지역적 특징을 넣는 것 대신, 각 인코더 블록의 출력들을 모두 결합(concatenation) 해서 조건부 배치 정규화 조건으로 사용하는 네트워크다.
-
CBNsingle: 각 디코더 블록에서 하나의 지역적 특징만을 사 용해서 조건부 배치 정규화를 수행하는 네트워크로, 전역적 특징(Conv. block6의 출력)은 사용하지 않고 다섯 개 블록만 사용하였다.
| Chamfer distance | IoU | Normal consistency | |
|---|---|---|---|
| ONet | 0.215 | 0.571 | 0.834 |
| CBNconcat | 0.200 | 0.578 | 0.831 |
| CBNsingle | 0.198 | 0.582 | 0.832 |
| Ours | 0.180 | 0.601 | 0.838 |
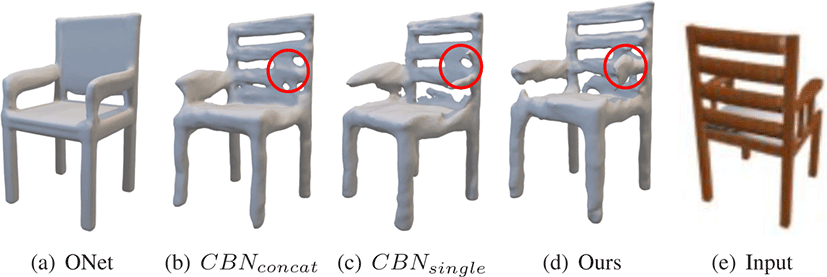
Table 3는 ONet과 Ours, 그리고 삭마 연구를 위해 사용된 두 개 모델의 테스트 세트에 대한 점수를 보여준다. Figure 8은 의 자 샘플에 대한 네 가지 모델의 복원 결과를 가시화 한 결과다. CBNconcat는다양한 수준의 지역적 특징과 전역적 특징을 함께 사용함으로서 ONet 대비 Chamfer distance와 IoU를 개선시키는 것을 확인 할 수 있다. CBNsingle 또한 ONet 대비 높은 성능을 보여주었으며, CBNconcat와 비교해서는 IoU에서는 좋은 모습 을, 그리고 Chafer distance와 normal consistency에서는 대등한 성능을 보여주었다. CBNsingle는 CBNconcat 보다 지역적 특징 에 더 집중을 함으로서 세부모습을 잘 잡아내서 이러한 결과가 나오는 것으로 판단된다. 두 변형 모두 normal consistency에서는 ONet 대비 낮은 성능을 보여주었다. 이는 두 모델이 지역적 형 상을 잘 잡아내는 반면, 지역적 특징 표현 과정에서 표면 표현의 매끄러움이 깨는 경우가 있어 normal consitency가 낮게 나오는 것으로 판단된다. 또한, Figure 8에서 볼 수 있듯, 사진에서 가려 진 부분에 대해 ONet은잘잡아내지만 CBNsingle와 CBNconcat 는 복원에 실패하는 모습을 확인 할 수 있다. 이는 지역적 특징에 집중함으로서 발생하는 단점이다. 하지만, 본 연구가 제안하는 점진적점유 네트워크는 전역적 특징과 지역적 특징을 적절히 결 합해서 사용함으로서, 모든 평가 지표에서 높은 성능을 달성함을 확인 할 수 있다.
5. 결론 및 향후 연구
본 논문은 물체의 전체적 형상 및 세부적 특징까지 복원 할 수 있는 표현력을 가진 음함수 표현 3차원 형상 복원 네트워크인 점 진적점유 네트워크 구조를 제안하였다. 제안하는 네트워크는 이 미지 전체의 정보를 담고 있는 전역적 특징만을 사용하는 기존의 점유 네트워크(ONet)와 달리, 수용영역의 크기에 따라 다양한 수 준의이미지 정보를 담고 있는단계별 지역적 특징맵을인코더를 통해 생성하고 사용한다. 그리고, 입력 포인트의 위치에 대응하 는 지역적 특징을 추출하여 디코더 블록 내 조건부 배치 정규화를 위한 조건으로 사용한다. 디코더 내 블록들은 서로 다른 수준의 지역적 특징을 조건으로 사용함으로서 각각의 디코더 블록이 서 로 다른 수준의 형상 표현력을 내포하도록 하였다. 그리고 포인트 특징이 디코더 블록들을 순차적으로 통과하며 특징을 갱신함으 로서 물체의 전역적 형상으로 부터 세부적 형상이 점진적으로 포 인트 특징에 반영되도록 하였다. 그 결과, 기존의 점유 네트워크 (ONet)보다다양한 검증지표에서 좋은 성능을 보였으며, 가시화 결과의 시각적 비교를 통해 ONet이 놓친 물체의 세부적인 형상 을 잘 복원해내는 것을 확인 할 수 있었다. 또한, 지역적 정보와 전역적 정보를 동시에 사용하는 기존 연구(DISN)와 검증 지표 상 대등한 성능을 달성하였으며, DISN이 복원에 실패한 물체의 얇은 부분이나 이미지에서 가려진 부분을 제안하는 네트워크가 잘 복원해 내는 결과를 확인할 수 있다. 이러한 결과는 본 연구가 제안하는 점진적 복원 네트워크의유용성을 검증하는 결과다.
본 연구의 점진적 점유 네트워크는 물체 세부 형상은 ONet보 다 잘 복원했지만, 전역적 형상의 표현력 및 완만한 표면의 표 현은 ONet대비 좋지 못한 모습을 보였다. 향후 연구에서는 세부 형상 성능은 유지하면서 전역적 형상의 표현력을 높일 수 있는 네트워크 구조를 연구하고자 한다. 또한, 가상 환경에서 만들어 진 데이터 세트를 넘어 실제 사진에 대한 제안하는 네트워크의 효능성을 탐구하고 실제 환경에서 활용할 수 있는 어플리케이션 을 개발하고자 한다.

