
1. 서론
현대 건축물에서 콘크리트 구조물은 가장 큰 비중을 차지하고 있지만, 그 재질 구조물이 가지고 있는 균열 또한 흔히 접할 수 있는 문제이다. 건축물의 시간이 지남에 따라 균열의 수와 폭 이 점차 다양하게 증가하고, 이는 결과적으로 구조물의 안정 성 및 내구성에 심각한 영향을 미친다. 따라서 콘크리트 구조 물의 안전을위해 정기적으로 균열을 검사하고 이에 상응하는 유지보수를 취하는 것이 매우 중요하다 [1, 2, 3]. 전통적인 균 열 검사는 주로 관련 도구를 사용하는 전문가의 직접 감지를 통해 진행된다. 이 탐지 방식은 노동력이 많이 소요될 뿐만 아 니라 시간이 많이 걸린다. 또한, 상황에 따라서 위험을 초래할 수도 있기 때문에안정성이 보장되지 않는다.
수동 검출의 문제점을 극복하고 효율적으로 안전한 균열 검 출을 제작하기 위해 영상처리기술에 주목하였다 [4]. 지난 수 십 년 동안 컴퓨터 비전 커뮤니티는 이미지의 자동 감지에 대 해 연구해 왔으며 임계값(Thresholding) [5, 6], 에지 감지(Edge detection) [7], 웨이블릿 변환(Wavelet transform) [8, 9] 및 머신 러닝 [10] 등이 있다. 이미지 임계값은 픽셀의 색상을 기반으 로 균열을 분할하여 이미지를 단순화시키는 방식이다. 에지 검출에 사용되는 미분 연산자에는 주로 로버츠(Robert) 연산 자, 소벨(Sobel) 연산자, 라플라스(Laplace) 연산자가 있다 [11]. 웨이블릿 변환의 아이디어는 이미지 신호를 나타내기 위해 웨 이블릿 함수 또는 기저 함수 셋을 사용한다. 머신러닝은 훈련 데이터셋에서 균열의 특징 벡터를 추출하고, 특정 알고리즘 을 결합하여 결과를 예측한다. 이러한 방식은 공학 분야에서 균열 감지 문제를 효과적으로 풀어내는 역할을 했다. 현재도 이 연구 분야는 균열의 불균일성, 표면 질감의 다양성, 배경의 복잡성으로 인해 여전히 연구가 활발히 진행되고 있다.
딥러닝은 머신러닝 알고리즘 연구의 새로운 기술로 문제를 분석하고 인간의 두뇌처럼 학습하기 위한 신경망이다. 특징 학습을 통해 네트워크의 각 계층은 이전 계층의 출력을 자체 입력으로 사용하고, 심층 비선형 네트워크(Deep nonlinear network)를 학습함으로써 추상적인 표현 모델로 변환한다. Zhang 등은 ConvNet을 이용하여 도로 균열 감지에 딥러닝 기반 프 레임워크를 활용하였다 [12]. 이때 노면 사진은 스마트폰으로 촬영했으며, 네트워크 모델은 Caffe 딥러닝 프레임워크로 구 축하였다. 이들은 SVM(Support vector machine)과 같은 기존 기계 학습 분류기와 비교하여 딥러닝의 효율성을입증하였다. Pauly 등은 ConvNet 깊이와 훈련 데이터셋, 그리고 테스트 데 이터셋 간의 위치 변화가 균열 탐지 정확도에 미치는 영향에 대해서 연구를 하였다 [13]. 결과적으로 네트워크 깊이를 늘리 면 네트워크 성능을 향상시킬 수 있지만 이미지 위치가 변경 되면 감지 정확도가 크게 감소한다는 것을 보여준다. Maeda 등은 대규모 도로 균열 데이터셋을 만들고, 각 사진에 도로 균열의 위치와 유형을 표시하는 방법을 제시하였다 [14]. 이 방법은 딥러닝 기반의 종단간(End-to-End) 물체 감지 방법을 사용하여 손상 감지 모델을 학습하였다. Xu 등은 자동 교량 균열 감지를 구현하기 위해 종단간 균열 감지 모델을 설계하 였다 [15]. 이외에 다양한 접근법들이 존재하지만, 실제 균열 패턴은 다양하고 복잡하기 때문에 데이터 구축을 위한 어려 움이 존재하며, 본 논문에서는 이를 해결하기 위해 ConvNet을 활용한 벡터 기반 데이터 증강 기법을 소개한다.
2. 관련 연구
지난 수십 년 동안 이미지 프로세싱 기술을 활용하여 균열을 감지하려는 연구가 꾸준히 진행되었다. 이 과정에서 균열을 감지할 뿐만 아니라 인식된 균열의 너비와 방향을 측정하는 것도 중요한 요소이다. 이미지 프로세싱 기반 접근법은 일반 적으로 미리 정의된 기울기 필터(Gradient filter)와 이진 분류 기(Binary classifier)를 사용하여 이미지 픽셀이 균열 영역의일 부인지 여부를 결정한다. Oliveira와 Correia는 어두운 영역을 구별하여 균열을 감지할 수 있음을 보여주었다 [16, 17]. 많은 연구자들이이미지에 노이즈 필터링을 사용하여 균열 감지를 효율적으로 처리할 수 있는 기법을 제안했다 [18, 19]. 또한, Morphology [20, 21, 22], Fuzzy [23, 24], Percolation 기법 [4, 25] 을 기반으로 균열 검사를 위한 다양한 영상처리 기법이 연구되 었다. 그러나 이러한 규칙 기반 이미지 처리의 정확도는 초점 거리, 촬영 환경의 영향, 촬영 품질 및 해상도에 따라 다른 결 과를 보여준다. 정확한 감지를 위해서는 입력 이미지에 따라 매번 새로운 필터 모델링이 필요하게 된다.
또 다른 접근법으로는 규칙 기반 균열 검사를 개선하기 위해 머신러닝이 활발하게 활용되고 있다. 많은 연구자들이 SVM [26, 27], Bayesian [28], 유전 알고리즘 [29], 의사결정트 리 [30]를 포함한 다양한 머신러닝 알고리즘을 균열 감지에 활용하였다. 그러나 머신러닝 기반 방법은 이미지 처리에 의 해 추출된 균열 특징에 의존할 수밖에 없는 정확도의 한계가 있지만, 딥러닝은 이러한 문제를 해결할 수 있음을 보여주었 다. Xu 등은 Boltzmann 이론을 사용하는 인공신경망을 활용하 여 제한된 훈련 샘플에도 불구하고 성공적으로 균열을 감지 할 수 있음을 보여주었다 [31]. Zhang 등은 4개의 레이어로 구 성된 ConvNet을 사용하여 도로 이미지에서 87%의 정확도로 균열을 찾았다 [12]. Chen 등과 Li 등은 99% 정확도로 이미지 에서 균열 패치를 추출할 수 있는 개선된 ConvNet을 제안하 였다 [32, 33]. 앞에서 언급한 인공신경망 기반 연구들은 균열 감지에 대한 충분한 잠재력을 보여주고 있지만, 인공신경망 학습을위한 균열 데이터 수집 및 데이터 증강 방법에 관한 연 구는 거의 진행되지 않았다.
공개적인 균열 데이터셋에는 Li와 Zhao가 공개한 데이터가 있 다 [33]. 이 데이터는 4160×3120 해상도의 균열 이미지를 스마 트폰으로 촬영한 데이터이다. 이것을 256×256 해상도로 자른 후, 균열 존재 여부에 따라 두 가지 범주로 분류하였다. 이 연구 에서는 데이터셋에 12,000개 이미지만 사용하였고, 균열 및 비 균열 이미지의 수는 동일하게 설정하였다. 또한, SDNET2018 데이터셋에서는 균열이있는 콘크리트 교량 이미지를 얻을 수 있다 [34] (Figure 1 참조).

네트워크 학습을위한 데이터 수집만큼 중요한 것은 데이터 증 강 기법이다. 사람이나 동물 등 일반적인 객체에 대한 감지 및 인식에서도 데이터 증강에 대한 중요성은 알려져 있으며, 여 러 자세 및 시점에 따른 객체 인식의 정확도를 높이려고 다양 한 방법들이 소개되었다. 그럼에도 불구하고 균열은일반적인 객체보다다양하고 불규칙한 패턴을 가지고 있기 때문에 현업 에서도 이 부분에 대한필요성을 지속적으로 요구하고 있다.
신경망 모델의 일반화 능력은 훈련 데이터셋의 수와 다양 성에 밀접한 관련이 있다. 실제 데이터의 개수는 매우 제한적 이기 때문에 이를 해결하기 위한 방법은 가상의 데이터를 만 들어 훈련셋에 추가하는 것이다 [35]. 이러한 방식은 네트워크 학습과정에서 과적합 문제를 효율적으로 극복할 수 있게 해 주며, 딥러닝의 다양한 분야에서 활용되고 있다. 컴퓨터 비전 분야에서 일반적으로 사용되는 데이터 증강 방법은 주로 영 상 처리 기술에 기반한 데이터 증강과 딥러닝에 기반한 데이 터 증강이 있다. 텐서플로우 2.0에서는 ImageDataGenerator라 는 데이터 증강 기능을 제공한다 : 데이터에 대한 반전(Flip), 이동(Shift), 회전(Rotation) 등의 기능을 제공.
Figure 2는 텐서플로우에서 제공하는 데이터 증강과정을 거 친 다양한 균열 이미지를 보여주고 있다. 하지만, 대부분 선 형 변환만을이용하기 때문에 복잡한 균열 데이터를 학습하기 에는 부족하다. 본 논문에서는 균열의 뼈대 패턴을 인식하고, 벡터 기반으로 데이터를 증강할 수 있는 새로운 방식을 제안 한다.

3. 제안하는 프레임워크
본 논문에서 제안하는 벡터 기반의 데이터 증강기법은 균열 데 이터 이미지로부터 뼈대를 추출하고, 이로부터 특징점인 코너 (Corner)를 찾아연결한 선분을 활용한다.
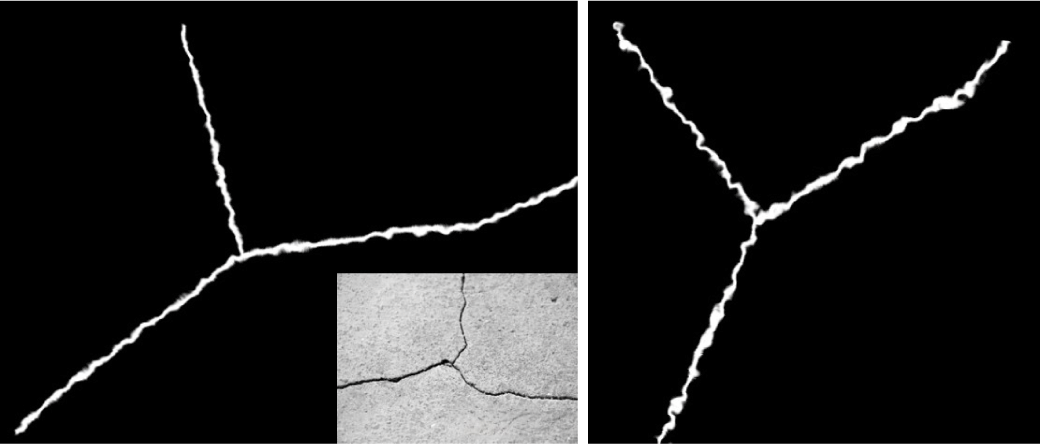
실제 균열 데이터의 95% 이상이 비균열(Noncrack)이라고 했을 때 균열이 존재하는 영역은 매우 작은 부분에 불과하다. 그러 므로 균열 선분에 데이터 변형을 가할 경우, 균열이 불규칙적 으로 끊어지는 문제가 발생한다 (Figure 3 참조). 균열 선분의 연결정보를 유지하기 위해 본 논문에서는 균열 이미지로부터 균열에 대한 뼈대를 추출한다. 이 과정을 위해 골격화(Skeletonization) 과정을 적용하며, 골격화는 균열 선분을 픽셀기반 에서 벡터 기반으로 변환하여 대상 물체의 두께를 얇은 벡터 선분으로 나타내는 방법이다. 이 과정을 거친 균열 이미지에 서 뼈대를 추출하고, 선분 너비를 조절하여 네트워크 학습 데 이터로 활용한다.

균열 데이터에서 기울기가 심하게 변하는 두 에지의 교차점 인 코너를 검출한다. 이 기법은 에지간의 변화율을 계산하여 양방향 기울기 변화가 심한 곳을 코너로 간주한다. 본 논문에 서는 해리스 코너 검출기법을 개선한 Shi-Tomashi 코너 감지 기법을 이용한다 [36]. 한 픽셀을 중심에 두고 마스크 윈도우 내에서 X축으로 u만큼, Y 축으로 v만큼 이동하며 윈도우 내 픽셀 값들의 차이에 대한 제곱 합을 계산한다. Equation 1에서 W (x, y)는 (x, y)위치에서의 가중치, I(x + u, y + v)는 이동된 위치에서의 값, I(x, y)는 이동 전 위치에서의 값을의미한다.
위 수식에 테일러 확장(Taylor expansion)을 적용하면 Equation 2를 얻을 수 있다.
Equation 3은 Equation 2를 행렬식으로 변경하여 정리한 최 종 수식이다. 이때, 행렬의 고유값이 최솟값보다 높으면 코너 로 간주하였으며, 이 과정은 SVD(Singular value decomposition) 기법을 통해 계산한다.
Figure 4는 그레이스케일 이미지에서 원하는 코너 개수, 기 울기 변화량, 코너 간최소 거리를 지정하여 추출된 N개의 코 너 집합이다.
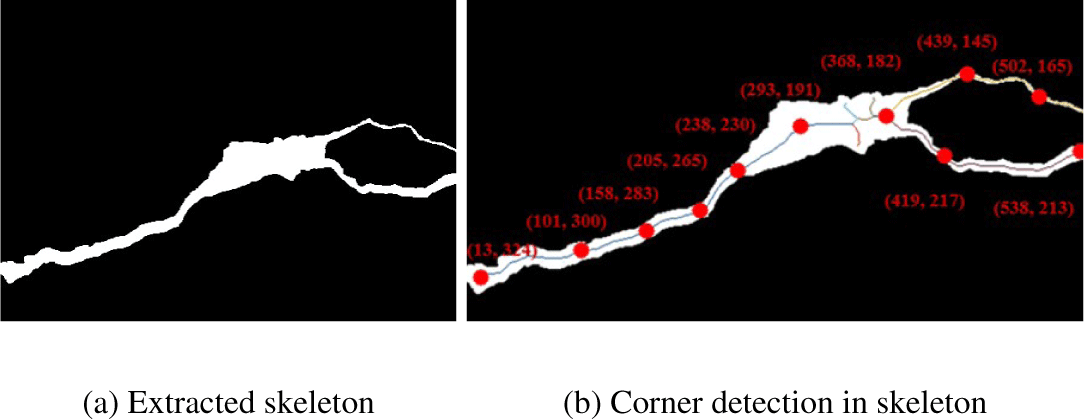
Figure 5는 검출된 코너들을 선분으로 연결한 결과이며, 향 후 이 데이터를 벡터 기반 증강 기법에 활용한다. Figure 3과 비교했을 때 끊어지는 균열 없이 안정적으로 균열 방향이 추 출된 것을잘 보여주고 있다.

이번 장에서는 미시적-거시적 관점에서 구현된 벡터 기반의 탄성왜곡 기법에 대해 설명한다. 미시적 관점에서는 표준편 차 σ와 변형 강도 α의 가중치를 조절하여 균열에 대한 심층적 인 변형을 계산한다. Figure 6은 앞에서 추출한 코너를 연결한 선분 중 하나의 선분을 확대한 결과이며, 그림에서도 보듯이 가중치에 따른 변형 정도를 쉽게 확인할 수 있다. Figure 6a는 앞에서 추출한 뼈대데이터이며, Figure 6b는 코너를 찾고 연결 한 이미지이다. Figure 6c는 균열 벡터의 한 선분에서 벡터기반 탄성변형을 적용한 결과이다. 거시적 관점의 탄성왜곡에서는 회전 각도와 아핀변환(Affine transformation)의 가중치를 조절 하여 균열의 표면 형태를 변형한다.
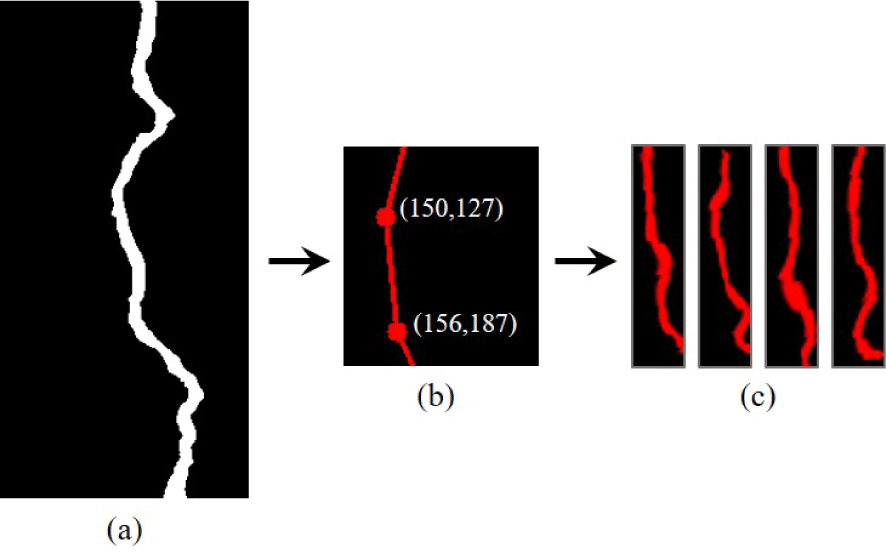
Figure 7에서는 벡터 기반 선분을 활용하여 미시적-거시적 관점의 탄성왜곡 기법을 적용한 결과이다. 직선 형태의 균열 에 비해 좀 더 다양한 균열 방향성을 표현할 수 있었으며, 전 통적인 픽셀기반 데이터 증강에서는 이러한 방향성을 제어할 수 없다. 난수에 의해 이 문제를 일시적으로 피해갈 수는 있지 만, 난수에 의한 변형은 원본 균열의 패턴을잃어버릴 수 있기 때문에 균열의 특징을 온전하게 표현하기에는 충분하지 않은 접근법이다.
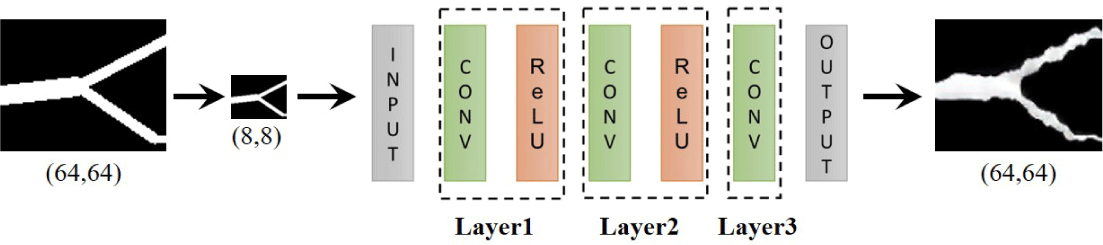
이번 장에서는 앞에서 제안한 벡터 기반 데이터 증강을 통해 균열 데이터를 디테일하게 모델링할 수 있는 ConvNet기반 네 트워크 방식에 대해서소개한다. ConvNet 학습을위해 골격화 균열 이미지 500장, 벡터 기반 선분 이미지 400장을 이용하였 으며, 이후 벡터 기반 데이터 증강 기법을 통해학습 데이터를 추가적으로 수집하였다. 본 논문에서는 앞에서 계산하여얻은 균열 이미지들을 기반으로 ConvNet을 진행하여 실제 균열과 유사한 패턴을 얻을 수 있는 특징 학습(Feature training)에 대 해 설명한다. 골격화 기법을 균열 이미지 바탕으로 네트워크 학습시켰을 때는 특징점에 대한 해상도가 복잡하여 실제 학 습 자체가 수렴하지 않았지만, 균열의 코너를 추출한 뒤 선분 으로 연결한 벡터 데이터를 활용하여 이 문제를 해결하였다.
Figure 8a는 균열 이미지로부터 추출된 뼈대 데이터이고, Figure 8b는 ConvNet 학습을 거쳐 생성된 결과이며 실제 균열 과 유사한 패턴을 보여준다. 탄성왜곡의 가중치가 큰 경우 발 생했던 노이즈는 원본 균열의 특징을 온전하게 표현하지 못했 으며, 본 논문의 방법은이러한 문제점을 완화하였다.

본 논문에서 사용한 잔차(Residual) 기반의 ConvNet 형태는 다음과 같다 (Figure 9 참조) : 벡터 기반의 학습 이미지를 활 용하여 26개의 레이어, 3배의 업샘플링, 잔차 이미지를 기반 으로 네트워크 학습을 하였을 때 최적의 결과를 얻을 수 있 었다. 업샘플링 배수가 커질수록 결과가 향상되었고, 잔차 이 미지를 사용하여 3채널 학습의 색상 문제를 해결하였다. 마 지막으로 균열 패턴의 디테일이 고려된 결과를 얻기 위해 벡 터 증강 과정을 거친 탄성왜곡 이미지를 입력 데이터로 사용 하였고, 이로부터 네트워크를 학습시켜 최종 결과를 얻었다. Figure 10a는 입력 이미지, Figure 10b는 ConvNet의 테스트 결과 이며, 학습 시간은 약 40분이 소요되었다. 앞에서 언급했듯이 입력 데이터의 크기는 8×8이며, 출력 데이터의 개수는 64×64 이고, 10,000 epoch를 사용했고, 최종적인 손실(Loss)은 0.1로 측정되었다.

4. 구현
본 논문에는 VGG19 인공신경망을 사용하여 균열 네트워크를 설계하였고, 이번 장에서는 VGG19 네트워크를 개발할 때의 상세 내역에 대해서 설명한다. VGGNet 모델은 크게 2가지 형 태로 구성되어있다 (VGG network와 Reconstruction). 예를 들 어, 입력 균열 데이터로 128×128을 갖는 3채널 이미지라고 했 을 때, 입력 x는다음과같다 : x(128, 128, 3).
VGG network에서 첫번째 ConvNet1은 앞에서설명했듯이 2 개의 ConvNet 레이어로 구성되어있으며, 이때 사용한 Weight 와 Bias 크기는 다음과 같고 (5×5×64,64), ConvNet1의 출력값 인, 너비(Width), 높이(Height), 깊이(Depth)는 각각 (64,64,64)이 다 (Figure 11 참조). 여기서 사용한 활성화 함수는 ReLU이다. ConvNet1의 출력값은 ConvNet2의입력으로 사용되며, 전체적 인 VGGNet 모델은 다음과같다 (Figure 11 참조). 이 그림에서 ConvNet 1-2라는 것은 ConvNet 1 과정에서 ConvNet 레이어를 2개 사용했다는 의미이고, 마찬가지로 ConvNet 5-4는 ConvNet 5 과정에서 ConvNet 레이어를 4개 사용한다는 의미이다.

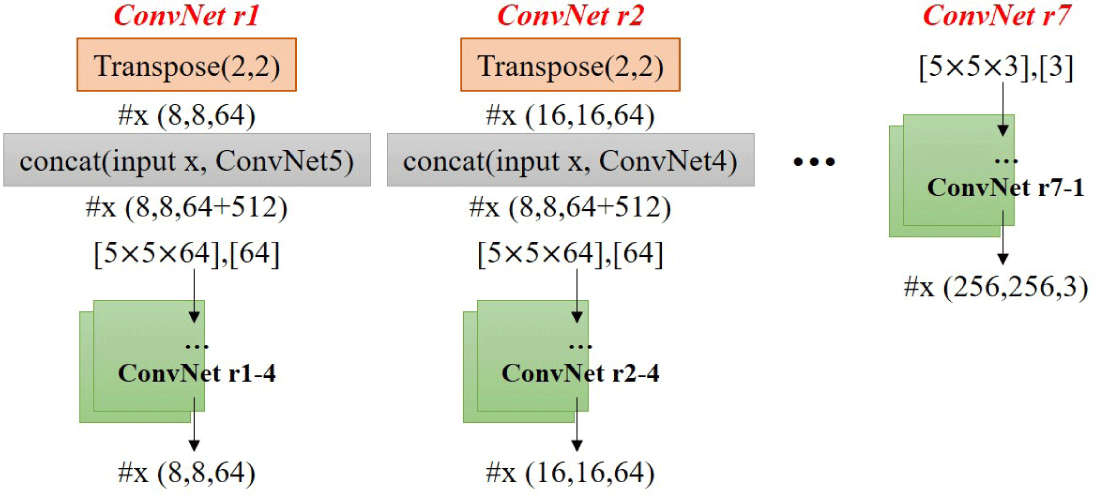
Reconstruction 단계에서는 VGG network의 출력값에 대한 전치 컨볼루션(Transposed convolution)을 통해 결과를 복원하 는 과정이다 (Figure 12 참조). ConvNet r1에서 ConvNet r7까지 의 세부 내역은 그림과 같이 설정하였다. 인공신경망의 입력 은 원본 데이터의 ½ 크기이며, 향후 잔차맵과 더해질 때 Reconstruction의 출력과 동일한 크기에서 더해진다. 이 네트워크 는 텐서플로우에서 구현했으며, 여기서 사용한 옵티마이저는 Adam(Adaptive moment estimation)이다.
5. 결과
본 연구의 결과들을 만들기 위해 실험한 환경은 Intel Core i7-7700K CPU, 32GB RAM, Geforce GTX 1080Ti GPU가 탑재된 컴퓨터를 이용하였다. 본 연구에서는 균열 데이터를 증강시 킬 수 있는 벡터 기반 증강기법을 제시하였고, 이를 ConvNet 으로 학습하여 효율적으로 데이터 증강이 가능한 아키텍처로 확장하였다. 본 논문에서는 제안한 방법의 효율성과 정확성을 실험하기 위해 3가지 시나리오를 통해 검증을 했다.
Figure 13a는 균열 이미지로부터 추출된 뼈대 데이터를 나 타내며, Figure 13b는 감지된 코너를 벡터 라인으로 이은 선분 이다. 균열 이미지로부터 추출된 선분은 잔가지 형태와 같이 얇은 균열들도 포함되어 있어서 실제로 거시적인 특징을 포 착하기 어렵고, 계산량만 커진다. 본 논문에서는 코너 감지를 통해 균열의 거시적은 특징을 효율적으로 찾았고, 이를 선분 으로 이음으로써 원본 균열의 방향을 유지할 수 있도록 데이 터를 수정하여 사용한다 (Figure 13b 참조).

Figure 14는 벡터 기반 탄성왜곡을이용하여 제작한 균열 데 이터이다. 입력 균열 이미지로부터 뼈대와 균열 벡터를 추출 하고, 벡터 기반 탄성왜곡을 결정하는 4가지 매개변수를 이 용하여 생성된 데이터 증강 결과이다. 거시적인 균열의 방향 뿐만 아니라, 미시적으로 표현되는 작은 균열의 지그재그한 패턴까지 다양하게 표현된 결과를 잘 보여주고 있다.
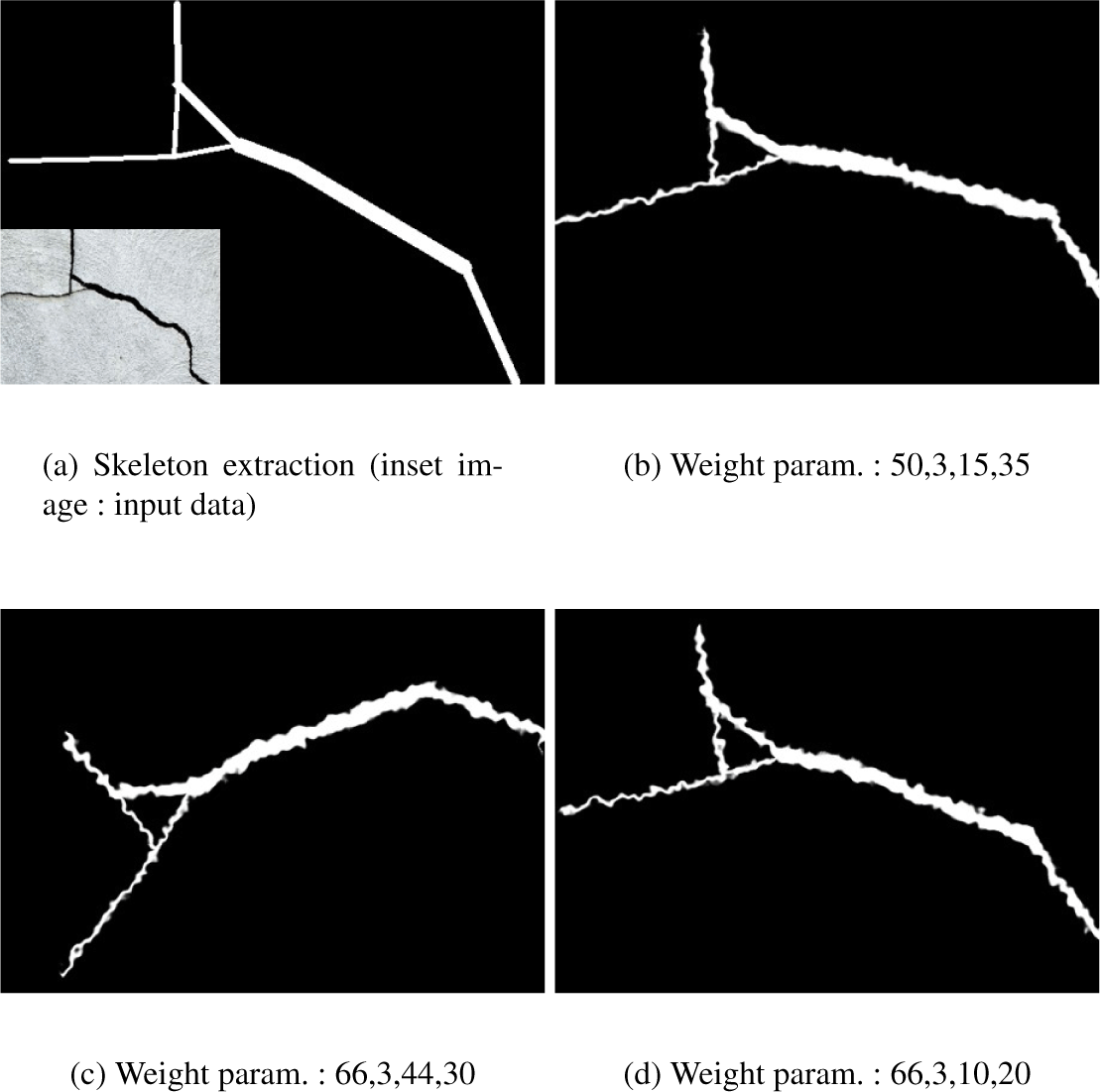
Figure 15는 본 논문에서 제안한 벡터 기반 데이터 균열 기법 을 ConvNet으로 학습하여 만들어진 결과이다. 앞에서 보여준 결과들과 마찬가지로 원본 균열의 특징은 유지한 채 균열 데 이터를 증강한 결과를 보여준다.

6. 결론 및 향후 연구
본 연구에서는 균열을 감지 할 때 필요한 데이터를 생성할 수 있는 벡터 기반 증강 기법과 이를 학습할 수 있는 ConvNet 기 법을 제안했다. 복잡한 패턴을 지닌 균열 이미지를 확보하기 위한 탄성왜곡 기반의 데이터 증강 기법을 이용해 네트워크 를 학습시키고, ConvNet을 활용해 실제 균열의 특징을 고려한 데이터를 생성하였다. 제안하는 방법은 콘크리트와 같은 특정 재질에서 발생하는 균열에 한정해 데이터를 생성할 수 있는 새로운 방식이다.
그럼에도 불구하고 몇 가지 한계점이 있다. Figure 14에서 보듯이 본 논문에서 제시한 균열 패턴은 실제 패턴과 비교했 을 때 진동(Oscillation)이 포함되는 것을 볼 수 있다. 앞에서 언 급했듯이 가중치를 조절함으로써 제어가가능하지만, 온전한 해결책은 아니다. 이러한 특징은 네트워크 학습과정에서 균열 의 두께(Thickness)를 고려하지 않아서 생기는 현상으로 파악 된다. 향후, 제안하는 기법을 균열 감지 네트워크에 적용하여 다양한 균열을 정확하게 감지하고 인지할 수 있는 네트워크 아키텍처를 연구할 것이다. 또한, 콘크리트 기반의 균열뿐만 아니라 다양한 재질에서 균열 데이터를 추출하고, 서로 다른 재질의 특징 맵들을 합쳐 좀 더 정확한 균열을 추출할 수 있도 록 데이터 증강 기법을 확장할 계획이다.
