
1. 서론
최근 영화나 드라마, 애니메이션 산업이 나날이 확장됨에 따라 구현을 위한 기술들의 필요성 역시 증가하고 있다. 특히 자연스러운 사람의 모션을 구현하는 것은 가장 기본이 되는 기술이다. 자연스러운 모션의 구현을 위해서는 해당 모션을 바라보는 사람들이 거부감이나 어색함을 느끼지 않아야 하며 구현하려는 모션과 실제 사람 동작 간에 유사성을 갖춰야 한다.
모델의 움직임을 구현하는 방법은 크게 두 가지 방법이 있다. 하나는 관절을 이용한 움직임인 Joint actuation이며 다른 하나는 근육을 이용한 움직임인 Muscle actuation이다. 관절을 이용한 방법인 Joint actuation은 모델링과 구현이 비교적 단순하다는 장점이 있으며, 대중적인 방법으로 사용된다. 이에 반해, 근육을 이용한 방법인 Muscle actuation은 Joint actuation보다 사람과 유사한 움직임을 구현하지만, 계산량이 많고 시간이 오래 걸린다는 단점이 있다. 이러한 단점으로 인해 muscle actuation은 joint actuation보다 대중적이지 않다.
또한, 사람의 움직임에 대한 종류는 걷기, 달리기, 점프하기 등 다양하다. 이러한 다양성을 근육을 이용하여 시뮬레이션 할 방법은 현재로서 풍부한 편이 아니다. 기존의 방법은 움직임의 종류마다 수동으로 컨트롤러를 설계하여 재현했지만, 이 역시 새로운 상황에서의 일반화는 다소 떨어진다.
이러한 수동으로 설계된 컨트롤러의 문제점을 해결하는 방법 중 하나는 강화학습을 통해 컨트롤러를 설계하는 것이다. 강화학습을 통해 설계된 컨트롤러는 모델이 다양하고 복잡한 모션을 수행할 수 있게 하며 이들은 모두 이전의 연구들을 통해 입증되었다. 해당 컨트롤러 중 비교적 높은 품질의 모션을 갖는 컨트롤러는 참조 모션을 기반으로 학습하는 컨트롤러다. 모델이 참조 모션을 보면서 따라 움직이도록 학습하는 것은 수동으로 설계된 물리 기반 컨트롤러보다 훨씬 자연스러운 움직임을 구현할 수 있으며, 더 나아가 복잡한 움직임 또한 어색함 없이 수행할 수 있게 된다.
본 논문은 근육을 중심으로 움직이는 물리 기반 모델이 참조 모션을 활용한 강화학습을 통해 이족보행을 구현하는 방법을 소개한다. 참조 모션 데이터와 물리 기반 근골격 모델의 데이터를 서로 비교하여 근골격 모델이 적합한 모션을 수행할 수 있도록 방향을 제시하고 이를 통해 관절 기반 모델보다 더 높은 품질의 애니메이션을 구현할 수 있게 됐다. 또한, 불필요한 계산을 줄여 근골격 모델의 단점인 높은 계산량과 소요 시간을 낮췄으며 결과적으로 높은 품질과 낮은 계산량으로 더욱 효율적인 모션을 수행할 수 있다.
2. 관련 연구
캐릭터 모델링 및 시뮬레이션은 오랫동안 연구된 분야이다. 최근 모델이 모션을 수행하도록 하는 컨트롤러에 대한 강화학습이 연구됨에 따라 캐릭터 애니메이션 및 물리 기반 시뮬레이션에 관한 관심이 증가하기 시작했다.
물리 기반 시뮬레이션에서 이족보행 모션을 제어하는 것은 오랫동안 컴퓨터 그래픽 분야와 로봇 공학 분야에서 연구됐다. 이족보행 모션에 대한 컨트롤러 중 일부는 궤적 및 모델의 균형 제어를 목적으로 한 피드백을 기반으로 한다[1, 2]. 다른 컨트롤러의 경우, 이러한 피드백 없이 모션 캡처 데이터를 사용하여 이족보행 모션을 수행한다[3].
이 중에 모션 캡처 데이터를 사용한 컨트롤러는 모델이 이족보행과 같은 단순한 동작부터 역동적인 회전 동작 혹은 발차기 등 복잡한 동작을 다른 컨트롤러보다 쉽게 수행할 수 있도록 한다. 모션 캡처를 사용한 컨트롤러 중 대표적인 연구는 Deepmimic[3]이다. 해당 연구는 모션 캡처를 통해 역동적인 동작을 수행하게끔 훈련시키며, 나아가 모델이 모션을 수행 중 방향을 바꾸는 리타겟팅도 수행하게끔 훈련시킨다. 결과적으로 모션 캡처를 사용하여 원하는 모션 수행 및 모델의 유연성과 일반성을 모두 갖춘다. 또한, 모델을 사람에게만 한정 짓지 않고 로봇, 공룡 등 다양한 모델을 사용하여 다양한 모션을 수행할 수 있다. 그러나 Deepmimic은 관절 기반 모델에게만 국한 되어있다는 단점이 있다.
컨트롤러만이 모션의 자연스러움을 결정짓는 것은 아니다. 어떤 모델을 사용하느냐에 따라서도 모션의 품질은 다르게 나타날 수 있다. 생체역학 연구진들은 근육과 힘줄을 이용해 모션을 수행하는 근골격 모델을 개발했다. 근골격 모델은 관절 기반 모델과 다르게 사람과 더 유사한 에너지 소모를 나타낸다. 이러한 특징을 이용하여 근골격 모델에 관한 연구는 다양하게 진행됐다[4, 5, 6]. 우리는 모션의 안정성 및 자연스러움을 위해 근골격 모델을 중심으로 연구를 수행했다.
근골격 모델의 가장 중요한 장점은 현실적인 관절 토크 한계를 제공한다는 것이다. 관절 기반 모델의 경우, 관절에 대한 토크 한계는 수동으로 설정하기 때문에 정적이고 실제 사람이 수행할 수 없는 토크를 초래할 수도 있다[7]. 이에 반해, 근골격 모델은 각 관절의 토크 한계가 관절의 위치와 속도에 따라 달라지며, 더 나아가 다른 관절의 위치와 속도에 따라서도 달라질 수 있게 된다. 결론적으로 관절 기반 모델보다 근골격 모델이 동적인 특성을 보이며 실제 사람과 같은 움직임을 구현할 수 있다는 장점이 있다.
그러나 근골격 모델을 사용할 때, 근육 활성화 역학을 고려해야 한다. 근골격 모델은 관절 기반 모델과 다르게 근육의 활성화 혹은 비활성화를 통해 관절을 움직인다. 관절을 움직이는 과정은 다음과 같다. 먼저 뇌에서 신경 흥분 (neural excitation)을 보내 근육을 활성화 혹은 비활성화를 결정한다. 이 신호를 받은 근육은 이완 및 수축을 통해 힘을 발생시키고 이 힘을 통해 근육에 붙어있는 관절을 움직이게 한다. 이러한 과정으로 인해, 신경 흥분 (neural excitation)과 근육이 발생하는 힘 사이의 시간 지연(일반적으로 5ms~100ms)이 생긴다[5, 6]. 기존 연구는 Quadratic Programming (QP)을 사용하여 근육의 활성화를 직접 최적화하므로 근육이 자체적으로 갖는 시간 지연은 모델링 되지 않는다[8]. 우리는 QP를 따로 사용하지 않고 신경 흥분 (neural excitation)을 policy의 출력으로 설정했다. 그로 인해, 우리는 신경 흥분 (neural excitation)을 직접 제어하며, 이는 근육 시뮬레이션을 통해 적절한 시간 지연과 함께 activation으로 변경되고 이에 따라 근육의 수축 및 이완 힘 (force)으로 변경된다.
3. 방법
우리는 근골격 모델을 활용하여 컨트롤러를 위한 훈련 데이터를 만든다. 이 훈련 데이터는 참조 모션 모방을 통해 생성된다. 참조 모션은 관절을 중심으로 모션을 나타내기 때문에 근골격 모델에 호환되도록 리타겟팅을 한 후, 근육의 메타볼릭 에너지 함수를 도입하여 근골격 모델에 대한 최적화를 이룬다.
학습을 위한 사람 모델로 우리는 Opensim이 제공하는 gait1956을 이용한 근골격 모델을 사용했다. 이 모델은 팔이 없는 몸통과 다리로 이루어졌으며, 각 부위는 19개의 자유도를 갖는 8개의 관절로 연결되어 있다. 또한 총 56개의 근육이 하체 부위에 붙어있다. 각 근육은 muscle tendon actuator (MTU)으로 이완 및 수축하며, 근육으로 각 관절의 DOF를 구동한다.
MTU에서 발생하는 힘은 Hilltype 모델을 기반으로 계산되며, 해당 모델은 Passive tendon element와 Passive element (PE) 그리고 Contractile element (CE)로 구성되어 있다. Passive tendon element는 PE, CE와 직렬로 연결되어 있으며 PE와 CE는 각각 병렬로 연결되어 있다. CE는 근육의 활성화 정도인 activation 에 따라 발생하는 active contraction force를 발생하고, PE는 근육 길이가 늘어남에 따라 발생하는 비선형 힘 passive fiber force를 발생시킨다.
이 두 가지 힘을 토대로 근육은 아래 식과 같은 힘을 제공한다.
은 각각 정규화 된 근섬유 길이와 속도를 의미하며, α은 muscle pennation angle을 의미한다. 은 근육의 max isometric force을 의미하며, 은 CE에 대한 force-length 와 force-velocity relationship을 의미한다. 그리고 fPE은 근육의 PE에 대한 힘을 의미한다. 이 변수들은 근육에 따라 값이 달라지며, 근육의 활성화 a ∈ [0,1]에 따라 근육의 힘을 조절하고 이를 통해 관절을 움직일 수 있다.
그러나 근육의 활성화 정도만을 조절한다고 모델이 원하는 모션을 수행한다는 보장은 없다. 같은 모션 이어도 근육이 얼만큼의 에너지를 사용하는지에 따라 결과가 달라질 수 있다. 그러므로 원하는 모션을 위해서 근육의 메타볼릭 에너지 소모비율을 최소화해야 한다[4]. 우리는 메타볼릭 에너지 소모 비율을 최소화함으로써 이족보행 참조 모션을 적절하게 따라할 수 있었다. 메타볼릭 에너지 소모에 대한 내용은 제3절에서 자세하게 다루겠다.
Deepmimic의 참조 모션에는 걷기, 달리기 등의 기초 모션부터 발차기, 회전 등 여러 가지 복잡하고 다양한 모션이 있다. 이 중에서 우리는 이족보행 모션[3]을 선택했다. 해당 데이터는 총 39개의 프레임으로 이뤄져 있으며 각 프레임은 관절의 좌표들로 이뤄진 좌표계로 형성됐다. 해당 좌표계는 선형 좌표계와 쿼터니언 (Quaternion)으로 이뤄져 있다. Deepmimic에서 사용하는 모델과 이 연구에서 사용하는 모델은 서로 다른 모델이다. 그러므로 먼저 Deepmimic의 모델에 맞춰진 39개의 프레임의 데이터들을 근골격 모델에 적용할 수 있게 리타겟팅을 수행한다. 리타겟팅을 통해 근골격 모델에 참조 모션을 입혀 특정 시간마다 모델이 특정 pose를 취하게끔 설정했다. 이렇게 설정한 결과를 토대로 근골격 모델의 관절마다 위치 및 속도를 얻게 되고 이를 참조 데이터로 사용했다.
결과적으로 근골격 모델은 참조 데이터를 통해 특정 시간에 관절의 위치와 속도를 얻기 위해 근육을 얼마나 활성화해야 하는지를 학습한다. 학습에 관한 내용은 다음 절에 구체적으로 다루겠다.
강화학습의 목표는 참조 모션을 근골격 모델이 어떻게 그리고 얼마나 잘 따라 하는지 다. 이를 위해 먼저 우리는 state를 근골격 모델의 각 관절의 위치 및 속도로 설정했다. 구체적으로 state는 root (일반적으로, 골반)에 대한 관절들의 상대적인 위치, 쿼터니언 (Quaternion) 형태의 회전 정도, 그리고 선형 및 각속도로 이뤄져 있다.
또한, 우리는 활성화 함수를 통해 신경 흥분 (neural excitation)을 action으로 설정했다. 활성화 함수 (activation function)는 시그모이드 함수를 사용하여 신경 흥분 (neural excitation)을 a ∈ [0,1]로 제한했다.
이러한 신경 흥분 (neural excitation)은 근육 시뮬레이션 시, 일정한 시간 지연과 함께 근육 활성화로 변경된다. 이렇게 근육 활성화를 직접 제어함으로써 근육은 적절한 지연시간과 함께 수축 및 이완을 하게 되고 그에 따른 관절이 움직여 근골격 모델의 특정 pose를 얻게 된다. 이 pose와 참조 모션의 target pose 간의 비교를 통해 근골격 모델이 적절한 동작을 취하고 있는지 확인한다.
근골격 모델의 pose가 target pose를 잘 따라가도록 안내해주는 방향성은 reward를 통해 결정된다. reward는 아래 식과 같이 설정했다.
reward는 총 4개로 분류했다. rp 는 pose reward, rv 는 velocity reward, reff 는 end-effector reward, rcom 은 center of mass reward를 의미한다. 해당 reward들은 특정 시간대의 근골격 모델의 pose와 참조 모션의 target pose간의 차이[3]로 설정된다.
앞서 언급했다시피 메타볼릭 에너지 소모 비율[4]은 근골격 모델이 참조 모션을 더 잘 따라 할 수 있는 학습 환경을 만든다. 우리는 근골격 모델의 현 pose에 대한 근육의 메타볼릭 에너지 소모비율을 최소화하기 위해 메타볼릭 에너지 소모 비율을 reward에 추가했다. 메타볼릭 에너지 소모비율은 방출되는 열과 근육이 하는 일의 합으로 나타난다[4].
여기서 Ȧ 은 방출되는 열량, Ṁ 은 근육이 유지하는 열량, Ṡ 은 근육이 수축하는 열량, 그리고 Ẇ 은 근육이 하는 일을 나타낸다. 각 열량은 일정 수준의 활성화가 근육에 입력되면 근육의 수축 및 이완을 통해 변환된 에너지를 토대로 계산했다.
강화학습 알고리즘은 이러한 reward를 토대로 action에 해당하는 신경 흥분 정도를 결정하고 근골격 모델의 현 state를 업데이트한다. 업데이트된 state는 참조 모션의 state와 비교하여 얼마나 잘 따라 하는지에 대한 reward를 산출해내고 산출된 reward를 이용하여 다시 action 결정 및 state를 업데이트한다. 이러한 과정을 반복하여 근골격 모델이 참조 모션을 따라 할 수 있도록 강화학습을 수행한다.
4. 실험 및 평가
우리는 Proximal Policy Optimization (PPO) 알고리즘을 사용하여 policy를 학습시켰다. 각 훈련은 에피소드별로 진행했으며, 에피소드가 시작할 때 초기 상태 s0 는 참조 모션을 통해 샘플링되고, step마다 policy에서 샘플링된 임의의 action을 통해 rollout을 생성한다. 이러한 과정은 에피소드마다 실행되며, 모델이 학습하는 동안 얻게 된 데이터 세트에서 미니 배치(Minibatch)가 샘플링되어 policy를 업데이트한다. 알고리즘에 사용된 변수들에 대한 값은 아래 표와 같다.
| Samples | 1024 |
|---|---|
| Minibatches | 256 |
| Discount factor (γ) | 0.995 |
| λ | 0.95 |
| Clipping threshold (ε) | 0.2 |
| Learning rate | 10-4 |
| Value loss | 0.5 |
| Entropy | 0.01 |
우리는 1024개의 Sample을 학습할 때마다 policy를 업데이트했다. 이때, 1024개의 Sample을 한 번에 학습하지 않고 256개의 미니 배치 (Minibatch)로 나눠 학습한다. 감가율 (discount factor, γ)은 γ = 0.995로 설정하여 미래의 reward 보다 현재의 reward의 가치를 높였다. 또한 TD(λ), GAB(λ)를 위해 λ = 0.95로 설정했다. Clipped surrogate loss를 위한 우도 비율 클리핑 임계값 (likelihood ratio clipping threshold)은 ϵ = 0.2, 학습률 (learning rate, η)은 한 번 학습할 때 얼만큼 학습해야 하는지, 학습량을 의미하며 우리는 적절한 값 10-4, 로 설정했다. 엔트로피 (entropy)는 학습 시 다음 action에 대한 탐색의 정도를 높이기 위해 0.01로 설정했다.
학습할 때 우리는 GPU 가속은 따로 하지 않고 8코어 CPU에서 수행했다. 또한, 총 2 × 107 개의 샘플링을 진행하였으며 학습시간은 대략 20시간이 걸렸다.
우리는 이족보행 참조 모션을 통해 근골격 모델의 이족보행을 학습시켰다. policy는 30Hz에서 실행됐고 모든 학습 네트워크는 Tensorflow를 사용하여 학습됐다. 근골격 모델은 policy로 업데이트된 랜덤한 action 값이 신경 흥분에 직접 입력되며 이는 시뮬레이션 시, 적절한 시간 지연과 함께 근육의 활성화 및 힘으로 변환된다. 이 힘을 이용하여 계산된 토크로 인해 근골격 모델의 관절을 움직인다.
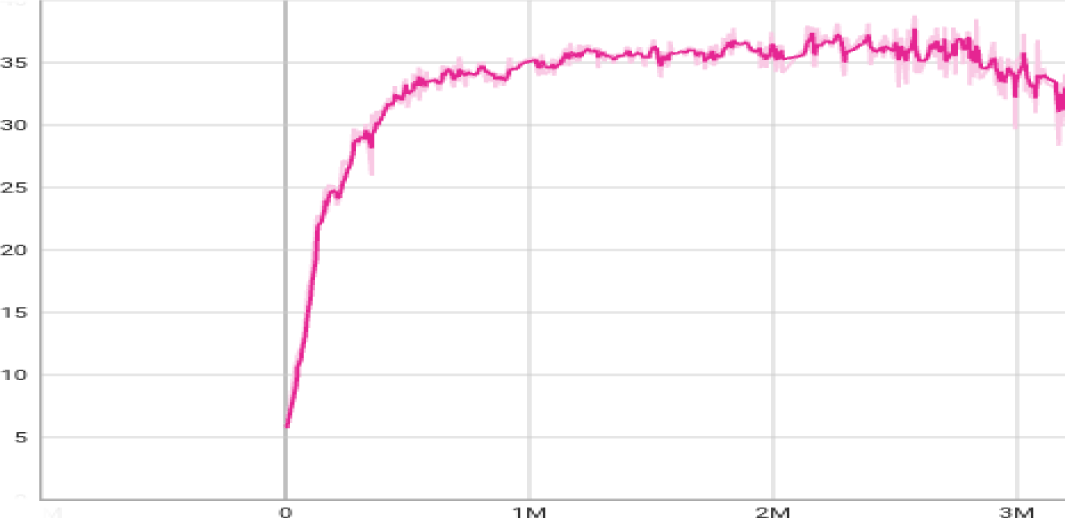
평균 reward는 episode당 최소 및 최대 reward의 평균값으로 설정했고 해당 결과는 여러 번의 실행에서 일관성을 유지했다. 해당 학습을 통한 근골격 모델의 이족보행은 관절 기반 모델을 사용한 Deepmimic [3]의 이족보행과 비교했을 때, 품질면에서 떨어지는 부분은 없었으며 오히려 근육을 사용했기 때문에 사람과 더 유사한 이족보행을 수행했다. 결과적으로, 우리는 QP를 따로 사용하지 않고 신경 흥분 (neural excitation)을 직접 제어하여 불필요한 계산을 줄였으며, 관절 기반 모델보다 더 높은 품질의 이족보행을 수행할 수 있다.
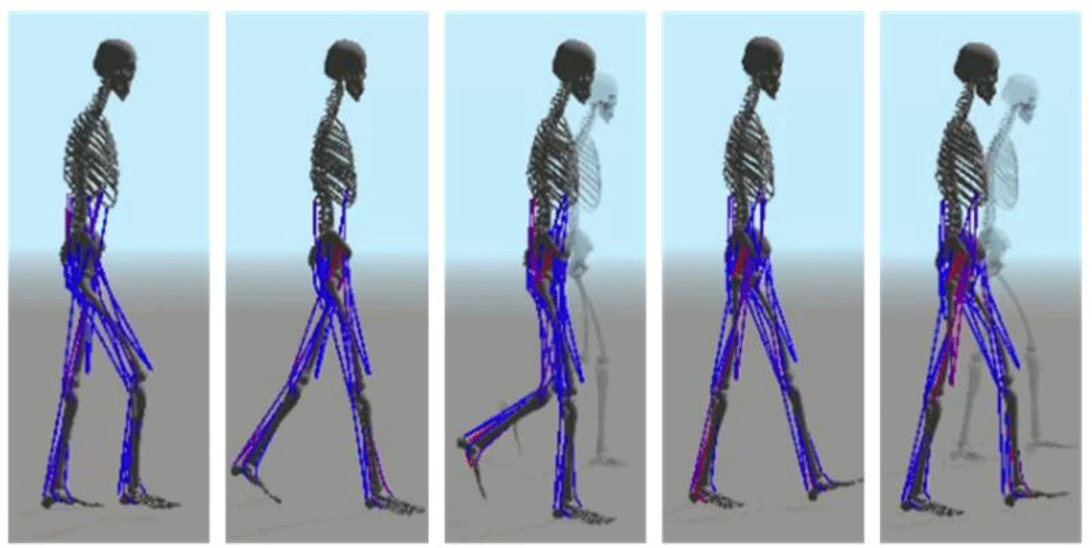
메타볼릭 에너지 소모 비율의 고려 유무는 동작의 품질을 결정짓는 중요한 요소다. 메타볼릭 에너지 소모 비율을 고려하지 않고 이족보행을 학습 시, 근골격 모델은 이족보행 참조 모션을 따라 하려고 노력하지만 자연스러운 이족보행 수행은 불가능했다. 우리는 메타볼릭 에너지에 대한 중요성을 강조하기 위해 메타볼릭 에너지의 유무에 대한 실험을 진행했다. 메타볼릭 에너지를 고려하지 않고 이족보행을 학습했을 때, 근골격 모델의 허리를 지탱하지 못하고 넘어지거나 한쪽 발을 들지 못하고 넘어지는 등 다양한 결과가 나타났다. 학습의 reward는 메타볼릭 에너지를 고려하지 않았기 때문에 메타볼릭 에너지를 고려한 학습의 reward보다 높지만, 결과는 좋지 않았다.
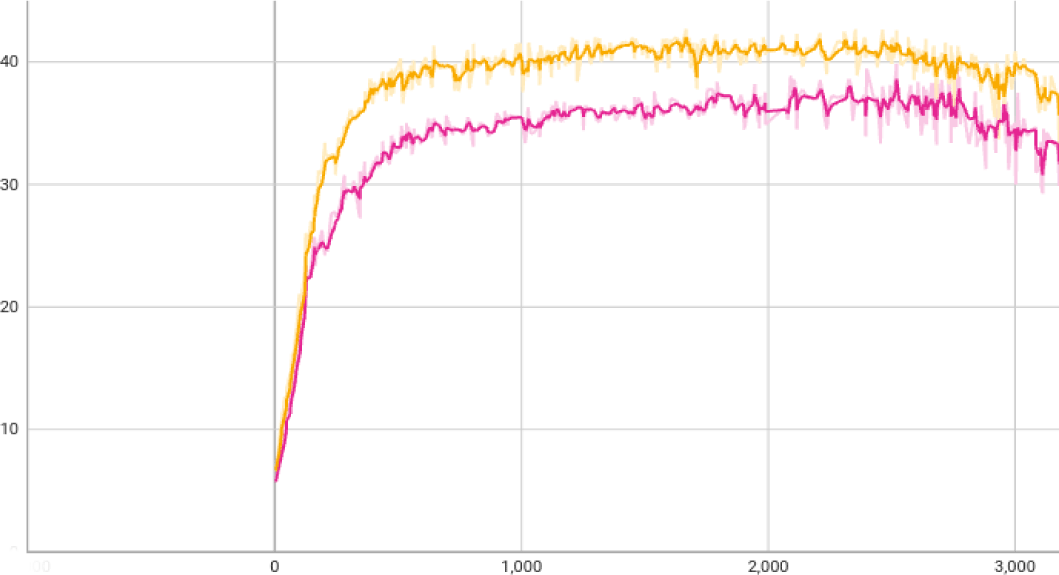
학습 환경 및 과정이 같더라도 메타볼릭 에너지의 여부에 따라 모델이 이족보행을 사람과 유사하게 할 수 있는지가 달라진다. 결과적으로 메타볼릭 에너지는 동작의 품질을 결정짓는 중요한 요소임을 알 수 있다. 근골격 모델은 관절 기반 모델과 다르게 근육의 활성화에 따라 근육의 힘이 결정되고 이 힘으로 인해 모델의 pose가 결정된다. 이 근육의 힘에 대한 에너지 즉, 메타볼릭 에너지를 고려해야 하며 이를 통해 현실감이 높은 이족보행 및 다른 원하는 모션을 생성할 수 있다.
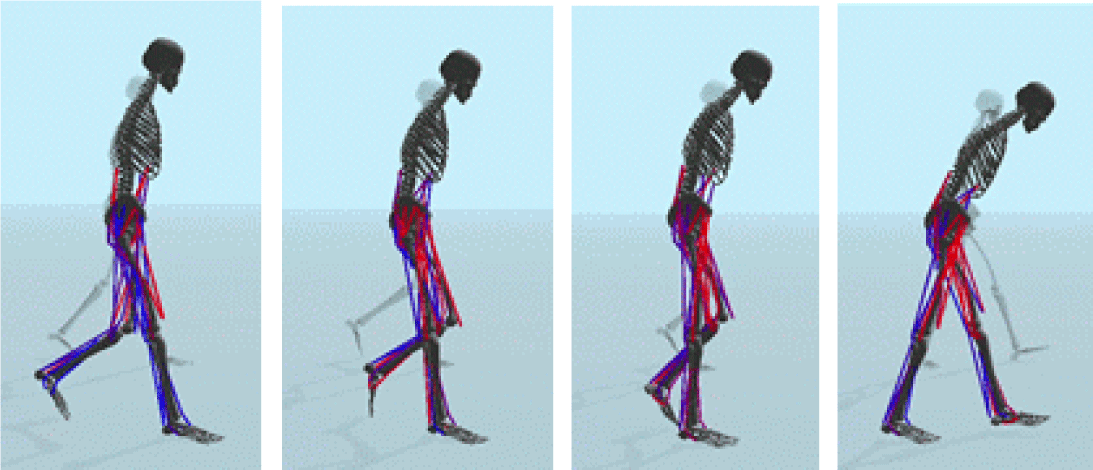
5. 결론 및 향후 계획
근골격 모델은 근육과 힘줄 등을 시뮬레이션 하여 사람과 유사한 움직임을 수행하는 반면 관절 기반 모델보다 계산량이 많아 계산 비용이 많이 들고 학습시간이 오래 걸린다. 이러한 문제를 해결하기 위해 이족보행 참조 모션을 사용하여 비교적 낮은 계산 비용으로 학습했다. 그 결과, 관절 기반 모델과 비교해도 큰 차이가 없이 사람과 유사한 움직임을 수행하는 결과가 탄생했다. 이는 근골격 모델에 대한 광범위한 도전을 수행할 수 있음을 알려준다.
그러나 우리의 실험은 향후 연구에서 해결해야 할 많은 문제점이 있다. 첫 번째로, 근골격 모델이 수행하는 모션은 이족보행에만 제한되어 있으며 다양하고 복잡한 모션에 대해서는 결과가 아직 미지수다. 우리의 방법은 하나의 참조 모션을 모방하는 방법 즉, 단일 클립만을 학습하기 때문에 하나의 참조 모션에 하나의 결과물이 나온다. 이족보행은 사람이 수행하는 단순한 모션들 중 하나이며 이를 토대로 달리기, 점프, 회전, 발차기 등 다양하고 복잡한 모션을 수행하는 것이 추후 계획이다. 이후, 다양한 단일 클립을 확장하여 멀티클립 개념을 도입해 근골격 모델이 여러 가지 모션들을 동시에 수행할 수 있게 한다. 이를 위해 여러 가지 단일 클립들에 대한 결과물에 가중치를 둬 한 번에 다양한 모션들을 자연스럽게 수행하는 것을 목표로 세운다.
우리는 이 실험이 근골격 모델의 잠재력을 열어줬다고 생각한다. 관절 기반 모델의 장점인 낮은 계산량 및 짧은 학습시간에 근골격 모델의 장점인 사람과 유사한 움직임을 더해 전보다 더욱 유용한 결과가 생긴 것은 부정할 수 없다. 우리는 근골격 모델이 더 어려운 모션들을 수행하고 더 나아가 모션에 대한 집중도를 환경으로 확장시켜 환경과 상호작용을 수행하도록 다양한 기술을 연구하기를 원한다. 우리는 이 실험을 토대로 다양한 제한점을 넘어 근골격 모델에 대한 효율적이고 다양한 캐릭터 애니메이션을 위해 연구할 것이다.

