
1. 서론
안와 뼈는 눈을 둘러싼 피라미드 형태의 뼈로 위쪽벽(roof), 하벽(floor), 내측벽(medial wall), 외측벽(lateral wall) 4개의 뼈로 구성되어 있다[1]. 안와 골절은 외부의 작은 충격으로도 쉽게 발생하며 대부분 얇은 벽 구조물로 구성된 내측벽이나 하벽에 발생한다. 두개악안면외과 수술에서 골절된 안와의 재건에 필요한 환자 맞춤형 인공 보형물 및 수술 가이드를 제작하고, 영상 유도(image-guided) 수술 계획에 적용하기 위해서는 안면부 CT 영상에서 자동화된 안와 뼈 분할이 필요하다[2]. 그러나 안와 뼈의 위쪽벽과 외측벽은 두껍고 500HU 이상 높은 밝기값의 피질골(cortical bone)로 이루어지고, 내측벽과 하벽은 매우 얇고 50~200HU 범위에 있는 상대적으로 낮은 밝기값의 얇은 뼈(thin bone)로 이루어져 있어 일관된 분할에 어려움이 있다. 또한 내측벽과 하벽의 경우 뼈의 두께가 얇아 부분용적효과(partial volume effect)로 주변 연조직(soft tissue)과 밝기값 구분이 어렵다[3]는 한계점이 있다.
CT 영상에서 딥 컨볼루션 신경망(DCNN: Deep Convolution Neural Network)을 사용[4, 5, 6, 7]하여 안와를 분할하는 연구는 다음과 같다. Lee[8, 9] 등은 안면부 CT 영상에서 다양한 범위의 밝기값을 갖는 안와 뼈의 특성을 고려하여 높은 밝기값을 갖는 피질골과 낮은 밝기값을 갖는 얇은 뼈를 나누어 각각 2D U-Net을 학습하여 안와 뼈를 분할하고 결과를 통합하는 방법을 제안하였다. An[10] 등은 안면부 CT 영상의 두꺼운 슬라이스 두께(slice thickness)로 인해 3D 모델링 시 발생할 수 있는 계단 현상(aliasing effect)을 줄이고, 얇은 뼈 영역의 부분용적효과를 고려하여 분할 성능을 개선하기 위해 CT 영상의 z축 해상도를 1mm로 향상시키고, 다양한 밝기값 범위를 갖는 피질골과 얇은 뼈를 구분하여 각각 3D U-Net을 통해 안와 뼈를 분할하고 OR 연산으로 결과를 합치는 방식을 제안하였다. Hamwood[11] 등은 CT 영상에서 안와 뼈의 외곽선을 자동 추출하기 위해 두 번의 2차원 U-Net을 통해 안와 영역 분할 및 안와 영역 내에서 안와 뼈 윤곽의 확률 맵을 생성한 후 그래프 검색(graph-search) 방법을 사용하여 외곽선 추출하는 방법을 제안하였다.
본 논문에서는 안면부 CT 영상에서 두께와 밝기값 범위가 다양한 안와 뼈의 자동 분할 성능을 향상시키기 위해 다중 스케일 계층 모듈과 듀얼 어텐션 모듈을 적용한 MSDA-Net(Multi-Scale Dual-Attention Network)을 제안한다. 이는 U-Net[12]을 기본 모델로 하여 인코더(encoder)에서 추출한 특징 맵(feature map)을 디코더(decoder)에 전달하는 스킵 연결(skip connection)에 다중 스케일 계층 모듈과 듀얼 어텐션 모듈을 함께 적용하여 다양한 두께를 갖는 안와 뼈의 특징과 배경에 비해 작은 영역을 차지하는 얇은 뼈의 영역에 집중한 특징을 디코더에 전달하여 분할 정확도를 개선한다. 이때, 다중 스케일 모듈은 3x3 크기의 필터를 여러 번 중첩함으로써 수용 필드(receptive field)의 크기를 확장하여 다양한 스케일에서 특징을 고려할 수 있고, 듀얼 어텐션 모듈에서는 채널 어텐션을 수행하여 유의미한 정보를 갖는 채널을 강조한 후 공간 어텐션을 수행하여 중요한 영역에 대해 강조함으로써 네트워크는 어텐션 모듈을 통해 강조한 특징에 대해 집중하여 학습을 할 수 있는 이점이 있다. 또한 실험을 통해 U-Net을 기본 모델로 하여 다중 스케일 계층 모듈의 효과와 싱글 어텐션과 듀얼 어텐션 효과를 제시한다.
2. 제안 방법
Figure 1는 제안 네트워크인 MSDA-Net의 구조를 나타낸다. 2차원 U-Net을 기본 모델로 하여 스킵 연결 부분에 다중 스케일 계층 모듈과 듀얼 어텐션 모듈을 추가한다. U-Net은 입력 영상의 채널의 수는 늘리고 차원은 축소해 나가면서 특징을 추출하는 인코더와 저차원의 특징만 이용하여 채널의 수를 줄이고 차원을 늘려나가며 고차원의 이미지를 복원하는 디코더가 U-자 형태로 생긴 네트워크이다. 이때 사용되는 스킵 연결은 저차원의 의미론적(semantic) 특징뿐만 아니라 고차원의 위치 및 형상 특징도 함께 이용해서 정확히 분할하기 위해 인코더에서 추출한 특징 맵을 대칭되는 디코더의 전달하는 역할을 한다. 인코더는 2개의 3x3 컨볼루션 연산과 배치 정규화(bacth normalization), ReLU 활성화 함수를 수행하고 2x2 최대 풀링을 사용하여 다운 샘플링(down-sampling)하는 과정을 반복하도록 구성된다. 디코더는 스킵 연결을 통해 전달받은 인코더의 특징 맵과 디코더의 하위 단계에서 2x2 업 컨볼루션을 통해 차원은 두 배로 늘리고 채널 수를 반으로 줄인 특징 맵을 서로 합친(concatenation) 후, 2개의 3x3 컨볼루션 연산과 배치 정규화(batch normalization), ReLU 활성화 함수를 수행하는 과정을 반복하도록 구성된다. 마지막으로, 1x1 컨볼루션 연산을 수행하여 입력 영상과 동일한 크기의 분할 결과를 얻는다.
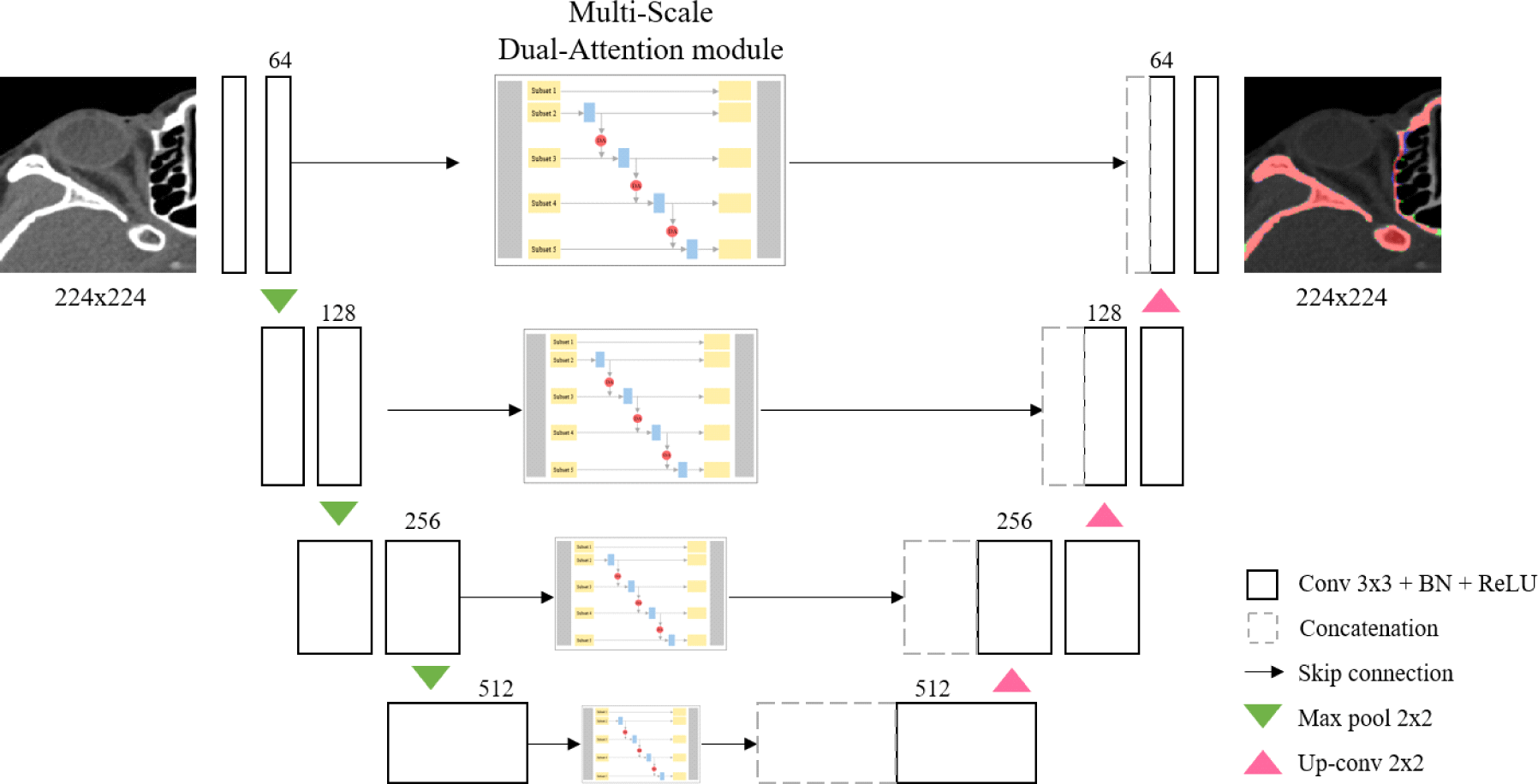
제안 네트워크의 훈련, 검증, 평가를 위해 사용하는 영상 데이터 전처리로 CT 영상 획득 시 서로 다른 프로토콜로 인해 발생한 영상 간 밝기값 차이를 줄이기 위해 밝기값 조정(intensity rescaling)과 화소 공간 정규화(pixel spacing normalization)를 수행한다. 밝기값 조정의 경우, 창 폭(window width) 600HU, 창 수준(window level) 100HU으로 밝기값 조정을 수행한다. 화소 공간 정규화의 경우, 사용 영상의 화소 공간 최솟값인 0.4x0.4mm2에 맞춰 정규화를 수행한다. 모든 입력 영상은 안구가 제일 큰 슬라이스에서 해부학적으로 좌측 안와 뼈와 맞닿는 부분부터 코뼈의 절반까지 포함하도록 정한 관심 영역(ROI, Region of Interest)에 맞게 크롭(crop)한다.
안면부 CT 영상에서 안와 뼈는 다양한 범위의 굵기로 구성되어 있어 일관된 분할 성능을 위해서는 다양한 스케일에서 특징을 고려할 필요가 있다. 본 절에서는 안와의 해부학적 구조와 특성을 고려하여 여러 스케일에서 특징을 학습할 수 있도록 스킵 연결을 통해 고차원의 특징 맵을 전달할 때 다중 스케일 계층 모듈을 적용하여 분할 성능을 개선한다.
다중 스케일 계층 모듈은 기존 잔차 블록(residual block)의 병목(bottleneck) 구조(Figure 2(a))에서 3x3 크기의 필터를 계층적 잔차 연결 구조로 변경하여 다중 스케일로 학습하는 구조를 제안한 Res2Net[13] 모듈(Figure 2(b))을 기반으로 구성된다. Figure 2(c)와 같이, 1x1 컨볼루션 연산 이후 특징 맵의 채널을 k개의 부분집합으로 분할하고, 각 부분집합은 이전 부분집합의 컨볼루션 연산 결과와 더해져서 3x3 컨볼루션 연산 및 듀얼 어텐션을 수행하게 된다. 모든 부분집합의 컨볼루션 연산 출력은 합쳐진 후 1x1 컨볼루션 연산을 수행하고, 최종 출력은 디코더에 전달된다.
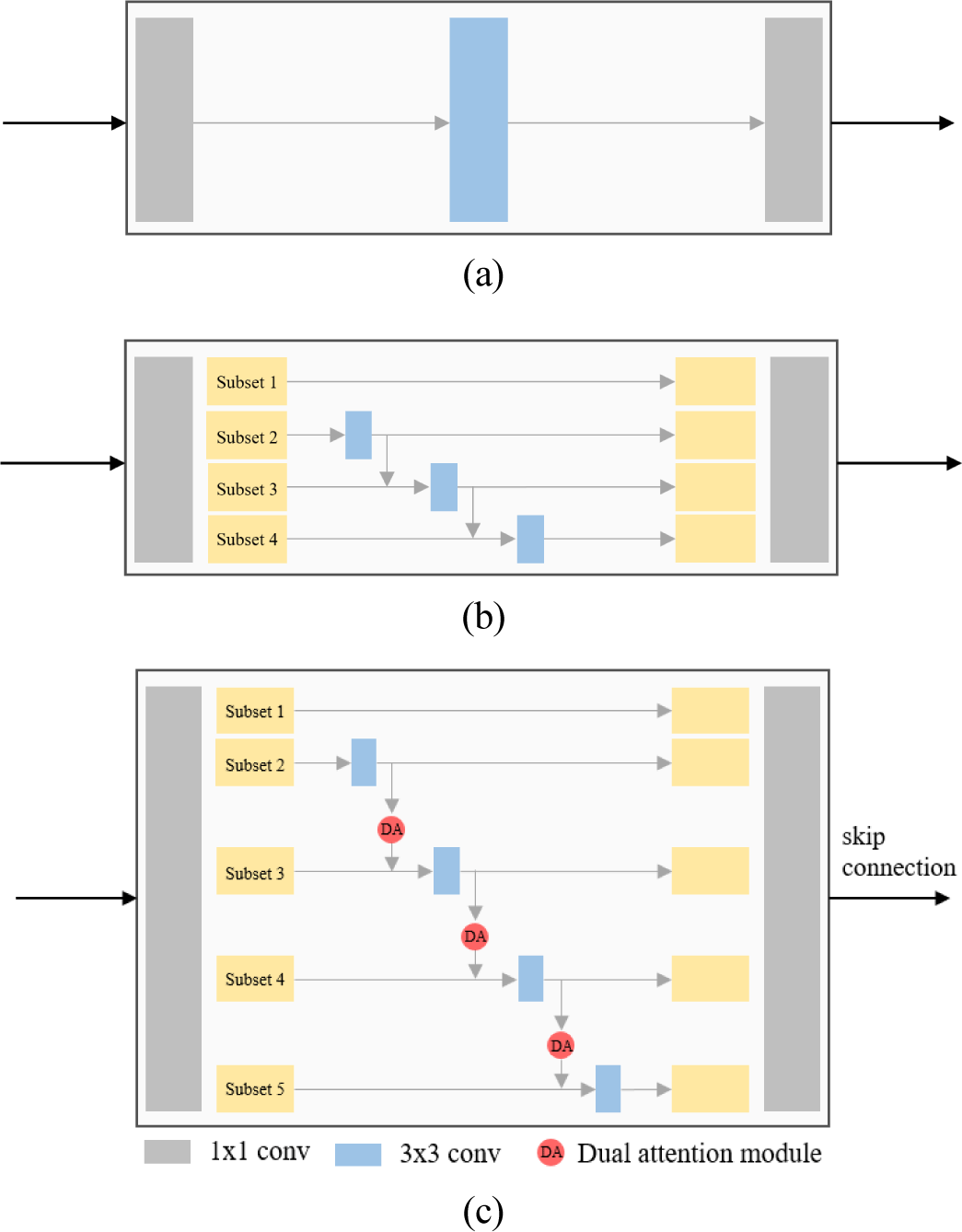
다중 스케일 계층 모듈에서는 특징 맵의 채널을 분할하여 3x3 컨볼루션 연산 및 듀얼 어텐션을 반복해서 누적 수행하므로 다양한 크기의 수용 필드에서 특징 추출이 가능하다.
안면부 CT 영상에서 피질골에 비해 낮은 밝기값을 가지는 얇은 뼈는 주변 구조물과 밝기값이 유사하고 화소 수가 적어 구분이 어렵다는 한계를 가진다. 본 절에서는 얇은 뼈 영역에서 유의미한 특성을 가질 가능성이 높은 채널과 영역에 집중할 수 있도록 듀얼 어텐션 모듈을 적용하여 얇은 뼈 영역의 분할 성능을 개선한다.
듀얼 어텐션 모듈은 다중 스케일 계층 모듈의 두번째 부분집합부터 3x3 컨볼루션 연산 이후 출력된 특징 맵에 적용되며 Figure 3과 같이 채널 어텐션과 공간 어텐션 모듈이 순차적으로 수행하는 CBAM[14]을 적용한다. CBAM은 채널 간의 상호작용을 고려하는 채널 어텐션과 유의미한 정보를 포함하는 화소의 공간 정보를 추출하는 공간 어텐션을 순차적으로 수행하는 특징을 갖는 어텐션 기법이다. 채널 어텐션은 전역 최대 풀링(global max pooling) 및 전역 평균 풀링(global average pooling)을 병렬적으로 수행하고, 공유 MLP에 통과시킨 후 시그모이드 함수를 거쳐 채널 별 가중치를 계산한다. 공간 어텐션은 전역 최대 풀링과 전역 평균 풀링을 각각 수행한 특징 맵을 합치고, 컨볼루션 연산과 시그모이드 함수를 거쳐 공간적인 위치의 중요도를 계산한다. 각 어텐션의 출력은 특징 맵과 원소 곱(element-wise multiplication)된다.
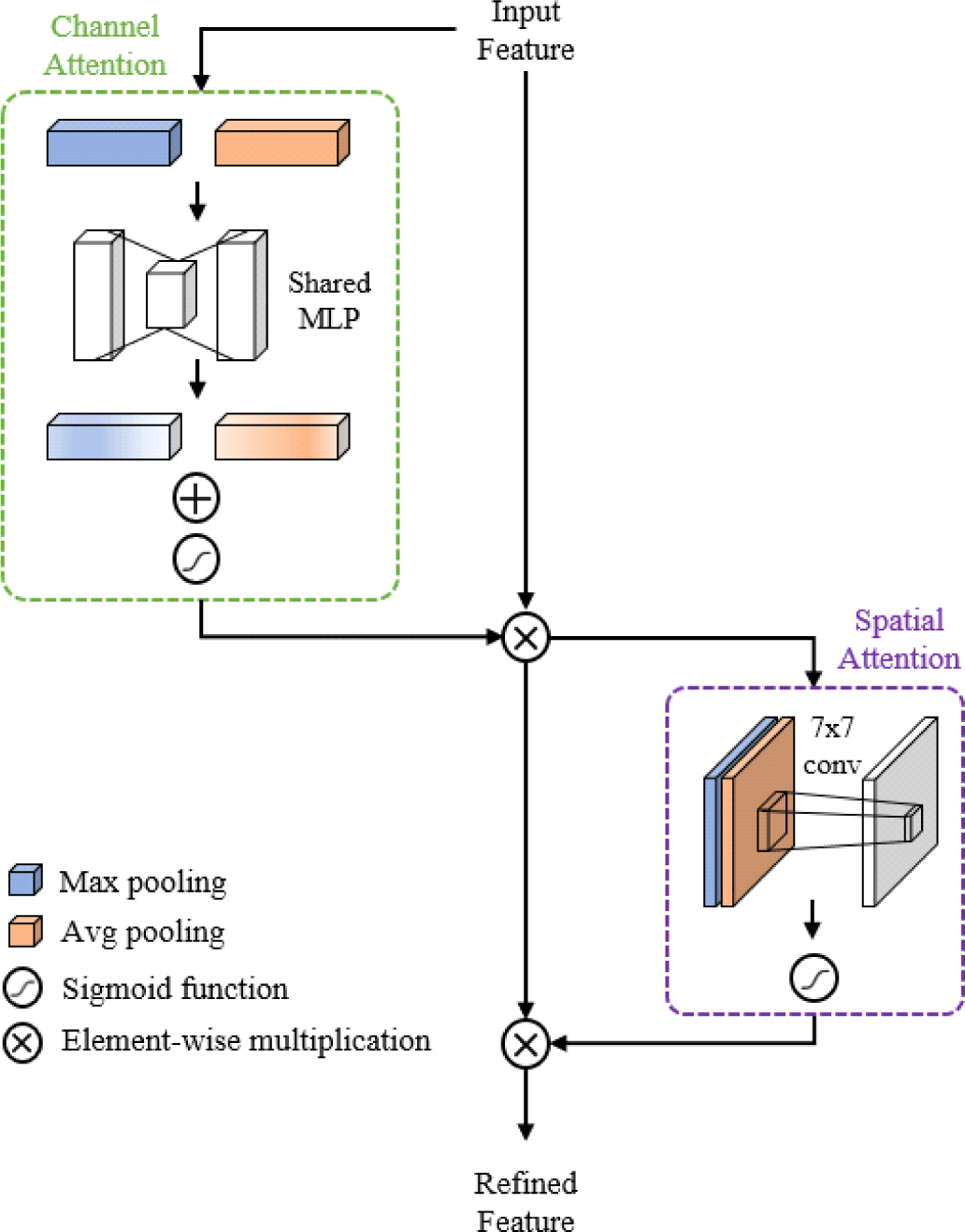
다중 스케일 계층 모듈에 듀얼 어텐션 모듈을 추가함으로써 주의 집중할 특징을 다음 부분집합이나 디코더에 전달할 수 있고, 주변 구조물들에 비해 안와의 얇은 뼈 영역이 갖는 특징의 구별 능력을 높일 수 있다.
3. 실험 및 결과
실험 데이터로는 연세대학교 세브란스병원 임상 시험 위원회의 승인을 받은 총 355명의 안면부 CT 영상을 사용하였다. CT 영상은 GE MEDICAL SYSTEMS의 Revolution EVO, Revolution CT, SIEMENS의 Sensation 64, SOMATOM Definition Flash, Definition AS+, Philips의 Brilliance iCT 256을 포함한 6개의 기기를 이용하여 촬영되었으며, CT 프로토콜은 관전압(kVp) 100, 관전류(mAs) 100~300, 재구성 커널은 GE MEDICAL SYSTEMS의 STANDARD, ULTRA 커널, SIEMENS의 H30f, H31f, H31s, H40s 커널, 그리고 Philips의 UB 커널로 구성되었다. 각 CT 영상은 해상도 512x512, 화소 크기 0.4~0.619mm2, 슬라이스 간격 1mm, 227~378장의 횡단면 영상으로 이루어져 있다.
모든 영상은 2명의 임상의에 의해 안와 뼈 수동 분할이 수행되었고 15년 이상의 숙련된 신경외과 전문의 1명이 검토 및 수정하였고 이는 제안 방법의 학습, 평가 및 결과 분석에 활용되었다. 제안 방법의 네트워크 학습 및 평가를 위해 전체 355개 데이터(15,823장)에서 228개 데이터(10,208장)를 학습 데이터, 56개 데이터(2,485장)를 검증 데이터, 71개 데이터(3,130장)를 평가 데이터로 사용하여 홀드 아웃(Hold-out) 교차 검증 방식을 수행하였다. 학습을 위한 하이퍼파라미터는 다음과 같이 설정하였다. 배치(batch) 크기는 7, 학습률(learning rate)은 1e-4, 이진 교차 엔트로피(BCE, Binary Cross Entropy)와 다이스 유사계수(DSC, Dice similarity coefficient)를 함께 사용한 손실함수와 Adam 옵티마이저를 사용하였으며, 에폭(epoch)은 500으로 지정하였지만, 일정 에폭(patience) 20 동안 검증 손실이 최솟값보다 줄어들지 않으면 학습을 조기 종료(early stopping)하도록 설정하였다. 전체 실험은 Windows 10 (64-bit) 운영체제에 NVIDIA GeForce RTX3080 그래픽 카드를 장착한 PC와 Ubuntu 20.04 LTS 운영체제에 NVIDIA RTX 3090 그래픽 카드를 4개 장착한 서버에서 CUDA 11.4 버전의 GPU 환경에서 파이썬(python) 3.6 및 파이토치(pytorch) 1.9 라이브러리를 사용해 진행되었다.
제안 방법의 성능은 정량적 성능 평가와 정성적 성능 평가를 통해 분석하였고 2D U-Net을 기본 모델로 하여, 다중 스케일 계층 모듈과 듀얼 어텐션 모듈의 효과를 분석하였다. 추가적으로 동일 데이터를 사용한 관련 연구와의 성능 평가 결과도 함께 분석하였다. 정량적 평가에서는 정밀도(Precision), 재현율(Recall) 및 다이스 유사계수를 통해 제안 방법의 분할 성능을 제시하였다. 이때, 성능평가를 위한 영역은 전역적 영역과 내측 및 하벽의 지역적 영역으로 지정하였다. 전역적 영역의 경우, 수동 분할된 안와 뼈 분할 마스크를 최대로 포함하는 영역으로 설정하였다. 안와 내측벽과 하벽의 지역적 영역의 경우, 안와 내측벽과 안와 하벽을 충분히 포함할 수 있도록 수동 지정하였다. 정성적 평가에서는 제안 방법을 적용하여 얻은 안와 뼈 분할 결과 영상의 육안 평가를 수행하였다.
Table 1은 평가 영역별 안와 뼈 분할 성능을 나타낸다. 안와 내측벽 및 하벽의 지역적 평가 영역에서 유의미한 채널과 화소 위치를 모두 강조할 수 있도록 채널 어텐션과 공간 어텐션을 순차적으로 사용했을 때 과소 분할 문제가 보완되어서 재현율 성능이 U-Net에 비해 1.91%, 1.65% 향상되었다. 전역적 평가 영역에서는 재현율 측면에서 제안 방법이 가장 우수한 성능을 보였고, 다이스 유사계수 측면에서는 다중 스케일 계층 모듈에 듀얼 어텐션 또는 채널 어텐션을 사용한 경우 92%로 우수한 성능을 보였다. 정밀도는 자동 분할된 영역 내에서 TP(True Positive) 영역의 비율로 계산되므로 과소 분할(under segmentation)되는 경우 성능이 가장 좋게 나오는 경향이 있어, 세 영역 모두에서 U-Net이 가장 높은 성능을 보였다. 또한, U-Net과 제안 방법의 모델 파라미터 크기는 큰 차이가 나지 않지만, 세 가지 평가 영역의 재현율, 다이스 유사계수 측면에서 성능 향상을 보였다.
Figure 4는 영역별 안와 뼈 분할을 정성적으로 평가한 결과를 나타낸다. 세 영역 모두 U-Net을 사용한 경우보다 제안 방법의 분할 결과가 우수함을 나타낸다. 수직 일자 구조의 안와 내측벽은 얇은 뼈의 밝기값 및 굵기 특성으로 인해 U-Net 분할 결과는 중간 끊김으로 인한 과소 분할이 발생하지만, 제안 방법의 분할 결과는 일관되게 잘 분할되었다. 특히, 수평적으로 완만한 경사 구조의 안와 하벽에서는 영상 슬라이스마다 뼈 구조의 변화가 큼에도 불구하고 제안 방법의 분할 결과가 U-Net, 다중 스케일에 공간 어텐션 또는 채널 어텐션만 사용한 경우보다 얇은 뼈 영역이 끊김 없이 잘 분할되었다.
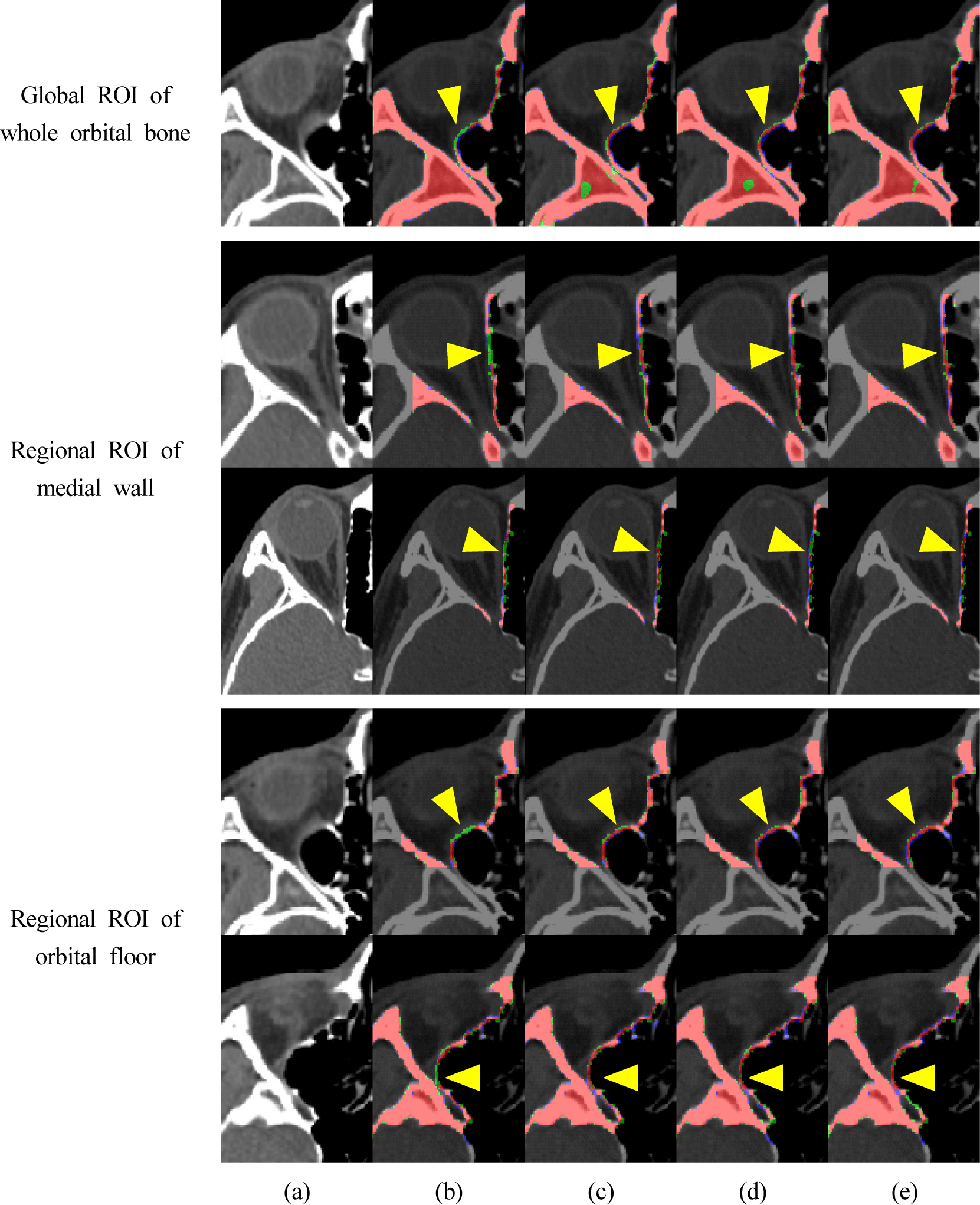
Table 2는 동일한 병원에서 수집된 안와 데이터셋을 사용하여 안와 뼈 분할을 수행한 관련 연구와의 분할 성능 비교 결과이다. 제안 방법의 경우, 기존 관련 연구[4-6]과 비교하여 안와 내측벽 및 하벽의 얇은 뼈 영역에서 재현율과 다이스 유사계수 측면에서 향상된 분할 결과를 보였다. 이는 밝기값 뿐만 아니라 얇은 뼈의 특성을 고려하여 다중 스케일 모듈과 듀얼 어텐션 모듈을 스킵 연결 부분에 사용한 효과로 분석된다.
| Thin bones of medial wall and orbital floor | ||||
|---|---|---|---|---|
| Recall | DSC | |||
| Lee[4] | 67.61±7.74 | 61.96±5.50 | ||
| Thin bones of medial wall | Thin bones of orbital floor | |||
|---|---|---|---|---|
| Recall | DSC | Recall | DSC | |
| Lee[5] | 58.24±9.17 | 46.99±6.40 | - | - |
| An[6] | 81.07±10.53 | 83.09±8.09 | 79.23±11.54 | 83.09±8.42 |
| MSDA-Net (Ours) | 86.14±8.65 | 86.44±7.55 | 86.92±9.23 | 87.21±7.70 |
4. 결론
본 연구에서는 안면부 CT 영상에서 안와 뼈의 해부학적 구조와 특성을 고려하여 얇은 뼈의 분할 정확도를 개선하는 MSDA-Net을 제안하였다. 다중 스케일 모듈과 채널과 공간 정보를 모두 활용하는 듀얼 어텐션 모듈을 U-Net의 스킵 연결 부분에 구성하였다. 실험을 통해 제안한 방법이 U-Net에 비해 안와 내측벽의 지역적 평가 영역은 1.91%, 0.41%, 안와 하벽의 지역적 평가 영역은 1.65%, 0.35%, 전역적 평가 영역은 0.83% 0.07% 모두 향상되어 스킵 연결 부분에 추가된 다중 스케일 듀얼 어텐션 모듈의 효과를 확인할 수 있었다. 또한, 채널 어텐션과 공간 어텐션을 각각 하나만 쓰는 것보다 순차적으로 수행하는 듀얼 어텐션 모듈을 사용할 때 얇은 뼈 영역에서 가장 우수한 성능을 보였다.
명확하지 않은 안와 내측벽 및 하벽의 얇은 뼈 영역에 대해서도 일관성 있게 자동 분할함으로써 환자 맞춤형 인공 보형물 제작에 있어 수동 보정(manual correction)하는 작업 시간을 줄일 수 있을 뿐 아니라 수동 보정 작업자 간의 변동성(inter-observer variability)을 줄일 수 있다. 본 연구는 매우 얇은 굵기와 낮은 밝기값을 갖는 얇은 뼈의 특성으로 인해 수동 분할하는 전문가에 따라 레이블링 결과의 차이가 생길 수 있고, 분할되어야 할 부분이 제대로 수동 분할되지 않아 발생하는 잡음 레이블(noisy label)이 학습에 영향을 미칠 수 있다는 한계를 가진다. 그러므로 향후 연구 방향으로는 학습 과정에서 잡음 레이블을 식별하고 정제하여 얇은 뼈 영역 분할 정확도를 개선하고자 한다.



