
1. 서론
자연어 설명으로부터 자연스러운 3D 인간 모션을 생성하는 기술은 컴퓨터 그래픽스, 게임, 가상현실 등 다양한 분야에서 중요한 응용 가능성을 가지고 있어 최근 활발한 연구가 진행되고 있으며, 특히 메타버스 기술의 발전과 함께 자연스럽고 표현력 있는 인간 모션 생성의 중요성이 더욱 부각되고 있다. 이러한 텍스트 기반 모션 생성 기술은 자연어의 복잡한 의미 구조를 이해하고, 이를 시공간적으로 일관성 있는 3D 모션으로 변환해야 하는 도전적인 문제이다.
자연어는 본질적으로 모호성과 복잡성을 내포하고 있으며, 동일한 텍스트 설명도 다양하게 해석될 수 있다. 예를 들어, “천천히 걷기”와 같은 간단한 설명도 개인의 신체적 특성, 감정 상태, 주변 환경 등에 따라 매우 다른 모션으로 표현될 수 있다. 또한, “손을 흔들며 뛰기”와 같은 복합적인 동작은 상체와 하체가 서로 다른 움직임을 동시에 수행해야 하므로, 각 신체 부위의 특성을 정확히 이해하고 조합하는 것이 필수적이다.
기존의 텍스트 기반 모션 생성 모델들은 주로 전체 모션 시퀀스를 하나의 통합된 표현으로 처리하는 방식을 채택하고 있다. 그러나 인간의 모션은 본질적으로 상체, 하체, 팔, 다리 등 각 신체 부위가 서로 다른 특성과 움직임 패턴을 가지고 있으며, 서로 다른 모션 특성을 요구한다. 따라서 이러한 신체 부위별 특성을 고려하지 않고 전체 모션을 일률적으로 처리하는 것은 생성되는 모션의 품질과 다양성을 제한할 수 있다.
신체 부위별 특화된 모션 생성을 위해 일부 연구들은 신체 부위별로 독립적인 생성 모듈을 구성하는 방법을 제안하였다. 하지만 이러한 접근법은 모델 크기의 급격한 증가를 초래하며, 이에 따라 더 많은 학습 데이터와 계산 자원이 필요하다는 문제가 존재한다.
이러한 문제를 해결하기 위해 본 논문에서는 Mixture of Experts (MoE) 구조를 텍스트 기반 모션 생성에 적용하는 새로운 접근법을 제안한다. MoE는 여러 개의 전문가 모델을 두고 입력에 따라 적절한 전문가를 활성화하여 활용하는 기법으로, 복잡한 문제를 여러 하위 문제로 분할하여 각각을 전문적으로 처리할 수 있다는 장점이 있다. 본 연구에서는 이를 활용하여 각 전문가가 특정 신체 부위나 모션 패턴에 특화되도록 학습함으로써, 보다 정교하고 자연스러운 모션 생성을 목표로 한다.
본 연구는 MoE 구조를 통해 텍스트의 의미 단위와 모션 구성 요소 간의 정렬을 보다 명시적이고 구조화된 방식으로 달성하고자 한다. 텍스트 입력의 각 토큰이 개별 전문가를 통해 처리됨으로써, 텍스트와 모션 사이의 의미적 정합성이 강화된다. 또한 희소 활성화 (sparse activation)를 기반으로 한 전문가 선택 메커니즘을 도입하여, 모델 전체의 파라미터 수는 확장 가능하되, 실제 연산 비용은 유지함으로써 계산 효율성과 확장성을 동시에 확보할 수 있다.
본 연구의 핵심 기여는 다음과 같이 요약할 수 있다.
2. 관련 연구
텍스트 기반 모션 생성은 자연어로 기술된 문장을 입력으로 받아 의미에 부합하는 모션을 생성하는 기술로, 최근 다양한 딥러닝 모델들이 이 분야에 적용되고 있다.
초기 연구들은 Variational AutoEncoder (VAE) [1]를 통해 연속 잠재 공간에서 텍스트 의미를 반영한 샘플을 생성한 뒤 이를 복원하는 구조를 갖는다. TEMOS [2]는 텍스트와 모션을 잠재 공간에 공동 임베딩하고, cross-attention 기반 디코더를 통해 고품질의 모션 시퀀스를 생성하였다. 이외에도 T2M [3]은 VAE의 잠재 변수 분포를 활용하여 동일한 문장에서 다양한 스타일의 모션을 생성할 수 있음을 보였으며, 표현 다양성 측면에서 큰 진전을 이루었다. 그러나 이러한 방식은 연속 공간 표현의 한계와 장기 시퀀스에서의 정합성 부족 문제를 일부 내포하고 있다.
이후 제안된 diffusion 모델 [4] 기반 접근은 확률적 노이즈 제거 과정을 통해 점진적으로 모션을 복원하는 방식이다. MDM [5]은 텍스트 조건부 모션 생성을 위해 diffusion 과정을 Transformer [6]와 결합하여 구현하였으며, 시간적 일관성과 정밀한 움직임 표현에서 우수한 성능을 입증하였다. 또한 MLD [7]는 잠재 공간에서의 diffusion을 수행함으로써 더 효율적인 샘플링과 고품질 모션 생성을 동시에 달성하였다. 이러한 계열의 방법들은 복잡하고 다양한 모션 표현에서 정량적, 정성적으로 뛰어난 결과를 보였다.
최근 연구들에서는 Vector-Quantised VAE (VQ-VAE) [8]를 활용하여 모션 시퀀스를 이산 토큰 시퀀스로 변환한 후, 이를 Transformer로 모델링하는 방식을 채택한다. 이산 표현을 통해 장기 구조 학습이 용이하며, 토큰 단위의 예측을 통해 보다 안정적인 생성 성능을 달성하였다. MoMask [9]는 모션 마스킹 및 복원을 기반으로 텍스트 조건 하에서 정교한 모션 토큰 생성을 달성하였으며, 이는 학습 안정성과 샘플 다양성 측면에서 강점을 보였다. 해당 계열의 모델들은 VQ-VAE의 강점인 표현 정수성과 Transformer의 순차적 구조 모델링 능력을 결합하여 자연스러운 모션 시퀀스를 효과적으로 생성할 수 있음을 보여준다.
인간의 동작은 본질적으로 다양한 신체 부위의 조합으로 구성되며, 각 부위는 고유한 움직임 특성을 지닌다. 이러한 특성을 반영하기 위해, 일부 연구에서는 상체와 하체를 별도로 분리하여 모션을 생성하는 방식이 제안되었다 [10]. 이 구조는 각 부위의 표현력을 높이고 복잡한 동작의 조합을 효과적으로 처리할 수 있는 장점을 갖는다.
또 다른 접근으로는 신체 부위를 5개 영역 (양팔, 양 다리, 몸통)으로 나누고, 지역-전역 어텐션을 통해 부위별 특징을 계층적으로 추출하는 방법이 있으며 [11], 해당 방식은 텍스트의 세부 내용에 따라 다양한 부위의 표현을 정교하게 반영하는 데 효과적이다.
더 나아가, 일부 연구에서는 각 신체 부위에 특화된 모델을 별도로 설계하고, 문장에서 추출한 의미적 단위를 각 모델에 할당하여 모션을 생성하는 구조가 제안되었다 [12]. 이 방식은 문장의 구조를 기반으로 상체와 하체 등 신체 부위별 동작을 명시적으로 분리하여 모델링함으로써, 복잡한 문장에 대한 세분화된 동작 생성을 가능하게 한다.
이처럼 부위별 모션 모델링은 동작의 세밀한 제어와 다양성 확보 측면에서 유용한 방향으로 인식되고 있다.
MoE [13]는 입력에 따라 서로 다른 전문가 모델을 선택적으로 활성화하여 복잡한 문제를 분할 정복 방식으로 처리하는 구조이다. 초기에는 간단한 회귀 문제를 해결하기 위한 방식으로 제안되었으며, 최근에는 대규모 모델을 효율적으로 운용하기 위한 핵심 기술로 재조명되고 있다.
대규모 언어 모델에서는 MoE 구조가 이미 중요한 확장 전략으로 자리잡고 있으며, 각 입력 토큰에 대해 최적의 전문가를 선택하여 처리하는 방식이 성공적으로 활용되고 있다. 예를 들어, Switch Transformer와 같은 모델은 수 조 개의 파라미터를 효율적으로 운용하면서도 높은 성능을 유지할 수 있었으며, 이 과정에서 MoE는 연산 자원의 효율성과 표현력의 균형을 동시에 달성하는 데 핵심적인 역할을 하였다 [14].
3. 방법론
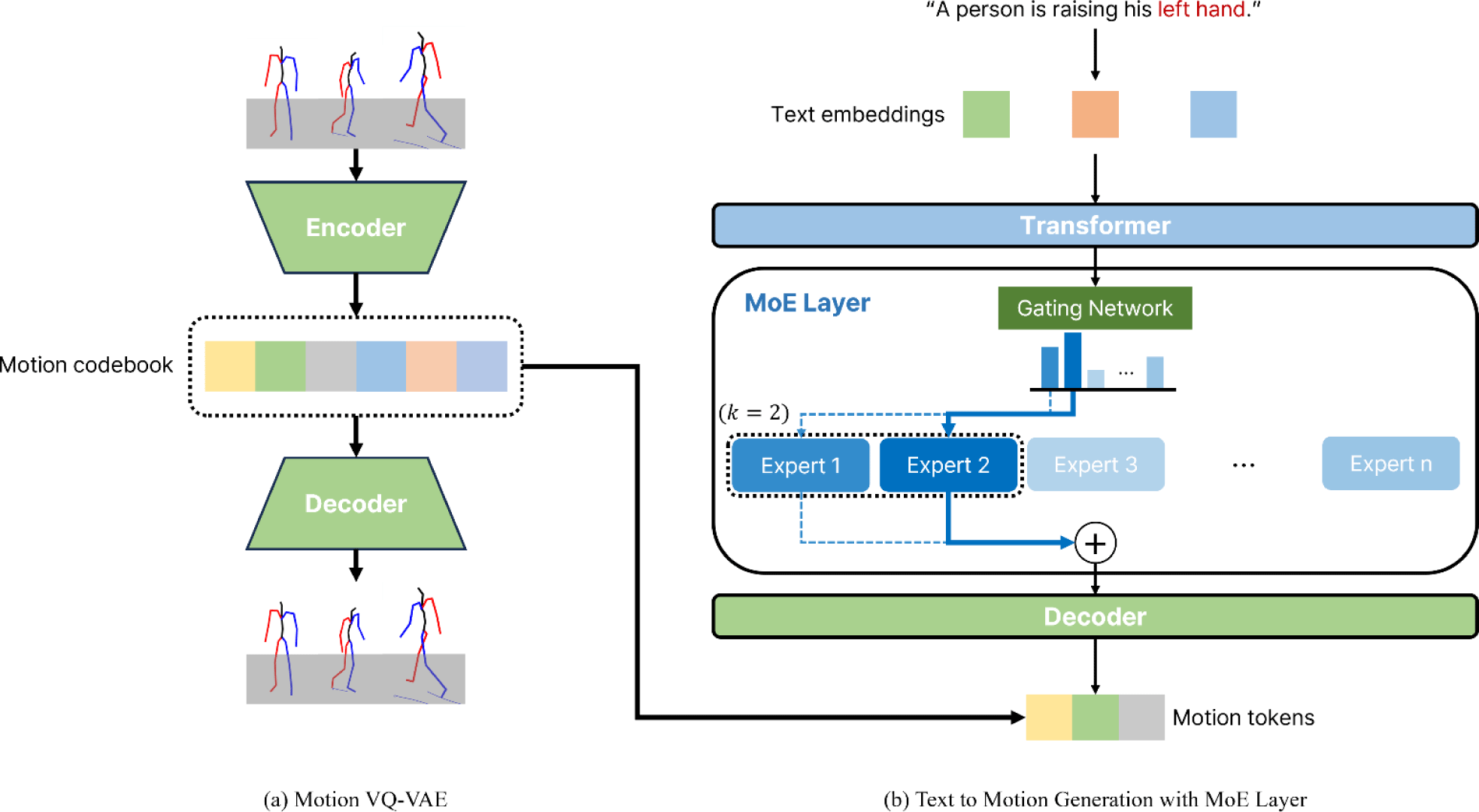
본 논문에서 제안하는 모델은 T2M-GPT [15]의 아키텍처를 베이스라인으로 삼되, Transformer 내부에 MoE 구조를 통합하여 확장한 형태이다.
기본 프레임워크는 두 단계로 구성되며, 먼저 VQ-VAE를 통해 연속적인 3D 모션 데이터를 이산적인 토큰 시퀀스로 양자화하고, 이를 복원하는 디코더를 학습한다. 이후 텍스트 설명으로부터 모션 시퀀스를 예측하는 Transformer 기반 생성기를 학습하는 방식이다.
기존 모델에서 Transformer는 텍스트를 조건으로 전체 모션을 단일 특징 벡터 흐름으로 생성하였다. 본 연구에서는 해당 구조를 확장하여 Transformer 내부에 일부 MoE 레이어를 삽입하고, 각 시점의 모션 특징 벡터에 대해 전문가 선택 기반의 부분 처리 방식을 도입하였다. 이를 통해 모션의 전체적인 일관성은 유지하면서도, 세밀한 동작 표현을 각 전문가가 나누어 학습할 수 있는 구조를 갖는다.
전체 모델은 다음과 같이 구성된다: (1) 텍스트 인코딩은 Transformer 인코더로 구성된 CLIP [16] 기반 특징 벡터 추출기를 활용하고, (2) 모션 디코딩은 기존의 VQ-VAE 구조를 유지하며, (3) 모션 토큰 시퀀스를 생성하는 Transformer 내부에 MoE 레이어를 삽입하여, 입력 특징 벡터의 의미에 따라 전문가 조합을 동적으로 선택하고 활성화하는 방식으로 처리한다.
MoE 레이어는 Transformer 블록의 피드포워드 단계 일부를 대체하며, 입력된 특징 벡터에 대해 다음과 같은 과정을 수행한다. 먼저 디코더 이전 단계에서 얻은 특징 벡터 h∈ℝd에 대해, 선형층 Wg∈ℝd}n을 적용하여 n개의 전문가에 대한 gating logit (g1,g2,…,gi,…,gn)을 얻는다 여기서 d는 특징 벡터의 차원 수이고 n은 전문가의 개수이다. 이 값들은 아래 식과 같이 softmax 함수를 통해 확률 분포로 정규화된다.
이후 gi 값이 큰 순서대로 상위 k 개의 전문가 인덱스 i1,…,ik를 선택한다. 여기서 각 ij는 게이팅 분포에서 상위 확률을 갖는 전문가의 인덱스를 의미하며, 해당 인덱스에 대응되는 전문가 Eij가 실제로 활성화되어 사용된다. 본 모델에서는 모든 전문가가 동일한 특징 벡터 h를 처리한 후, 선택된 전문가의 출력만을 가중합으로 조합하는 구조를 따른다.
이때 g̃ij은 선택된 전문가들에 대한 정규화된 가중치이며, 다음과 같이 정의한다.
이와 같은 구조는 의미 기반 feature routing을 실현함과 동시에, 모델 계산량을 줄이고 확장성을 높이는 데 기여한다.
본 모델의 MoE 구조는 명시적인 신체 부위 라벨 없이도, 전문가들이 입력 특징 벡터의 의미에 따라 자율적으로 서로 다른 역할을 암묵적으로 학습하도록 설계되었다. 이러한 구조는 전문가에게 명확한 기능을 사전에 할당하지 않고도 기능적 분화가 자연스럽게 발생하는 것을 목표로 한다.
전문가의 역할 학습은 텍스트 기반 모션 생성에서 중요한 요소이다. 자연어는 다양한 의미 단위를 포함하며, 이를 반영하는 모션 역시 시공간적으로 복잡한 구조를 가진다. 따라서 입력 특징 벡터의 의미적 구성에 따라 특정 전문가들이 반복적으로 선택되는 구조는, 모델이 다양한 의미 구성 요소를 모션의 부분적 표현으로 효과적으로 분산시키는 데 도움이 된다. 이러한 선택은 앞서 기술했듯이 softmax 기반 게이팅과 top-k 전문가 선택 메커니즘을 통해 이루어지며, 학습이 진행됨에 따라 전문가들이 서로 다른 유형의 모션 표현에 기여하게 된다.
이와 같이 전문가 간 역할이 명시적으로 정해지지 않았지만, 학습 과정에서 입력에 대한 전문가 선택이 점차 분화되는 현상은 모델이 의미 기반 feature routing을 암묵적으로 수행하고 있음을 보여준다. 이로 인해 모델은 전체 모션 시퀀스 생성 시 텍스트의 의미 구조를 보다 정밀하고 세분화된 방식으로 반영할 수 있으며, 이는 결과적으로 더 자연스럽고 일관성 있는 모션 생성으로 이어진다.
4. 실험 및 결과
본 논문의 실험은 텍스트 기반 3D 모션 생성 성능을 평가하기 위해 HumanML3D 데이터셋 [3]을 사용하였다. 해당 데이터셋은 14,616개의 문장-모션 쌍을 포함하며, 평균 13초 분량의 인간 동작 클립과 이에 상응하는 자연어 설명으로 구성되어 있다. 실험은 9:1:1 비율로 나눈 학습/검증/테스트 셋을 기준으로 기존 연구들과 동일하게 진행하였다.
정량 평가는 다음 다섯 가지 지표를 기반으로 수행하였다.
-
Fréchet Inception Distance (FID): 생성된 모션이 실제 모션과 얼마나 유사한지를 평가하는 지표로, Recurrent Neural Ntwork (RNN) 기반 모션 특징 추출기에서 추출한 특징 벡터를 기반으로 계산된다. 생성된 모션의 품질을 측정하는 지표이며, 값이 낮을수록 생성된 모션의 분포가 실제 모션의 분포와 가깝다는 것을 의미한다.
-
R-Precision: 입력 텍스트와 생성된 모션 간의 의미 일치도를 정량화한 지표로, 텍스트-모션 쌍의 정답 순위를 기준으로 측정한다. 값이 높을수록 의미적으로 정확한 모션 생성이 가능함을 의미한다.
-
Multimodal Distance: 다양한 텍스트에 대해 생성된 모션들이 동일하거나 유사한 양상을 보일 경우 낮은 점수를 기록하며, 모션 다양성보다는 의미 일치에 더 민감한 특성을 가진다.
-
Diversity: 동일한 텍스트 조건에서 생성된 여러 모션 샘플 간의 평균 거리를 측정하여, 생성된 모션의 다양성을 평가한다. 값이 높을수록 다양한 모션 표현이 가능함을 나타낸다.
-
Multimodality: 하나의 텍스트 설명에 대해 다양한 모션 스타일을 생성할 수 있는 능력을 정량화한 지표로, 문장 조건에 대한 표현력과 생성의 비결정성을 반영한다.
입력 모션 데이터는 HumanML3D 데이터셋 [3]의 표현 방식을 따르며, SMPL [17] 기반 22개 관절에 대한 다양한 신호로 구성된다.
하나의 모션 시퀀스 M는 총 F개의 프레임과 J=22개의 관절 정보를 포함하며, 구체적으로 다음과 같은 요소들로 구성된다: 루트 관절의 y축 각속도 ṙ ̇∈ ℝF×1xz 평면 상의 선속도 vroot ∈ ℝF×1, 루트 관절의 높이 h ∈ ℝF×1, 루트를 제외한 관절의 로컬 위치 p ∈ ℝF×(J-1)×3, 6D 회전 표현 r ∈ ℝF×(J-1)×6, 관절별 속도 v ∈ ℝF×J×3, 그리고 양 발의 접지 여부를 나타내는 접지 신호 c ∈ ℝF×4 등이다. [3]이와 같이 구성된 모션 표현은 학습의 안정성을 높이고, 네트워크가 다양한 모션 세부 특성을 학습하는 데 도움을 준다.
텍스트-모션 Transformer는 앞서 제시한 MoE 레이어를 포함한 아키텍쳐를 기반으로 하며, 학습은 teacher forcing 방식으로 수행된다. 최적화는 AdamW 옵티마이저 (β1=0.5,β2=0.9) [18]를 사용하였으며, 초기 학습률은 2e-4로 설정 후 처음 20만 step 동안 고정한 뒤 1e-5까지 선형적으로 감소시켰다.
모델 학습은 NVIDIA RTX A5000 환경에서 진행되었으며, 전체 학습 시간은 배치 사이즈 128 기준으로 약 54시간이 소요되었다. 이는 기존 모델 [15] 대비 약 30% 감소된 시간이다.
Table 1에서 확인할 수 있듯이 본 모델은 기존 텍스트 기반 모션 생성 모델과 비교하여 HumanML3D 데이터셋 벤치마크에서 우수한 생성 성능을 기록하였다.
| Methods | R-Precision ↑ | FID ↓ | MM-Dist ↓ | Diversity → | MModality ↑ | ||
|---|---|---|---|---|---|---|---|
| Top-1 | Top-2 | Top-3 | |||||
| Real Motion | 0.511 | 0.703 | 0.797 | 0.002 | 2.974 | 9.503 | - |
| T2M-GPT [15] | 0.491 | 0.680 | 0.775 | 0.116 | 3.118 | 9.761 | 1.856 |
| TM2T [19] | 0.424 | 0.618 | 0.729 | 1.501 | 3.467 | 8.589 | 2.424 |
| FineMoGen [20] | 0.504 | 0.690 | 0.784 | 0.151 | 2.998 | 9.263 | 2.696 |
| MDM [5] | 0.320 | 0.498 | 0.611 | 0.544 | 5.566 | 9.559 | 2.799 |
| ParCo [12] | 0.515 | 0.706 | 0.801 | 0.109 | 2.927 | 9.576 | 1.382 |
| Ours | 0.476 | 0.669 | 0.767 | 0.106 | 3.151 | 9.570 | 1.829 |
특히, 제안된 모델은 MoE 구조를 통해 표현력 있는 모션 생성을 가능하게 하였으며, 전체적인 FID 수치는 기존 방법들보다 현저히 낮은 값을 나타냈다. 이는 제안된 구조가 복잡한 자연어의 의미를 보다 세밀하게 반영하고, 각 시점의 모션 특징을 다양한 전문가를 통해 적절히 분산하여 학습할 수 있도록 설계된 점에서 기인한다.
또한, Diversity와 Multimodality 측면에서도 우수한 균형을 달성하였다. 이는 제안된 모델이 다양한 텍스트 입력에 대해 서로 다른 모션 스타일을 일관되게 생성할 수 있음을 시사한다.
이와 같은 결과는 전문가의 암묵적 분화를 유도하는 sparse routing 구조가, 텍스트 의미와 모션 표현 간의 정렬을 효과적으로 수행함을 정량적으로 뒷받침한다.
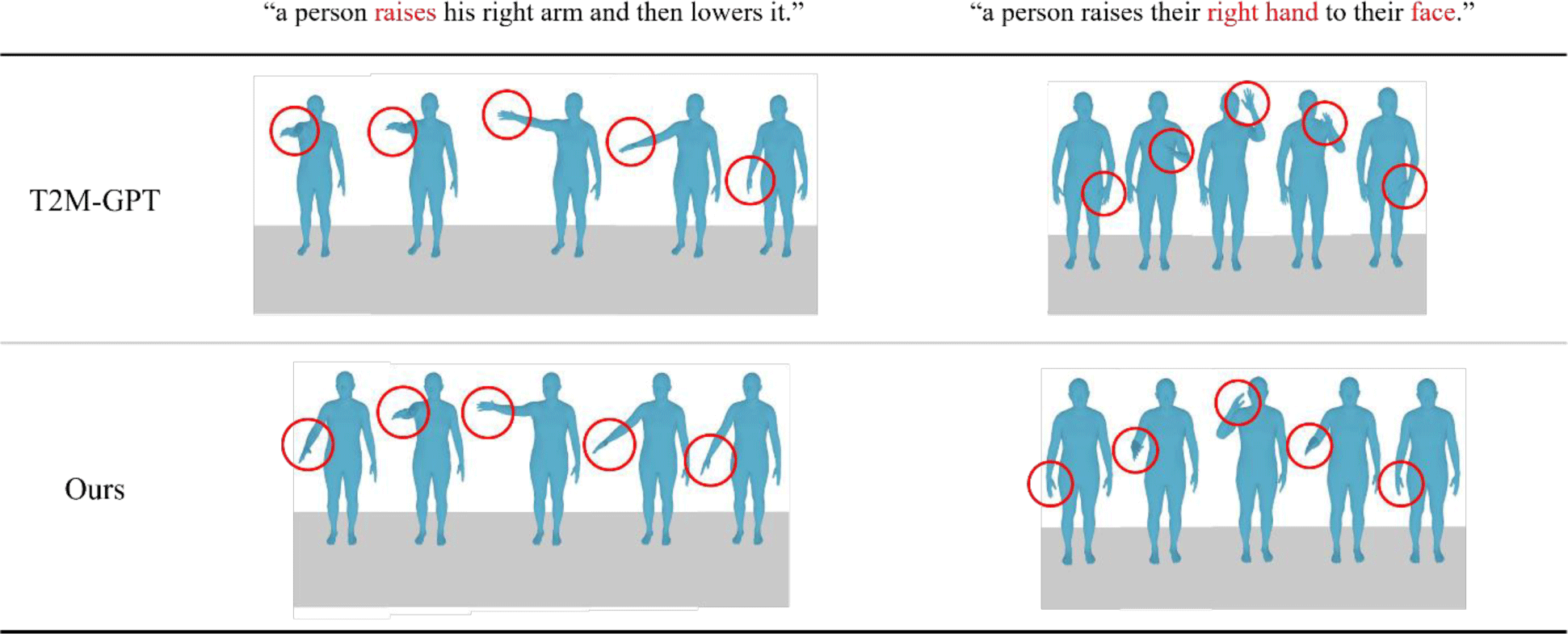
본 절에서는 정성적 분석을 위해 다양한 자연어 설명을 입력으로 사용하여 생성된 모션 시퀀스를 시각화하고, 기존 모델들과 비교한다.
Figure 2에서 확인할 수 있듯이, 본 연구에서 제안한 MoE 기반 구조는 복합적인 동작에서도 각 신체 부위의 움직임이 보다 정교하게 조화를 이루는 양상을 보였다. 이러한 결과는 기존의 단일 모델 기반 구조와 비교했을 때, 제안된 MoE 기반 구조가 입력 텍스트로부터 유도되는 복합적 동작 구성 요소를 보다 효과적으로 분리 및 통합하여 시공간적으로 정교한 모션 표현을 가능하게 함을 시사한다. 이는 각 전문가가 선택적으로 활성화되어 모션 생성을 분담함으로써, 다양한 의미적 요소가 반영된 세분화된 표현을 가능하게 만들기 때문이다.
본 절에서는 제안한 MoE 구조의 설계 요소가 성능에 미치는 영향을 정량적으로 분석하기 위해 두 가지 관점에서 수행한 제거 연구 결과를 분석한다.
Dense MoE와 sparse MoE 비교: Dense MoE 구조는 모든 전문가의 출력값 평균을 사용하는 방식이며, Sparse MoE는 제안한 방식처럼 상위 k개의 전문가만을 선택하여 출력을 혼합한다. Table 2에서 확인할 수 있듯이 sparse MoE 구조는 dense MoE에 비해 FID 및 Multimodal Distance 측면에서 더 우수한 수치를 기록하였다. 이는 전문가 선택의 희소성이 표현력을 유지하면서도 불필요한 계산을 줄이고, 각 전문가의 특화된 학습을 촉진한다는 점을 나타낸다.
| MoE methods | Top-3 ↑ | FID ↓ | MM-Dist ↓ |
|---|---|---|---|
| Ours (Dense) | 0.770 | 0.129 | 3.168 |
| Ours (Sparse) | 0.767 | 0.106 | 3.151 |
전문가 개수 (n)에 따른 성능 차이: MoE 구조에서 사용되는 전문가의 개수 (n)을 변화시키며 성능을 비교하였다. 본 실험에서는 n=2,6,10의 세 가지 설정을 대상으로 동일한 top-k 조건 (k=2) 하에 비교를 수행하였다. Table 3에서 확인할 수 있듯이, 전문가 수가 적은 n=2에서는 모션의 다양성과 표현력이 상대적으로 저하되었고, 전문가 수가 많은 n=10에서는 생성된 모션의 품질이 크게 하락했다. 반면, n=6의 설정에서는 균형 잡힌 성능을 보였다. 이는 전문가 수가 지나치게 적을 경우 모델의 표현력이 제한될 수 있고, 반대로 많은 전문가를 사용할 경우 gating network의 선택 효율이 저하되어 학습 안정성과 모션 품질에 부정적인 영향을 미칠 수 있음을 시사한다. 적절한 전문가 수는 구조적인 희소성을 유지하면서도, 각 전문가가 효과적으로 차별화된 표현을 학습하는 데 기여할 수 있다.
| Number of experts (n) | Top-3 ↑ | FID ↓ | MM-Dist ↓ |
|---|---|---|---|
| n=2 | 0.778 | 0.130 | 3.105 |
| n=6 | 0.767 | 0.106 | 3.151 |
| n=10 | 0.787 | 0.234 | 3.067 |
이러한 제거 연구는 제안한 MoE 구조의 구성 요소들이 실제 성능에 영향을 미치며, 올바른 설정을 통해 효율성과 정확도를 모두 달성할 수 있음을 보여준다.
5. 결론 및 향후 계획
본 논문에서는 MoE 구조를 통해 텍스트 기반 3D 모션 생성 모델의 성능을 향상하는 새로운 접근법을 제시하였다. 제안된 모델은 신체 부위별 전문가 모델이 텍스트 의미에 따라 협업적으로 동작을 생성하도록 구성되어, 기존의 단일 표현 기반 접근보다 부위별 정밀성과 전체적인 일관성 모두에서 우수한 결과를 도출하였다. 실험 결과에 따르면 제안 기법은 다양한 텍스트 입력에 대해 자연스럽고 텍스트 의미에 부합하는 모션을 생성함으로써, 기존 방식 대비 모션의 품질과 표현력 측면에서 향상된 성능을 보였다.
또한 본 연구는 MoE 기반 희소 전문가 선택 구조를 통해 계산 자원을 효율적으로 활용함과 동시에, 전문가 수의 확장을 통한 모델 용량 조절 및 새로운 모션 유형에 대한 적응 가능성을 확보하였다. 나아가 본 구조는 다른 생성 모델 (예: diffusion 기반 모델)의 표현 학습 단계에 통합될 수 있는 확장성을 가지며, 부분 제어 능력을 향상시키는 방향으로의 발전도 기대된다.
향후 연구로는 전문가 별로 더욱 명시적인 역할 부여 (예: 특정 관절 그룹 할당) 및 gating 단계에서의 부하 균형 기법 적용 등을 통해 전문가의 활용도를 극대화하는 방안을 모색할 예정이다.
요약하면, 본 연구는 텍스트로부터 사람의 복잡한 동작을 생성함에 있어 모션의 구성 요소를 전문가 모델들에게 분산시켜 학습하게 함으로써, 모델의 표현력과 생성 품질을 향상시켰다. 이러한 MoE를 활용한 모션 생성 방법은 향후 더욱 풍부하고 정교한 동작 생성을 이루는 데 기여할 것으로 기대된다.





