Article
확산 모델 기반 오토인코더를 활용한 다중파라미터 MR 영상에서의 전립선암 악성도 예측
Predicting Prostate Cancer Aggressiveness via Diffusion Autoencoders with Multi-Parametric MR Images
Yejin Shin
1
, Min Jin Lee
1, Sung Il Hwang
2, Helen Hong
1,*
1Department of Softward Convergence, Seoul Women’s University
2Department of Radiology, Seoul National University Bundang Hospital
*corresponding author: Helen Hong/Department of Softward Convergence, Seoul Women’s University(
hlhong@swu.ac.kr)
© Copyright 2025 Korea Computer Graphics Society. This is an Open-Access article distributed under the terms of the
Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0/) which permits
unrestricted non-commercial use, distribution, and reproduction in any
medium, provided the original work is properly cited.
Received: Jul 04, 2025; Revised: Sep 06, 2025; Accepted: Sep 11, 2025
Published Online: Dec 01, 2025
요약
본 연구는 전립선암 악성도 예측을 위한 영상 특징 추출 방식으로, 확산 모델 기반 오토인코더와 다중 파라미터 MR 영상의 독립 인코딩 구조(mp-FE)를 결합한 새로운 프레임워크를 제안한다. 확산 모델 기반 오토인코더는 기본 오토인코더의 디코더 부분을 확산 모델로 대체함으로써, 인코더가 추출한 잠재 벡터가 보다 정보량이 풍부하고 악성도 예측에 유용한 특징을 내포하도록 유도하고자 한다. 또한 다중 파라미터 MR 영상 별 고유한 특징들을 갖는 잠재 벡터를 획득하고자, 각 파라미터 영상별로 독립된 인코더를 구성하고 각각 추출된 특징을 통합하여 사용하는 mp-FE 방법을 제안한다. 실험 결과, mp-FE 방법을 적용한 확산 모델 기반 오토인코더를 통해 DWI 영상을 복원하며 특징을 학습할 경우에서 정확도 70.97%, 특이도 79.41%, AUROC 0.72를 기록하며 가장 우수한 성능을 달성했다.
Abstract
This study proposes a novel framework that combines a diffusion autoencoder with an independent encoding structure for multi-parametric MR images (mp-FE), as a method for extracting imaging features for prostate cancer aggressiveness prediction. The diffusion autoencoder replaces the decoder part of a conventional autoencoder with a diffusion model, thereby guiding the encoder to produce latent vectors that are more informative and contain features useful for aggressiveness prediction. Additionally, to obtain latent vectors that capture the unique characteristics of each parametric MR image, the proposed mp-FE method constructs independent encoders for each parameter image and integrates the separately extracted features. Experimental results showed that, when reconstructing DWI images using the diffusion autoencoder with the mp-FE method, the model achieved the best performance, recording an accuracy of 70.97%, specificity of 79.41%, and AUROC of 0.72.
Keywords: 전립선암; 예측; 확산 모델; 오토인코더; 다중 파라미터 자기공명영상
Keywords: prostate cancer; prediction; diffusion model; autoencoder; multi-parametric MRI
1. 서론
전립선암(prostate cancer, PCa)은 전 세계 남성에서 두 번째로 많이 발생하는 암이며, 암으로 인한 사망 원인 중에서도 다섯 번째로 높은 암이다[1]. 전립선암 환자의 적절한 치료 계획을 수립하고 예후를 관리하기 위해서는 전립선암의 악성도를 조기에 예측하는 것이 중요하다[2]. 일반적으로 전립선암의 악성도 평가는 생검을 통해 얻은 조직 샘플에 기반한 글리슨 점수(Gleason score)로 이루어진다. 이는 가장 흔히 나타나는 두가지 암세포의 분화 정도를 각각 1~5등급으로 평가한 후 두 등급의 합산값으로 산정되며, 총점이 높을수록 악성도가 높은 것으로 간주된다[3]. 이에 따라 전립선암은 고위험군(high grade PCa, hPCa)과 저위험군(low grade PCa, lPCa)으로 분류된다. 정확한 악성도 예측은 저위험군 환자에게는 과도한 치료 없이 추적 관찰만으로도 관리할 수 있도록 하며, 고위험군 환자에게는 조기에 적절한 치료 계획을 수립하는데 기여한다. 그러나 조직 생검은 침습적 시술로서, 출혈 등의 합병증 위험이 있으며 전립선의 제한적 영역에 대한 무작위 채취 방식이므로 진단 정확도에 한계가 있다[4]. 이에 따라 최근에는 비침습적인 방법으로써 자기공명영상(Magnetic Resonance Imaging, MRI)을 기반으로 한 딥러닝 모델을 활용하여 전립선암의 악성도를 예측하는 연구가 활발히 진행되고 있다.
특히, 딥러닝 기반의 생성 모델 중 하나인 확산 모델(Diffusion model)은 고해상도 영상 생성 성능과 안정적인 학습 특성으로 주목받고 있다[5]. 확산 모델은 입력 데이터에 점진적으로 노이즈를 추가한 후 이를 역으로 제거하며 원본 데이터를 복원하는 방식으로 동작하며, 기존 생성 모델(GAN[6], VAE[7]) 대비 학습 안정성과 생성 품질 측면에서 우수한 성능을 보인다[8,9]. 이러한 특성으로 인해 최근 의료 영상 분야에서도 확산 모델을 분류 및 예측 작업에 활용하려는 시도가 증가하고 있다[10]. Yang et al.[11]은 다양한 모달리티의 의료 영상에서도 보다 강건하고 일반화된 의료 영상 분류기를 구현하고자, 영상 전체 및 국소 영역의 이중 조건을 적용한 확산 모델 기반의 분류 프레임워크를 제안하였다. Atad et al.[12]은 척추뼈 골절 분류 및 중증도 예측을 위해, 확산 모델 기반 오토인코더[13]의 잠재 벡터를 조작하여 반사실적 예시(counterfactual examples)를 생성하고 이를 활용한 예측 네트워크를 설계하였다. 또한 Busaranuvong et al.[14]는 당뇨병성 족부궤양 감염 예측에 있어 클래스 조건에 따른 영상을 생성하고 원본 영상과 생성 영상 간의 L2 거리를 기반으로 감염 여부를 분류하는 방식을 제안하였다. 이들 연구는 확산 모델을 통해 의료 영상에서 의미 있는 잠재 벡터(latent vector)를 추출하고, 이를 통해 분류 및 예측 성능을 향상시킬 수 있음을 보여준다. 특히 조건 기반의 잠재 벡터 조작이 가능하다는 점은 의료 영상 분석에서 높은 확장성과 해석 가능성을 제공한다.
본 연구는 전립선암 악성도 예측 정확도를 향상시키기 위해, 확산 모델 기반 오토인코더[13] 구조를 예측 모델에 접목하고, 다중 파라미터 MR 영상(multi-parametric MR imaging)의 정보를 효과적으로 활용할 수 있는 방법을 제안한다. 제안 방법의 독창성은 두 가지로 요약할 수 있다. 첫째, 확산 모델의 복원 매커니즘을 오토인코더[15]의 디코더에 접목함으로써, 인코더가 추출한 잠재 벡터가 보다 정보량이 풍부하고 예측에 유용한 특징을 내포하도록 유도하여 인코더의 표현력을 강화한다. 둘째, 서로 다른 MR 파라미터에서 얻은 영상 정보를 독립적으로 인코딩하고, 이를 통합하여 예측에 활용하는 다중 파라미터 특징 추출(multi-parametric feature extraction, mp-FE) 방법을 제안한다. 이는 각 파라미터 영상 특징 간 간섭을 줄이고, 서로 다른 영상이 가진 유의미한 정보를 보존한 채 종합적으로 활용할 수 있도록 설계한다.
2. 제안 방법
2.1 확산 모델 기반 오토인코더를 활용한 전립선암 MR 영상 특징 추출
본 논문에서는 전립선암의 악성도 예측 성능을 향상시키기 위해, 전립선 MR 영상에서 유의미한 특징을 효과적으로 추출할 수 있는 프레임워크로 확산 모델 기반 오토인코더 (Diffusion Autoencoder, DiffAE)를 활용한다. 본 프레임워크는 전통적인 오토인코더 구조의 디코더를 확산 모델로 대체함으로써, 인코더가 생성하는 잠재 벡터의 품질을 향상시키는 것을 목표로 한다.
먼저 확산 모델 기반 오토인코더의 인코더는 입력 영상 x0로부터 저차원의 잠재 벡터 zsemamtic을 추출한다. 해당 벡터는 영상 전반에 걸친 구조적 정보 및 명암 분포 등을 포함한 유의미한(semantic) 특징을 함축한다. 이후, 디코더는 DDIM(Denoising Diffusion Implicit Models)[9] 알고리즘을 기반으로 하여 zsemamtic와 가우시안 노이즈 xT를 함께 입력받은 후, t= T→0 범위에 걸쳐 xt에 포함된 노이즈를 점진적으로 제거하여 영상 (x̂0) 을 복원한다. 이때, 확산 모델 기반의 디코더는 영상 복원 과정에서 zsemamtic가 내포하는 정보를 활용하여 원본 영상의 세부 정보를 최대한 반영하도록 학습된다.전체 네트워크는 식 (1)과 같은 손실함수를 통해 최적화된다.
이때, ε은 실제로 추가된 노이즈, εθ는 (xt,t,zsemamtic)를 입력 받아 UNet[16] 기반의 네트워크가 예측한 노이즈를 의미한다. 손실함수는 모든 시점 t에서의 노이즈 예측 오차를 계산한 후 그 기댓값을 취함으로써, 네트워크가 전체 시점에 걸쳐 안정적으로 노이즈를 예측하도록 설계된다.
이러한 학습 구조는 디코더의 복원 성능을 향상시킬 뿐만 아니라, 원본 영상을 복원하는 데 필요한 핵심 정보들을 인코더가 잠재 벡터에 충분히 압축할 수 있도록 유도한다. 또한, 가우시안 노이즈 xT의 확률적 특성은 디코더가 보다 세밀한 정보를 반영함으로써 고해상도 영상 복원이 가능하게 한다. 결과적으로 복원된 영상의 품질이 향상될수록 인코더는 보다 풍부하고 의미 있는 영상 표현을 학습하게 되며, 이는 전립선암 악성도 예측을 위한 분류 모델의 성능 향상으로 이어질 수 있다.
2.2 다중 파라미터 MR 영상 특징 추출
전립선암 악성도는 단일 파라미터 MR 영상만으로는 정확한 예측하기 어려울 수 있으며, 이는 각 MR 파라미터 영상이 서로 다른 조직학적 및 기능적 정보를 포함하고 있기 때문이다. 이를 극복하기 위해, 다중 파라미터 MR 영상의 상호 보완적인 영상 정보를 종합하여 활용하는 것은 예측 모델의 성능 개선에 필수적이다. 기존 연구에서는 다중 파라미터 MR 영상을 단순히 채널 방향으로 병합(concatenate)하여 하나의 3채널 영상으로 구성한 후 단일 인코더를 통해 처리하는 방식이 사용되었다. 그러나 이 방식은 서로 상이한 영상 파라미터의 고유 정보가 인코딩 과정에서 혼합되어 희석되거나 손실될 가능성이 있으며, 이는 잠재적으로 모델의 예측 정확도를 저해할 수 있다. 본 논문에서는 이러한 한계를 극복하기 위해, 각 MR 파라미터의 고유한 정보를 개별 인코더로 추출하여 효과적으로 보존하고, 이들을 통합해 하나의 잠재 벡터를 형성하는 다중 파라미터 특징 추출(multi-parametric Feature Extraction, mp-FE) 방식을 제안한다.
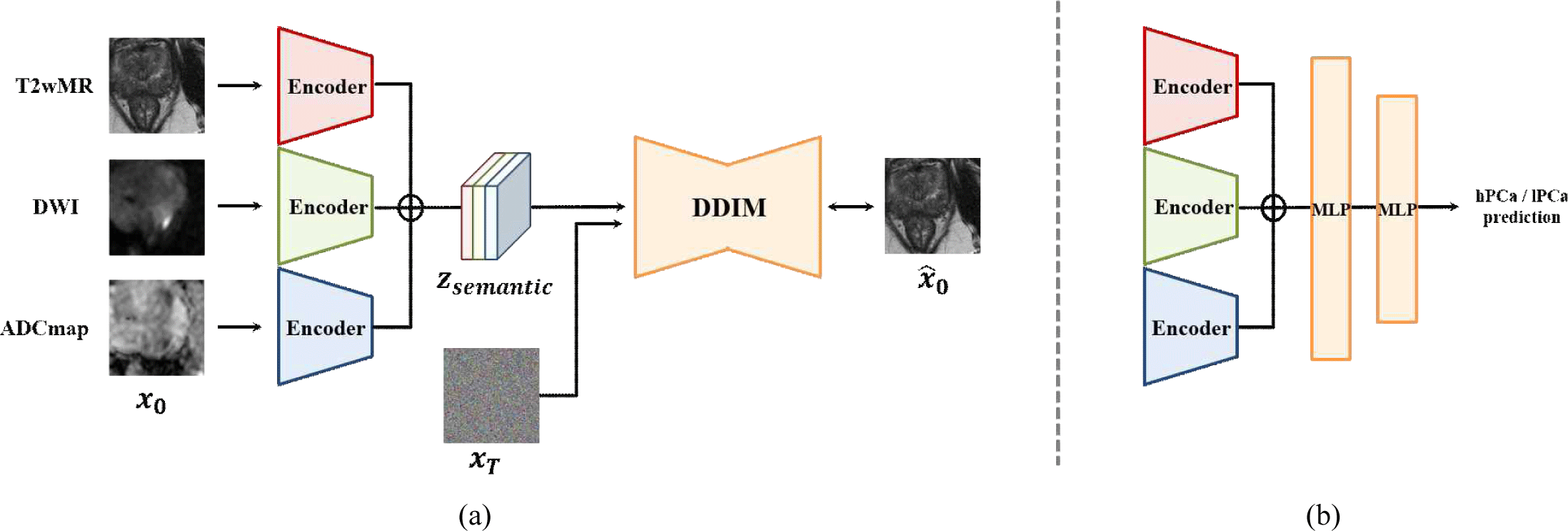
제안하는 mp-FE 구조는 그림 1(a)와 같이 각 MR 파라미터 영상에 대해 개별 인코더를 적용하여 독립적으로 특징 벡터를 추출한 후, 이를 채널 차원에서 연결하여 하나의 통합된 잠재 벡터 zsemamtic를 구성한다. 이 잠재 벡터는 확산 모델 기반 오토인코더의 디코더에 입력되어, 전립선 전반의 구조적 특징과 종양 부위의 세부 정보를 동시에 반영한 영상 복원을 가능하게 한다. 영상 복원 과정에서 디코더는 각 인코더가 추출한 파라미터별 고유 정보를 기반으로 고품질 영상을 재구성하게 되며, 이는 인코더가 원본 영상의 핵심 정보를 더 정확히 학습하도록 유도한다. 이와 같이 구성된 mp-FE 구조는 다중 파라미터 영상의 상호 보완적인 정보를 통합하면서도, 각 영상 파라미터의 고유 표현을 유지할 수 있도록 설계된다.
Figure 1.
Overview of the prostate cancer aggressiveness prediction framework based on a Diffusion Autoencoder with the multi-parametric Feature Extraction (mp-FE) method: (a) mp-FE with Diffusion Autoencoder, and (b) aggressiveness prediction network.
Download Original Figure
전립선암 악성도 예측을 위한 네트워크는 그림 1(b)와 같이 구성된다. mp-FE 구조에서 학습된 인코더로부터 추출된 잠재 벡터 zsemamtic는 두 개의 MLP(Multi-Layer Perceptron)를 거쳐 고위험군(hPCa)과 저위험군(lPCa)을 구분하는 이진 분류(binary classification)가 수행된다. 이러한 구조는 다중 파라미터 MR 영상의 세밀한 영상 정보를 내포한 잠재 벡터를 기 반으로 하여, 전립선암 악성도 예측 성능을 향상시킬 수 있다.
3. 실험 및 결과
본 논문의 실험을 위해 분당서울대병원으로부터 임상시험윤리위원회(IRB) 승인을 받아 구축된 SNUBPCa 데이터셋을 활용하였다. 해당 데이터셋은 전립선 특이항원(Prostate Specific Antigen, PSA)검사, 경직장 초음파, 직장수지 검사 등을 통해 전립선암으로 진단된 249명의 환자로부터 수집된 총 313개의 MR 영상으로 구성되어 있다. 영상 촬영은 Philips Achieva 3.0T MR 스캐너를 사용하여 이루어졌으며, DWI는 b-value가 1000s/mm2 조건에서 획득되었고, ADCmap은 b-value 0s/mm2과 1000s/mm2 영상으로부터 계산되었다. 전체 종양 중 저위험군은 글리슨 점수 3+3의 8개와 3+4의 166개로 총 174개, 고위험군은 4+3의 100개, 4+4의 16개, 4+5의 20개, 5+4의 3개로 총 139개로 구성되어 있다. 본 논문에서는 전체 데이터를 훈련 데이터 189개, 검증 데이터 72개, 테스트 데이터 52개로 나누어 사용하였다. 확산 모델 기반 오토인코더 학습 시에는 종양이 포함된 모든 슬라이스를 활용하였으나, 악성도 예측 시에는 각 종양에서 가장 큰 지름을 보이는 대표 슬라이스 1장씩만을 사용하였다. 모든 영상은 종양 중심 패치를 생성한 후, 최소-최대 정규화(min-max normalization)를 통해 환자 간 밝기 차이를 조정하였으며, 각 MR 파라미터 간 촬영 시점의 차이에 따른 움직임을 보정하기 위해 강체 정합(rigid registration)[17]을 수행하였다.
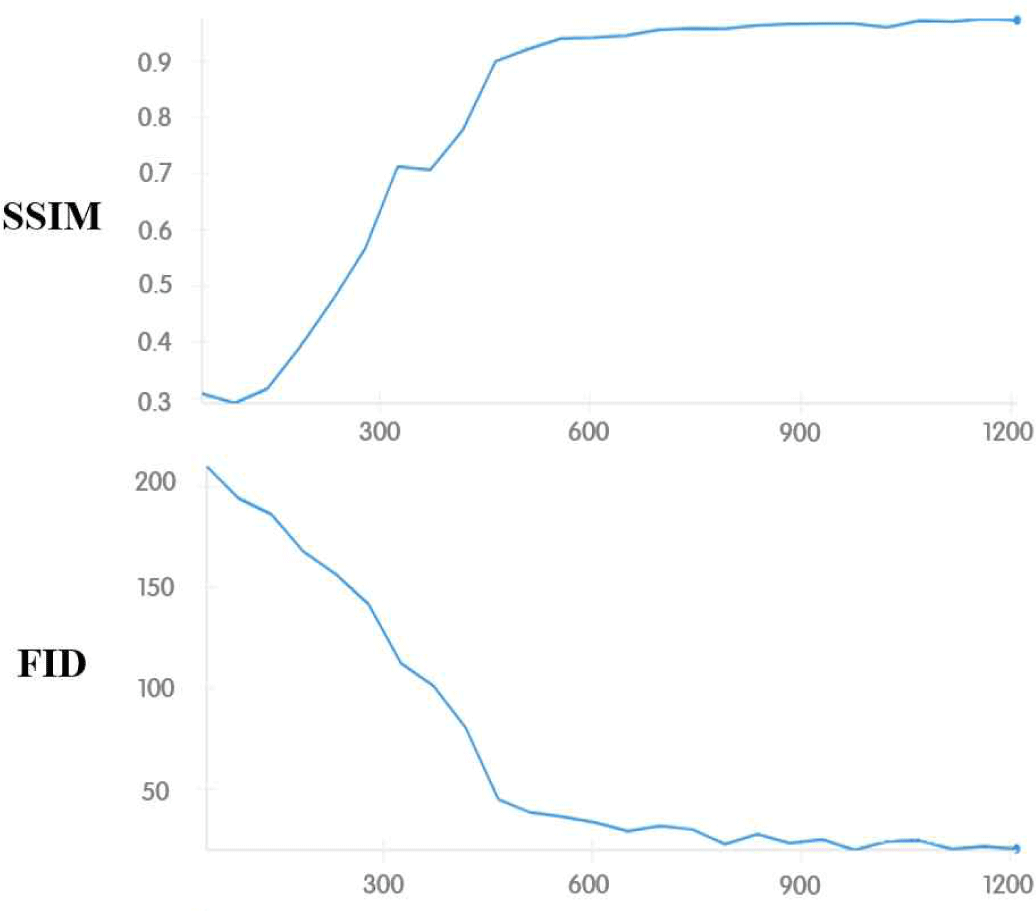
실험은 Python 및 Pytorch 환경에서 수행되었으며, NVIDIA RTX 3090 GPU 4개가 장착된 서버를 사용하였다. 모든 모델은 사전학습 없이 SNUBPCa 데이터셋으로 학습하였으며, 학습 시 배치 사이즈는 32, 학습률은 1e-4로 설정하였다. 확산 모델 기반 오토인코더의 경우, 그림 2와 같이 복원 영상의 SSIM이 약 0.97, FID가 약 17.5에 도달하는 시점에서 안정적으로 수렴하였으며, 해당 최적화 시점에서의 인코더를 예측 네트워크에 적용하였다.
Figure 2.
Training curves of the proposed Diffusion Autoencoder with multi-parametric Feature Extraction(mp-FE), showing SSIM and FID measured on the reconstructed DWI, along with the trajectory of the network’s loss function.
Download Original Figure
제안 방법과의 비교를 위해, 다중 파라미터 MR 영상을 3채널로 통합한 후 입력하는 기본 오토인코더 및 확산 모델 기반 오토인코더의 단일 인코더 방법과 제안 방법인 mp-FE 방식으로 전립선암 악성도를 예측한 결과를 제시한다. 이때 확산 모델 기반 오토인코더는 디코더 부분의 확산모델에서 T2wMR, DWI, ADCmap 중 하나의 영상을 복원한다. 평가 지표로는 정확도(accuracy), 민감도(sensitivity), 특이도(specificity), 양성예측도(Positive Predictive Value, PPV), 음성예측도(Negative Predictive Value, NPV), AUROC(Area Under the Receiver Operating Characteristic Curve)를 기준으로 수행되었으며, 각 결과는 5회 반복 실험의 평균으로 산출되었다. 기본 오토인코더와 확산 모델 기반 오토인코더의 잠재벡터 분포 분석을 위해 t-SNE(t-distributed Stochastic Neighbor Embedding)[18] 를 적용하였으며, 클래스별 군집화 정도를 실루엣 점수(Silhouette Score)[19]로 수치화하여 추가 제시하였다. 식 (2)의 실루엣 점수는 동일 클래스 내의 잠재 벡터 밀집도와 서로 다른 클래스 간의 분리도를 측정하고 이를 -1 과 1 사이의 값으로 정규화 하는 형태를 보이며, 1 에 가까울수록 군집화가 잘 되었음을 의미한다.
이 때, a(i)는 잠재 벡터 i가 속한 클래스 내의 다른 벡터들과의 거리 평균이며, b(i)는 잠재 벡터 i가 속하지 않은 다른 클래스의 벡터들과의 거리 평균을 의미한다.
또한 SHAP 분석[20]을 통해 각 MR 영상 특징이 예측 결과에 기여한 정도를 평가하였다.
표 1은 다중 파라미터 MR 영상 특징을 학습하는 방법에 따른 전립선암 악성도 예측 성능 결과이다. 실험 결과, 제안 방법은 다른 방법들에 비해 모든 지표에서 우수한 성능을 기록하였다. 특히, 기존 단일 인코더 구조 대비 정확도 5.48%, 민감도 8.57%, 특이도 2.94%, 양성예측도 6.21%, 음성예측도 5.04%, AUROC 0.04의 향상을 보였다. 또한, mp-FE가 적용되지 않은 오토인코더 대비 정확도 3.23%, 특이도 5.88%, 양성예측도 2.94%, 음성예측도 5.45%, AUROC 0.03 향상되었다. 이는 mp-FE 방법이 다중 파라미터 MR 영상의 고유 정보를 효과적으로 통합하고 보존함으로써 예측에 유용한 특징을 학습하도록 기여했음을 보여준다. 특히, 디코더의 복원 대상 영상에 따라 예측 성능의 차이가 존재하여 DWI 영상을 복원 대상으로 설정한 경우에서 정확도 70.97%, 특이도 79.41%, 양성예측도 70.83%, 음성예측도 71.05%, AUROC 0.72로 가장 우수한 성능을 나타냈다. 이는 DWI 영상이 종양 악성도와 관련된 영상 특징을 가장 효과적으로 반영했기 때문이라고 해석될 수 있다.
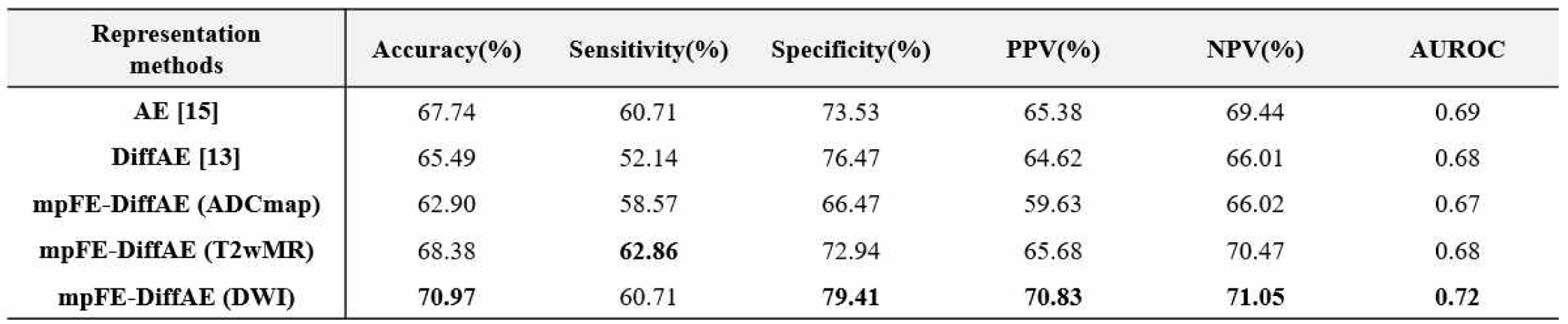
Table 1.
Evaluation of prostate cancer aggressiveness prediction using the proposed methods and comparison methods. The mean of prediction performance over 5 runs are presented. The highest values are denoted in bold.
AE : Autoencoder, DiffAE : Diffusion Autoencoder, mp-FE : multi-parametric Feature Extraction
그림 3은 기본 오토인코더와 확산 모델 기반 오토인코더를 통해 추출된 잠재 벡터의 분포를 t-SNE로 시각화한 결과이다. 기본 오토인코더 대비 확산 모델 기반 오토인코더는 실루엣 점수가 0.173점 향상하면서 고위험군과 저위험군 간 잠재 벡터의 분포가 더 명확히 분리되는 경향을 보였다. 이러한 결과는 확산 모델 기반 구조가 클래스 간 특징 구분력을 강화하고, 예측 정확도 향상에 기여함을 보여준다.
Figure 3.
Comparison of tSNE visualization and Silhouette scores (SS) of latent representations trained by the Autoencoder(AE, left) and the Diffusion Autoencoder (DiffAE, right).
Download Original Figure
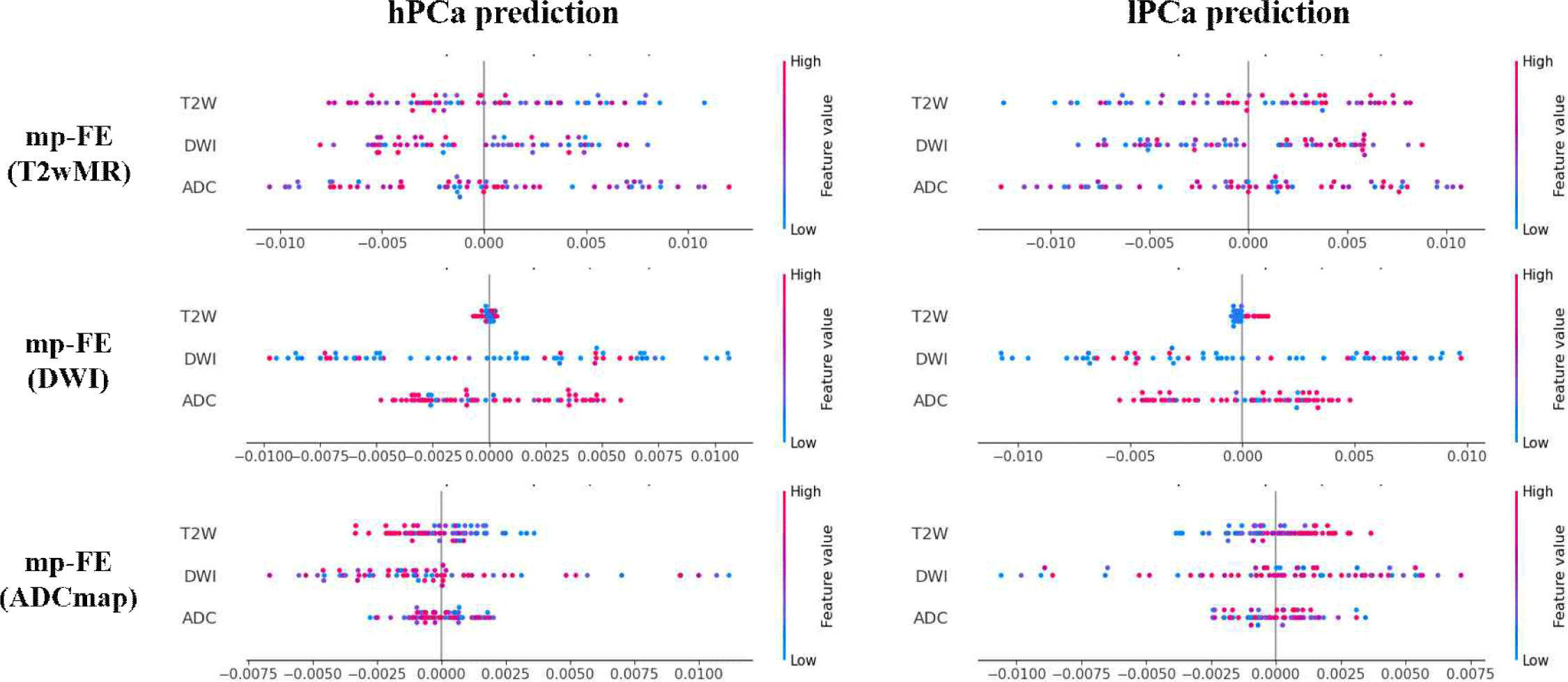
그림 4는 복원 대상으로 설정한 MR 영상에 따라 SHAP 값의 분포가 달라지는 양상을 보여준다. 분석 결과, DWI 또는 ADCmap을 복원 대상으로 할 경우 DWI 특징의 기여도가 다른 영상 대비 높은 SHAP 값을 보였으며, 이는 DWI 영상이 악성도 예측에 핵심적인 기여를 한다는 것을 나타낸다. 반면, T2wMR 영상을 복원 대상으로 설정하면 ADCmap 특징이 상대적으로 높은 기여도를 보였으며, 이는 복원 대상 선택이 잠재 벡터 구성뿐 아니라 최종 예측 성능에도 중요한 영향을 미칠 수 있는 설계 요소임을 의미한다.
Figure 4.
SHAP evaluation of high-grade PCa (hPCa) and low-grade PCa (lPCa) prediction based on target MR parameter reconstructed by the decoder in the multi-parametric Feature Extraction (mp-FE) method.
Download Original Figure
4. 결론
본 연구는 전립선암 악성도 예측을 위한 영상 특징 추출 방식으로, 확산 모델 기반 오토인코더와 다중 파라미터 MR 영상의 독립 인코딩 구조(mp-FE)를 결합한 새로운 프레임워크를 제안하였다. 제안된 확산 모델 기반 오토인코더는 고해상도 복원을 유도함으로써 인코더가 더욱 구조적이고 유의미한 잠재 벡터를 추출할 수 있도록 하였고, mp-FE 방법은 각 MR 영상의 고유 정보를 보존하면서 하나의 통합된 표현을 형성하여 예측 성능 향상에 기여하였다. 실험 결과, 특히 DWI 영상을 복원 대상으로 설정했을 때 가장 높은 예측 성능과 SHAP 기여도를 보였으며, 이는 DWI 영상이 전립선암 악성도 구분에 있어 핵심 정보를 포함하고 있음을 의미한다. 이러한 결과는 확산 기반 오토인코더가 의료 영상 분석에 효과적으로 적용될 수 있으며, 예측 성능 향상을 위해 복원 대상 영상의 전략적 선택과 다중 파라미터 MR 영상의 정보 조합 설계가 중요한 요인임을 강조한다. 그러나, 본 연구는 단일 기관의 데이터셋을 대상으로 수행되었다는 한계가 있다. 향후 연구에서는 대규모 공개 데이터셋 및 다기관 데이터를 활용하여 제안 방법의 일반화 가능성을 체계적으로 검증할 필요가 있다. 또한, 확산 오토인코더로부터 추출된 잠재 벡터의 분별력을 더욱 강화하기 위해 대조 학습(contrastive learning) 기법을 결합하고자 한다.
감사의 글
본 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원(No. RS-2023-00207947), 서울여자대학교 학술 연구비의 지원(2025-0215)을 받아 수행되었습니다.
References
F. Bray, J. Ferlay, I. Soerjomataram, R.L. Siegel, L.A. Torre, and A. Jemal, "Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries,"
CA Cancer J Clin., vol. 68, no. 6, pp. 394-424, 2018.

F.H. Schröder, J. Hugosson, M.J. Roobol, T.L. Tammela, S. Ciatto, and V. Nelen, “Screening and prostate-cancer mortality in a randomized European study,”
The New England Journal of Medicine, vol. 360, no. 13, pp. 1320–1328, 2009.
J.I. Epstein, L. Egevad, M.B. Amin, B. Delahunt, J.R. Srigley, and P.A. Humphrey, "The 2014 International Society of Urological Pathology (ISUP) consensus conference on gleason grading of prostatic carcinoma: definition of grading patterns and proposal for a new grading system,"
The American Journal of Surgical Pathology, vol. 40, no. 2, pp. 244-252, 2016.
F.B. Shin, E.C. Hwang, S.I. Jung, D.D. Kwon, K.S. Park, S.B. Ryu, and J.W. Kim, "Clinical features of bacteremia caused by ciprofloxacin-resistant bacteria after transrectal ultrasound-guided prostate biopsy,"
Urogenital Tract Infection, vol. 6, no. 1, pp. 61–66, 2011.
X. Li, Y. Ren, X. Jin, C. Lan, X. Wang, W. Zeng, X. Wang, and Z. Chen, "Diffusion models for image restoration and enhancement — a comprehensive survey,"
arXiv:2308.09388, 2023.
I.J. Goodfellow, et al., "Generative adversarial nets,"
Advances in Neural Information Processing Systems, vol. 27, pp. 2672–2680, 2014.
D.P. Kingma and M. Welling, "Auto-encoding variational bayes,"
arXiv:1312.6114, 2014.
J. Ho, A. Jain, and P. Abbeel, "Denoising diffusion probabilistic models,"
Advances in Neural Information Processing Systems, vol. 33, pp. 6840–6851, 2020.
J. Song, C. Meng, and S. Ermon, "Denoising diffusion implicit models,"
arXiv:2010.02502, 2020.
A. Kazerouni, et al., "Diffusion models for medical image analysis: A comprehensive survey,"
arXiv:2211.07804, 2022.
Y. Yang, H. Fu, A.I. Aviles-Rivero, C.B. Schönlieb, and L. Zhu, "Diffmic: Dual-guidance diffusion network for medical image classification,"
International Conference on Medical Image Computing and Computer-Assisted Intervention, pp. 95–105, 2023.
M. Atad, et al., "Counterfactual explanations for medical image classification and regression using diffusion autoencoder,"
arXiv:2408.01571, 2024.
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwajanakorn, "Diffusion autoencoders: Toward a meaningful and decodable representation,"
arXiv:2111.15640, 2021.
P. Busaranuvong, E. Agu, D. Kumar, S. Gautam, R.S. Fard, B. Tulu, and D. Strong, "Guided Conditional Diffusion Classifier (ConDiff) for enhanced prediction of infection in diabetic foot ulcers,"
IEEE Open Journal of Engineering in Medicine and Biology, 2024.
G.E. Hinton and R.R. Salakhutdinov, "Reducing the Dimensionality of Data with Neural Networks,"
Science, vol. 313, no. 5786, pp. 504–507, 2006.
O. Ronneberger, P. Fischer, and T. Brox, "U-net: Convolutional networks for biomedical image segmentation," International Conference on Medical Image Computing and Computer-Assisted Intervention, vol. 9351, pp. 234–241, 2015.
J. Jung, H. Hong, Y.G. Kim, S.I. Hwang, and H.J. Lee, "Prediction of prostate cancer aggressiveness using quantitative radiomic features using multi-parametric MRI," SPIE Medical Imaging 2020 Computer-Aided Diagnosis, No. 11314, 2020.
L. Van der Maaten and G. Hinton, "Visualizing data using t-SNE," Journal of Machine Learning Research, vol. 9, pp. 2579–2605, 2008.
P.J. Rousseeuw, "Silhouettes: A graphical aid to the interpretation and validation of cluster analysis," Journal of Computational and Applied Mathematics, vol. 20, pp. 53–65, 1987.
B. Rozemberczki, L. Watson, P. Bayer, H.T. Yang, O. Kiss, S. Nilsson, and R. Sarkar, "The shapley value in machine learning," Proceedings of the 31st International Joint Conference on Artificial Intelligence, pp. 5572–5579, 2022.
< 저 자 소 개 >
신 예 진

-
2023년 8월 서울여자대학교 디지털미디어 학과, 소프트웨어융합학과 졸업(학사)
-
2023년 9월~현재 서울여자대학교 컴퓨터학 과 소프트웨어융합전공 석사과정
-
관심분야: 의료 인공지능, 딥러닝, 영상분할, 영상처리
이 민 진

-
2007년 2월 서울여자대학교 컴퓨터학과 졸업(학사)
-
2016년 8월 서울여자대학교 컴퓨터학과 졸업(박사)
-
2016년 9월~현재 서울여자대학교 소프트웨어융합학과 초빙강의교수
-
관심분야: 의료 인공지능, 딥러닝, 영상처리, 영상정합
황 성 일

-
1996년 2월 서울대학교 의과대학 학사(학 사)
-
2005년 2월 강원대학교 의과대학원 졸업 (석사)
-
2009년 8월 서울대학교 의과대학원 졸업
-
2007년~현재 분당서울대병원 영상의학과 교수(세부 전공 : 비뇨생식기 영상의학)
-
관심분야: 전립선 영상, 인공지능 및 조직검사
홍 헬 렌

-
1994년 2월 이화여자대학교 전자계산학과 졸업(학사)
-
1996년 2월 이화여자대학교 전자계산학과 졸업(석사)
-
2001년 8월 이화여자대학교 컴퓨터학과 졸업(박사)
-
2001년 9월~2003년 7월 서울대학교 컴퓨터공학부 BK 조교수
-
2006년 3월~현재 서울여자대학교 소프트웨어융합학과 교수
-
관심분야: 의료 인공지능, 딥러닝, 영상처리 및 분석