
1 Introduction
Video generation has demonstrated remarkable progress in recent years. Breakthroughs in diffusion models [1] have enabled photorealistic video synthesis with exceptional temporal consistency. Google’s released Veo 3 [2] demonstrates impressive capabilities in generating high-quality video content. These technological advances have opened new possibilities for cinematic content creation, with synthetic video showing significant potential in film production workflows.
However, the current video generation encounters significant limitations in camera control. Users often struggle to implement specific camera trajectories or movements with the precision required for cinematic storytelling. Camera motion typically occurs arbitrarily during the generation process. More problematically, modifying the camera trajectory of already-generated videos remains impossible. This limitation forces creators to rely on trial- and-error approaches that require repeatedly generating videos until satisfactory results emerge, a process that is both time-consuming and resource-intensive.
Camera-controllable video generation models have emerged to address these fundamental issues. However, these approaches still suffer from serious constraints that limit practical utility in professional contexts. First, precise camera control remains impossible. The functionality remains limited to operating within a few presets only. Second, the length of generatable videos remains limited to 5 seconds. The limitation makes the models unsuitable for creating long-take footage required in films. The limitation creates barriers for creators seeking to implement complex visual expressions.
To solve the problems, we propose a framework that simultaneously supports infinite-length video generation and customizable camera movements. Our framework enables filmmakers to create cinematic content using standardized camera presets and custom trajectories tailored to specific creative requirements, as illustrated in Fig. 1. Our approach provides the following key contributions:
-
We propose an infinite video generation framework that enables the creation of extended cinematic sequences and long-take shots.
-
We develop a customizable trajectory system with precise control over camera path and speed derived from film production.
-
We introduce camera presets that provide standard camera movements for filmmakers.
-
We demonstrate the practical applicability of our framework across diverse content types and cinematographic scenarios.

2 Related Works
Video generation has experienced rapid advancement in recent years. The initial approaches combined 2D spatial processing with 1D temporal modeling [3, 4, 5], then evolved into 3D attention mechanisms [6, 7]. Key architectural advances include the transition from U-Net [8] to DiT [9] and MMDiT [10] architectures. Furthermore, optimization strategies have evolved from DDPM approaches [1, 11] to flow matching methodologies [12, 13].
Variational auto-encoders (VAEs) have improved along with text encoding capabilities [14, 15, 16]. Advanced vision-language models, such as BLIP [17] and LLaVA [18], have significantly improved automated video descriptions and enabled more accurate text-to-video generation. Despite these improvements in video fidelity, current systems still face significant challenges for commercial deployment, primarily due to limited user control over camera viewpoints and scene composition.
Recent commercial video generation systems have demonstrated impressive capabilities in automated content creation [19, 20, 21]. However, these systems primarily focus on text-driven generation with limited user control over specific cinematic aspects such as camera movements and scene composition. While some commercial tools offer basic camera presets, they provide only approximations of cinematic movements without fine-grained control over trajectory parameters such as movement intensity, speed variation, or precise spatial positioning. The gap between automated generation capabilities and precise creative control remains a significant challenge for professional filmmaking, where directors require exact camera trajectories.
Camera-controlled video generation has emerged as a critical research area following the success of text-to-video models [7, 22, 23]. Early methods achieve basic camera control through highlevel instructions. MovieGen [24] uses text descriptions to control camera motion, while MCDiff [25] and DragNUWA [26] enable control through user-provided strokes. AnimateDiff [4] introduces motion LoRAs [27] to learn camera movement patterns from augmented datasets.
Recent approaches focus on control using camera parameters as conditional input. MotionCtrl [28] directly injects 6 DoF camera extrinsic into diffusion models through fine-tuning on videocamera pair datasets. CameraCtrl [29] employs specialized encoding to represent camera origin and ray directions with improved accuracy. CVD [30] proposes cross-video synchronization modules, and AC3D [31] investigates camera motion knowledge within diffusion transformers.
Recent camera-controllable re-generation enables capturing dynamic scenes from source videos with specified camera trajectories. ReCamMaster [32] uses token concatenation for cameracontrolled scene reproduction, while TrajectoryCrafter [33] employs a dual-stream diffusion model that combines point cloud renders and source videos. However, existing methods face critical limitations as they depend on user-provided strokes or predefined camera presets, preventing accurate trajectory re-rendering for specific user requirements. Additionally, generated videos remain limited to short durations, making them unsuitable for long-take applications required in professional film production.
3 Preliminaries
Video diffusion models [5, 6] operate in the latent space using a VAE to encode video frames into lower-dimensional representations. Given a video sequence , a pretrained VAE ε maps frames to latent representations z0 = ε(I). The diffusion process corrupts the latent representation by adding Gaussian noise:
where α̅t controls the noise schedule and t denotes the diffusion timestep.
Masked video diffusion enables selective conditioning on visible frames while generating masked regions. Given a binary mask sequence that indicates frame visibility, we compute the masked latent code as:
where ⊙ denotes element-wise multiplication. During diffusion, the denoising network reconstructs content in masked regions while preserving visible frame information. This approach generates content in occluded and future regions to enable infinite video generation with precise camera control.
4 Method
Our proposed method enables precise trajectory control over longform video generation through a recurrent process. Our approach consists of two main components: video reprojection for novel view synthesis and video prediction for future frames. We adopt TrajectoryCrafter [33] as the base model for video reprojection and Seine [34] as the base model for video prediction. Fig. 2 shows an overview of our framework.
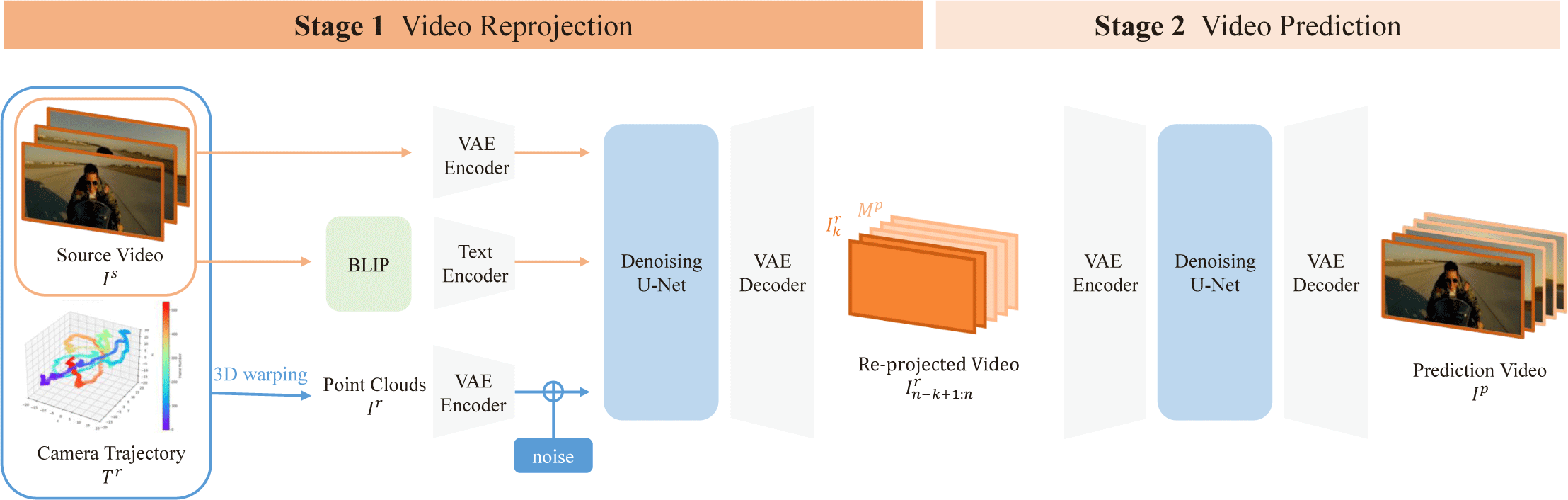
The video reprojection module converts source videos to novel viewpoints through depth-driven geometric rendering and masked diffusion. Given a source video , we initial calculate depth maps [35]. We then construct a point cloud sequence by applying inverse perspective projection:
where Φ−1 represents the inverse perspective projection, and K ∈ ℝ3×3 denotes the camera intrinsic matrix. Using this point cloud, we render novel views following a specified camera trajectory :
where Φ performs the perspective projection. Since point cloud reconstruction occurs within the coordinate frame of the source camera, represents the transformation matrix relative to the initial viewpoint. The projected rendered images Ir contain visible gaps due to occlusion effects and boundary limitations, which the module identifies through mask sequences .
The camera trajectory Tr can be specified through two approaches: user-provided c2w matrices from external camera tracking systems, or predefined camera movement presets. For preset-based generation, we implement 12 standard cinematographic movements through parameterized transformations of the initial camera pose. Rotational presets (pan, tilt, arc) apply Euler angle rotations with angular range θmax = α · s, where α is the base rotation angle specific to each movement type and s is the intensity parameter. Translational presets (dolly, translation) apply linear displacement with magnitude dmax = βr · s, where r represents the scene radius estimated from depth maps and β is a preset-specific scaling factor. Zoom presets operate by modifying the camera intrinsic matrix K through focal length interpolation while maintaining fixed spatial position. Each trajectory frame is computed as , where R and T denote rotation and translation matrices with parameters linearly interpolated across frames.
Although s technically represents movement intensity or range rather than temporal speed, it effectively controls the visual perception of camera velocity. The actual perceived speed results from the combination of s and the total number of frames n, where identical intensity values produce faster motion with fewer frames and slower motion with more frames. Low intensity values produce subtle, cinematic motions suitable for dramatic scenes, while high values create dynamic, energetic camera work for action sequences. We apply the intensity scaling uniformly across all trajectory points to maintain geometric consistency while achieving the desired visual dynamics.
The reprojection module utilizes Ir and Mr as conditioning inputs to guide video synthesis following the camera trajectory. The projected views Ir and the occlusion masks Mr provide spatial constraints, while the source sequence Is provides appearance details via a reference-conditioning diffusion architecture. This architecture incorporates cross-attention layers that connect the projected content with the source material, thereby preserving visual consistency throughout the viewpoint transformation.
The video prediction module extends the reprojected sequence temporally using masked diffusion. Taking the final k frames from the reprojected sequence, we form an N -frame input sequence where the first k frames provide conditioning and the remaining N − k frames are predicted by the module. The input sequence undergoes encoding using a pre-trained VAE to obtain latent representations. Subsequently, we selectively condition on visible frames while predicting masked regions. To enable conditional generation, we apply binary masks where conditioning frames are visible ( for i = 1, ..., k) and target frames are masked ( for i = k+1, ..., N ). The diffusion model then generates the masked future frames while conditioning on the visible context from the reprojection stage.
Once the video prediction module generates the extended sequence , this predicted output serves as the new input source video for the subsequent reprojection stage. The frame-work then processes the predicted frames Ip through the video reprojection pipeline described in Section 4.1. This recurrent alternation between temporal extension and spatial reprojection enables our framework to generate long-form videos while maintaining precise control over the camera trajectory throughout the entire sequence.
The recurrent process terminates based on a predetermined frame count specified by the user. Given a target video length of F frames and the reprojection module output of n frames per cycle, our framework calculates the required number of iterations as , where N − k represents the number of newly predicted frames per cycle. This deterministic termination ensures precise control over the final video length while maintaining computational efficiency and predictability.
5 Experiments
Dataset. For camera trajectory data, we utilized trajectories captured during real film and drama productions. We obtained trajectories using filming and tracking equipment that provides precise camera motion parameters, including position, rotation, and intrinsic parameters. We collect distinct camera trajectories covering various motion patterns such as drone shots, crane movements, and handheld camera work from our original footage of Along with the Gods, The Haunted Palace, and Head over Heels.
For source video data, we constructed a diverse test dataset consisting of 30 video clips from three different sources: (1) 10 movie clips, (2) 10 real-world videos, and (3) 10 synthetic videos. The movie clips include scenes from our original footage and trailers from Top Gun and Toy Story. The real-world videos include sequences rendered from Google Earth Studio [36], and clips captured from Around The World 4K [37]. The synthetic videos are generated by Luma AI [21].
Implementation. We implemented our method using PyTorch [38] and performed all experiments on a single NVIDIA A100 GPU. We adopt TrajectoryCrafter [33] and Seine [34] as the base models. Our method does not require additional training beyond these pretrained models. During inference, the framework requires at least 28GB of VRAM to process 49-frame sequences. In our recurrent pipeline, we set the number of conditioning frames to k = 5. For camera trajectory visualization in our experiments, we utilize CameraCtrl [29] to render the camera paths and movements.
Fig. 3 demonstrates our trajectory mapping method using camera movements from real film production. We apply these trajectories to three different target videos: synthetic room scenes (Luma AI), aerial urban scenes (Google Earth Studio), and natural landscapes (Around The World 4K). The 3D plots show camera positions throughout each trajectory, with color gradients indicating temporal progression and cones marking camera orientation. Our approach excels at capturing and reproducing subtle cinematic motions that are important in professional filmmaking. The synthetic room scenes and aerial urban scenes particularly demonstrate our ability to handle fine-grained camera adjustments, such as gentle drift, micro-movements, and gradual transitions. Our method successfully transfers both pronounced and nuanced camera dynamics across diverse content types while preserving the original motion timing. This capability enables more sophisticated cinematic expression compared to previous approaches that primarily emphasize visually striking camera motions.

Fig. 4 presents the camera preset-based video generation results. We generate videos using predefined camera presets that correspond to standard cinematic movements. The results demonstrate how each preset creates distinct visual effects while maintaining content consistency. The pink-highlighted sections indicate frames generated by the prediction module using camera presets. This approach enables filmmakers to achieve camera work without requiring complex manual trajectory specifications. Fig. 5 illustrates the effect of speed parameters on pan movement execution. We apply three speed settings (0.1, 1.0 and 10) to identical pan trajectories, effectively showing how speed control enables fine-tuning of movement dynamics while preserving spatial accuracy and trajectory fidelity. The results highlight the system’s ability to generate both cinematic slow and rapid camera movements from the same preset configuration.


Tab. 1 demonstrates the capabilities of our method in video regeneration. For the number of frames, our approach supports unlimited renderable frames, far exceeding GCD [39] (14 frames), TrajectoryCrafter [33] (49 frames), and ReCamMaster [32] (81 frames). For the number of camera presets, our method offers 12 presets (e.g., zoom in/out, dolly in/out, translation up/down, tilt up/down, pan left/right, and arc left/right), outperforming GCD (0 presets), TrajectoryCrafter (3 presets), and ReCamMaster (10 presets). For speed control, our method is the only one that supports dynamic adjustment of camera movement speed, allowing users to accelerate or decelerate camera motions as needed.
| Method | # Frames | # Camera Presets | Intensity Control |
|---|---|---|---|
| GCD [39] | 14 | 0 | |
| TrajectoryCrafter [33] | 49 | 3 | |
| ReCamMaster [32] | 81 | 10 | |
| Ours | ∞ | 12 | ✓ |
To quantitatively evaluate temporal consistency, we measure frame-to-frame coherence using CLIP similarity [41] and LPIPS [42] metrics. We apply identical source videos and camera trajectories across all methods. As shown in Tab. 2, our method achieves superior temporal consistency with CLIP similarity of 0.9575 and LPIPS of 0.0409. Our method builds upon TrajectoryCrafter for video reprojection and extends the framework to infinite-length generation through recurrent prediction.
| Method | CLIP Similarity ↑ | LPIPS ↓ |
|---|---|---|
| GCD [39] | 0.7831 | 0.2810 |
| ViewCrafter [40] | 0.8919 | 0.1209 |
| ReCamMaster [32] | 0.9341 | 0.0631 |
| Ours | 0.9575 | 0.0409 |
6 Discussion
While our method successfully generates long-form videos with precise camera trajectory control, we observe certain limitations as video duration increases. As the generation process extends through multiple recurrent cycles, the visual content gradually diverges from the source video due to accumulated variations in each reprojection-prediction cycle. This divergence becomes more pronounced with longer durations, as the model progressively relies less on the initial visual context and more heavily on text prompt guidance. In extended sequences, the text prompt becomes the primary semantic anchor, while the source video’s influence diminishes. Consequently, while camera trajectories remain accurately controlled, the visual content may evolve beyond the original scene’s characteristics, resulting in semantic drift from the initial visual reference.
To address this limitation, future work could implement a 3D scene system that accumulates point clouds from previous reprojection stages. Currently, our video prediction module only conditions the most recent k frames, leading to gradual content drift from the source video. A more robust approach would maintain a 3D scene representation by storing and integrating point clouds generated throughout the entire sequence. When predicting future frames, the system would leverage this accumulated 3D knowledge to identify existing scene geometry and only generate point clouds for newly visible or occluded regions. This approach would construct a progressive 3D scene reconstruction as the camera moves, enabling more consistent 2D rendering that preserves the original scene’s spatial and semantic characteristics. Particularly in loop closure scenarios where the camera returns to its starting point, accumulated geometric drift may cause spatial inconsistencies between the initial and final frames, requiring global optimization mechanisms to ensure 3D coherence across the entire trajectory. Such a scene-aware framework would maintain stronger visual coherence with the source content while still enabling unlimitedlength generation with precise camera control.
7 Conclusion
We present a video generation framework that addresses two fundamental challenges in current video synthesis, specifically limited sequence length and insufficient camera control. Our method generates unlimited-length videos with precise trajectory control by leveraging real film camera movements through a recurrent alternation between video reprojection and temporal prediction. The system provides 12 standard camera presets that cover professional cinematographic movements with dynamic intensity control, demonstrating robust performance across diverse content domains, from synthetic scenes to real-world footage. This approach successfully bridges traditional filmmaking techniques with AI-driven video synthesis, enabling authentic reproduction of cinematic motion while maintaining temporal consistency.
This study opens significant possibilities for the film industry and content creation more broadly. Our framework enables cost-effective film previsualization and rapid prototyping of cinematic sequences, potentially democratizing high-quality video production tools. By establishing a connection between professional cinematography and synthetic video generation, we expand creative possibilities and lay the groundwork for professional-grade AI video tools. While challenges such as semantic drift in extended sequences present opportunities for future research, our approach represents a crucial step toward sophisticated camera-controlled video synthesis systems that can meet the evolving demands of modern content creation workflows.


