
1. Introduction
Roadside pedestrian accidents often occur when a pedestrian suddenly emerges from behind a parked vehicle before sufficient visual evidence becomes available to onboard perception modules. This risk is particularly high in dense roadside-parking environments, where only a narrow under-vehicle gap may reveal limited lower-limb cues.
Existing pose estimators and occlusion-recovery methods do not directly address full-body silhouette reconstruction from extremely sparse under-vehicle observations [1, 2]. In parallel, ghostprobe approaches primarily focus on hazard-zone prediction rather than explicit shape-level recovery from partial visual evidence. This leaves a practical gap between visible-cue detection and reconstruction-oriented reasoning for severely occluded pedestrians.
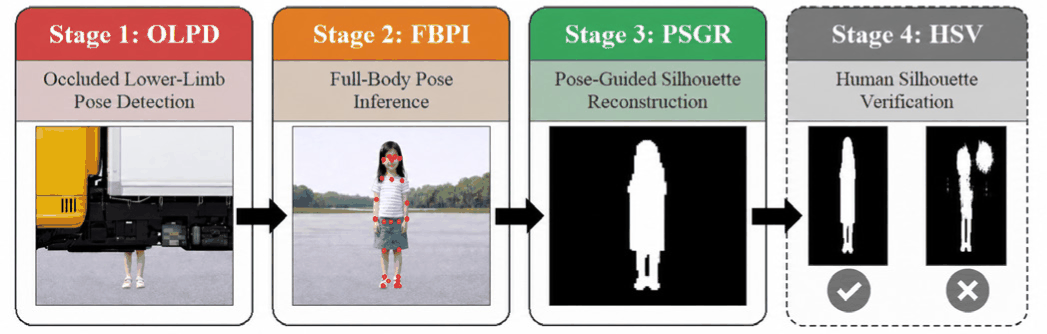
We propose a pose-guided reconstruction framework whose implemented and evaluated pipeline comprises OLPD, FBPI, and PGSR for recovering full-body structure and silhouette from sparse lower-limb cues beneath parked vehicles. A separate HSV stage is treated only as a prospective future extension and is not implemented or evaluated in this paper.
The main contributions are as follows. First, we formulate partial under-vehicle pedestrian visibility as a pose-guided reconstruction problem. Second, we introduce an implemented three-stage cascade for recovering full-body pose and silhouette from sparse lower-limb cues. Third, we introduce MRV to quantify occlusion tolerance. Fourth, we construct a synthetic paired dataset for controlled evaluation.
2. Related Work
OpenPose (Cao et al., 2017) and CrowdPose (Li et al., 2019) provide the visible-keypoint estimation foundation of our framework [1, 2]. More recent work has pushed pose and mesh reasoning under occlusion by explicitly modeling part visibility, spatial context, diffusion priors, or richer whole-body structure. For example, PARE uses body-part-guided attention to improve 3D human body estimation under partial occlusion [3]; visibility-aware transformer reasoning improves 2D pose estimation under occlusion by suppressing unreliable occluder features [4]; Occluded Human Mesh Recovery (OCHMR) augments top-down mesh recovery with spatial context for person-person occlusion [5]; AiOS moves toward an all-in-one-stage expressive pose-and-shape pipeline without an external detector [6]; DPMesh exploits diffusion priors for occluded human mesh recovery [7]; and ScoreHMR uses score-guided diffusion for 3D human recovery across several inverse-problem settings [8]. These studies demonstrate strong recovery capability when broader human extent and richer contextual evidence are available. However, they are not direct one-to-one solutions for the present setting, because our target problem is under-vehicle occlusion with only minimal lower-limb cues and a lightweight staged reconstruction output of full-body keypoints and silhouette probability masks rather than full 3D meshes.
In the KCGS literature, K-SMPL, silhouette-driven human-shape estimation, sensor-based motion reconstruction, and low-cost interactive motion-capture systems provide useful representation- and motion-level context [9, 10, 11, 12], but they are not designed for under-vehicle occlusion or minimal lower-limb cue recovery.
Human de-occlusion and amodal completion address the inference of invisible structure behind occluders. Earlier human-specific work includes object-occluded human shape and pose recovery [13], human de-occlusion with invisible-mask and appearance recovery [14], and 2D pose-guided complete silhouette estimation for occluded human bodies [15]. Subsequent work has expanded both realism and scope: OccNeRF studies human rendering from object-occluded monocular videos using geometry and visibility priors [16]; Amodal Completion via Progressive Mixed Context Diffusion uses context-guided diffusion for completion [17]; pix2gestalt synthesizes wholes for zero-shot amodal segmentation [18]; and Amodal Ground Truth and Completion in the Wild broadens amodal benchmarking and completion in real images [19]. Complementary visible-mask extraction backbones such as Mask2Former and SAM strengthen general-purpose segmentation quality [20, 21]. These methods are highly relevant because they infer invisible masks, shapes, or appearance from partial observations or strengthen the visible mask extraction on which downstream completion may depend. Nevertheless, most of them target generic amodal or appearance completion, broader segmentation, or settings with richer visible context than ours, and are not explicitly formulated as lightweight staged reconstruction from minimal lower-limb cues under under-vehicle occlusion.
A closer family to FBPI is pose completion from partial observations. SDR-GAIN targets high-real-time occluded pedestrian pose completion for autonomous driving [22]; LInKs adopts a lift-then-fill strategy for partial-pose lifting under occlusion [23]; Cross-view and Cross-pose Completion studies missing-pose recovery for 3D human understanding [24]; and HiPART performs hierarchical densification for occluded 3D pose estimation while improving robustness and computational efficiency relative to heavier generative alternatives [25]. These works are important because they show that missing skeletal structure can be inferred from incomplete pose evidence. However, prior pose-completion methods generally target 3D lifting or broader partial-body settings rather than the present combination of under-vehicle occlusion, minimal lower-limb cues, and lightweight staged reconstruction. By contrast, our pipeline explicitly decomposes the task into OLPD, FBPI, and PGSR so that visible-cue extraction, keypoint inference, and silhouette reconstruction remain modular. This decomposition is not presented as outperforming prior completion families; rather, it targets a narrower deployment-motivated regime in which only limited under-vehicle evidence is available. Consistent with the rest of the paper, OLPD results are interpreted only as mask-given synthetic upper-bound filtering under a known occlusion mask, FBPI metrics are interpreted as consistency with paired OpenPose reference poses rather than manual human pose accuracy, and the current validation remains synthetic and child-pedestrian-limited.
In traffic-safety research, occlusion is often addressed as a ghostprobe or hazard-prediction problem rather than as explicit human reconstruction. DPGP: A Hybrid 2D-3D Dual Path Potential Ghost Probe Zone Prediction Framework for Safe Autonomous Driving (Qu et al., 2025), for example, addresses ghost-probe zone prediction while emphasizing the practical cost of specialized sensors and computation [26]. This line of work is highly relevant because it treats occlusion as a safety-critical perception problem. However, the target output differs from ours: ghost-probe methods typically predict risk zones, motion intent, or warning cues, whereas the present study focuses on reconstructing full-body keypoints and a silhouette probability mask from minimal lower-limb cues under under-vehicle occlusion. Our method should therefore be viewed as complementary to traffic-safety occlusion reasoning rather than as a replacement for end-to-end warning systems.
3. Method
To address the target problem, we introduce a pose-guided reconstruction framework that separates the implemented pipeline from a prospective future extension. The implemented and evaluated pipeline consists of OLPD, FBPI, and PGSR. A separate HSV stage is discussed in Section 3.4 only as a future extension and is not part of the implemented or evaluated system in this paper.
In Fig. 1, only the OLPD–FBPI–PGSR path belongs to the implemented pipeline, whereas HSV is shown separately as a prospective future extension.
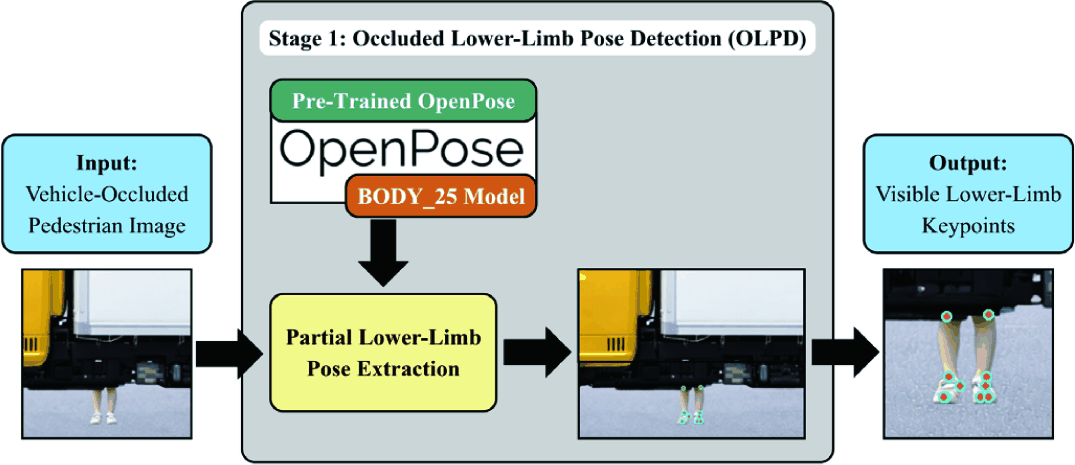
In the first stage, termed Occluded Lower-Limb Pose Detection (OLPD), the goal is to extract only observable lower-limb cues from vehicle-occluded pedestrian images, where most of the body is hidden by a vehicle and only a small portion of the legs is visible through the under-vehicle gap. To this end, we apply a pre-trained OpenPose BODY 25 model to the full input image without additional fine-tuning.
In the current synthetic dataset, the vehicle layer mask is directly available from the compositing process and is used as the occlusion mask in OLPD. Joints that fall inside this vehicle-occluded region are removed before retaining the visible lower-limb subset. The estimated 2D pose is then passed to partial lower-limb pose extraction, which retains only the visible lower-limb joints defined in BODY 25. The final output is a partial pose representation expressed as visible lower-limb keypoints. Because upperbody evidence is mostly unavailable in this setting, OLPD acts as a preprocessing stage that stabilizes downstream inference by isolating these limited yet reliable lower-limb observations for the next stage. In the current implementation, OLPD assumes access to the synthetic vehicle-layer mask produced by the compositing pipeline. Therefore, OLPD results do not measure automatic vehicle segmentation or deployment-time perception. Accordingly, any reported OLPD success rate should be interpreted as a mask-given synthetic upper-bound for lower-limb keypoint filtering under a known occlusion mask. Any OLPD-related latency reported later refers only to keypoint filtering after OpenPose outputs are available; it does not measure OpenPose BODY 25 inference itself. Section 4.2 separately discusses the oracle-mask setting that uses the synthetic vehicle-layer mask and an illustrative predicted-mask setting that substitutes an externally estimated mask for qualitative comparison only.
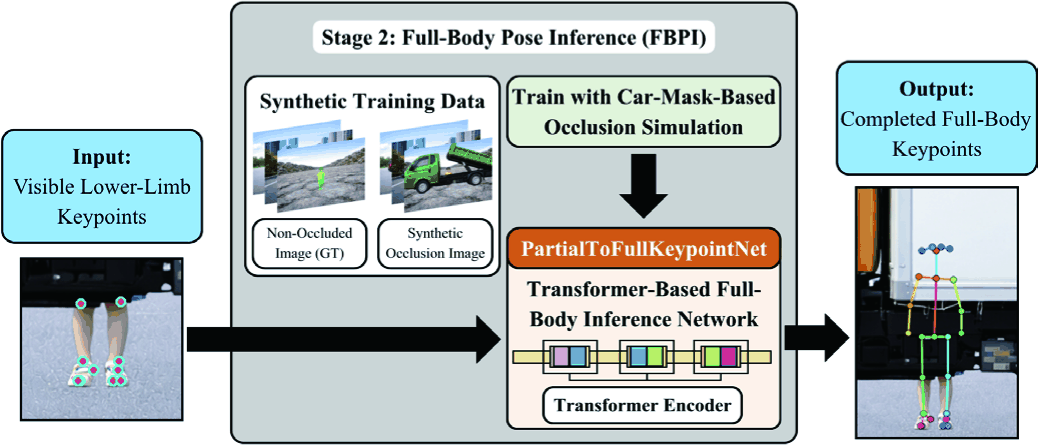
In the second stage, termed Full-Body Pose Inference (FBPI), the objective is to reconstruct a complete human pose from the sparse lower-limb observations extracted in Stage 1. As illustrated in Fig. 3, the module takes visible lower-limb keypoints as input and predicts completed full-body keypoints through PartialToFullKeypointNet. To train this module, paired synthetic samples were constructed using two image versions of the same scene: a non-occluded reference image and a synthetic occlusion image generated by car-mask-based composition. Specifically, the dataset was created using Gemini-based image generation followed by manual three-layer composition of background, pedestrian, and vehicle elements. A total of 1,000 paired samples were prepared and split into 800 training, 100 validation, and 100 test samples at the paired-sample-ID level. The occluded image and the non-occluded reference image from the same pair were always assigned to the same split. In the current dataset, paired sample IDs were ordered by index and then partitioned into the 800/100/100 split without separating the two images of a pair. For each pair, OpenPose was applied to both the non-occluded image and the synthetically occluded image. The pose detected from the synthetically occluded image was used as the partial input, whereas the pose detected from the corresponding non-occluded image was used as the paired OpenPose reference pose for full-body keypoint inference. The target full-body keypoints are not manually annotated human pose ground truth. They are OpenPose BODY 25 outputs extracted from the paired non-occluded reference image. Therefore, FBPI learns to predict keypoints consistent with the paired OpenPose reference pose rather than with manual keypoint annotation.
Let the partial pose estimated from the occluded image be denoted by
where xj, yj, and cj denote the normalized 2D coordinates and confidence of the j-th BODY 25 joint. The coordinates are normalized with respect to the image width W and height H as
In addition, a binary visibility vector
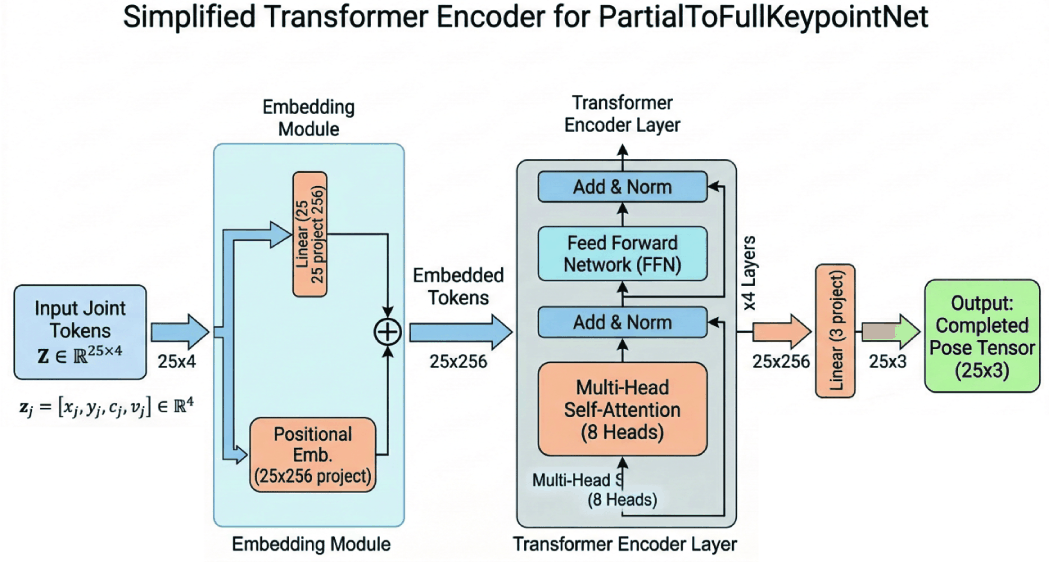
is used to indicate whether each joint remains observable after occlusion masking. For occluded joints, the corresponding entries are set to xj = 0, yj = 0, cj = 0, and vj = 0. Therefore, the model always receives a fixed-size pose structure with 25 joint slots, while the effective amount of valid information varies depending on the number of visible lower-limb joints in each sample.
For each joint, the input token is constructed by concatenating coordinate, confidence, and visibility information:
These 25 input joint tokens are then projected into a latent space and processed by a transformer encoder with learnable joint positional embeddings. As shown in Fig. 4, the FBPI network, referred to as PartialToFullKeypointNet, is implemented as a transformer-based full-body inference network with hidden dimension 256, 4 transformer encoder layers, 8 attention heads, feedforward dimension 1024, GELU activation, and dropout rate 0.1 [27]. The network outputs a completed full-body pose
Although the output tensor has shape 25 × 3, the training objective focuses on coordinate regression against the OpenPose-derived reference pose for the completed pose. Let
where is taken from the paired OpenPose reference pose extracted from the non-occluded image. The default training loss is then a confidence-weighted L1 loss with respect to this OpenPose-derived reference pose:
Thus, higher-confidence reference joints contribute more to the loss. Confidence and visibility are not supervised separately; visibility is used only to mark observed versus missing joints at the input. Accordingly, FBPI should be interpreted as consistency with the paired OpenPose reference pose rather than as direct human pose accuracy.
To preserve reliable observations while only hallucinating missing parts, the final completed pose Y is obtained by residual fusion between the original partial pose and the predicted pose:
This formulation preserves visible joints and predicts only occluded ones. After completion, reconstructed occluded joints are assigned confidence 1 before the pose is passed to the next stage. The current experiments are limited to single-person samples; multi-person extension remains future work. A transformer encoder is used to model long-range dependencies between visible lower-limb joints and missing upper-body joints within a fixed skeletal topology.
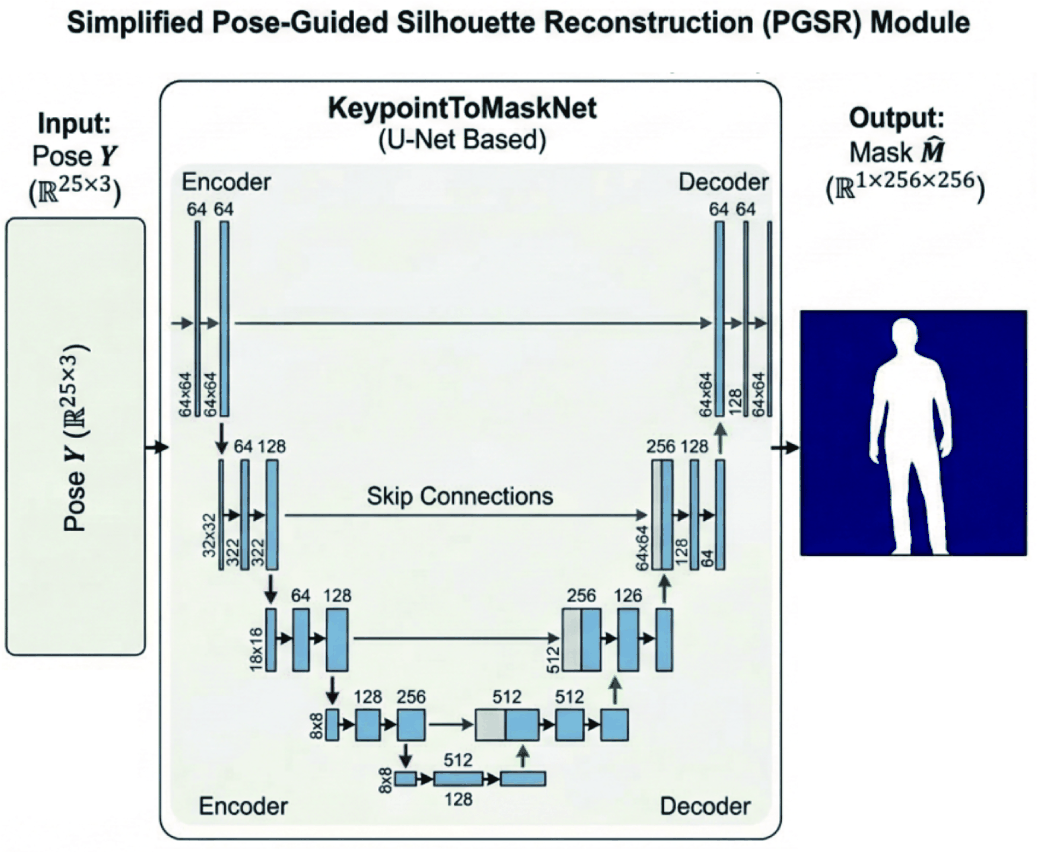
In the third stage, Pose-Guided Silhouette Reconstruction (PGSR) recovers a full human silhouette mask from the completed full-body pose without RGB appearance cues. The implemented KeypointToMaskNet is a U-Net-based keypoint-to-mask network [28] trained on paired OpenPose reference poses from the non-occluded image and the corresponding manually isolated silhouette masks, while inference uses only the completed pose predicted by FBPI. Because training uses cleaner reference poses whereas inference uses FBPI outputs, PGSR should be interpreted as a pose-conditioned upper-bound with respect to pose-input quality.
Let the completed full-body pose passed from FBPI at inference time be denoted by
where xj, yj, and cj are the normalized 2D coordinates and confidence of the j-th BODY 25 joint. The stacked pose matrix is written as
During PGSR training, however, the implemented model uses the paired OpenPose reference full-body pose from the non-occluded image, denoted by Yref ∈ ℝ25×3, rather than the residual-fused FBPI output Y. At the level preserved by the surviving experiment record, the pose-conditioned PGSR mapping can be written as
Here, P = Yref during training and P = Y during inference. The network follows a U-Net-style encoder-decoder topology with skip connections, base channel width 64, and a final sigmoid output at 256 × 256 resolution. The silhouette mask is a supervision target only; it is not part of the inference input. However, the surviving manuscript assets do not preserve the exact internal tensor-to-spatial projection that converts the 25 × 3 pose representation into the first spatial feature map consumed by the encoder. Therefore, the current paper documents PGSR at the level of pose conditioning, U-Net-style topology, and output resolution, but not as a fully layer-by-layer reproducible architecture specification. Because Yref and Y are not drawn from exactly the same pose distribution, the reported PGSR numbers should not be read as the performance of a model trained on the exact deployment-time pose input.
The supervision target is a cleaned, manually isolated full-body silhouette mask. Although the original mask is binary, resizing to the output resolution introduces soft boundary values that provide smoother edge supervision. PGSR is optimized with a compound loss combining focal binary cross-entropy and Dice loss:
This loss encourages both pixel-wise discrimination and global shape consistency. During training, it is applied directly to the probability map without hard thresholding; for evaluation, the predicted mask is binarized at 0.5.
The PGSR module is trained on the same 1,000 paired synthetic samples used for Stage 2, with the same paired-sample-level 800/100/100 split. That is, the occluded image, the paired non-occluded reference image, and all derived supervision from the same pair always belong to the same partition. Each sample contains a single pedestrian instance, so the model learns a one-person mapping from full-body pose to silhouette mask. The present experiments are limited to single-person samples. Extension to multiperson scenes would require reliable person-wise separation before pose completion and is left for future study. By reconstructing a dense silhouette from the inferred skeletal configuration, PGSR provides a shape-level representation that could be used by a future verification module.
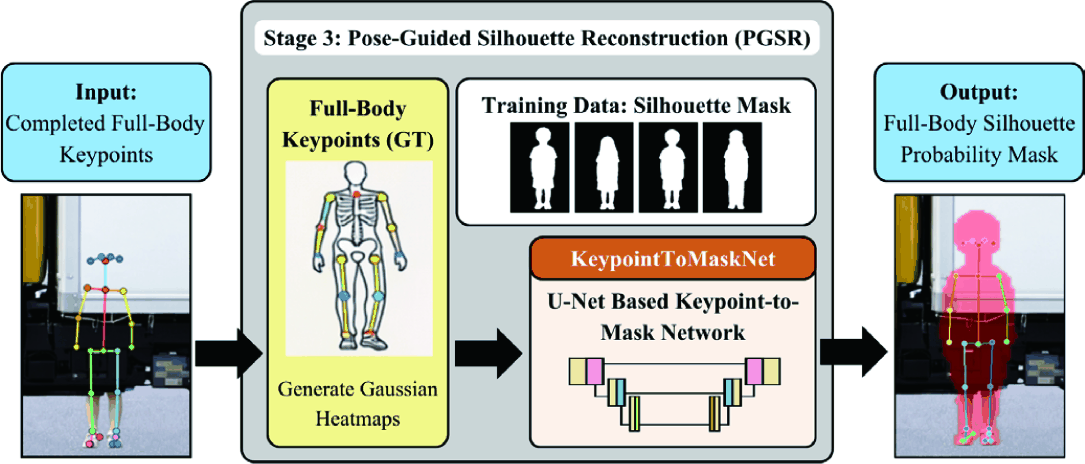
As a prospective extension to the implemented three-stage pipeline, Human Silhouette Verification (HSV) would take the PGSR output mask and reject morphologically implausible reconstructions before downstream risk-assessment or warning modules. This module was not implemented or quantitatively evaluated in the present study.
One possible realization is to transfer silhouette-validity labels from a multimodal teacher model to a lightweight mask-based student classifier for efficient deployment. Such a verifier could help suppress fragmented masks, merged foreground regions, and non-human topology. However, because no HSV-specific dataset, teacher-labeling protocol, or evaluation benchmark was established, we report no HSV metrics in this paper.
4. Experimental Results
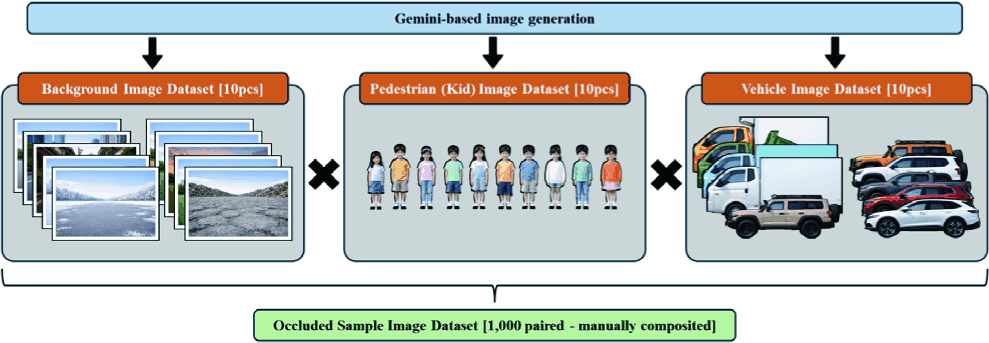
To construct a dataset suitable for reconstruction experiments on pedestrians partially visible beneath parked vehicles, we built a fully synthetic image dataset rather than relying on real-world data. Collecting real images for this scenario is practically difficult because the target condition requires a pedestrian to be visible only through the narrow gap between a vehicle and the ground. Therefore, we generated source visual assets using Gemini-based image generation and manually composited them into final training samples.
As summarized in Fig. 8, the dataset was built from three asset groups: Background Image Dataset [10pcs], Pedestrian (Kid) Image Dataset [10pcs], and Vehicle Image Dataset [10pcs]. Each pedestrian image was manually processed in Adobe Photoshop to remove the background and obtain a transparent foreground layer. The foreground pedestrian layer was then combined with a vehicle layer and a background layer using a classical layer-based compositing pipeline. From each scene configuration, we created two corresponding images: a non-occluded version and an occluded version in which the pedestrian was partially hidden by the vehicle. As a result, the dataset consisted of Occluded Sample Image Dataset [1,000 paired - manually composited], yielding 2,000 images in total.
In this study, an occluded sample is defined as a case in which only the lower body, mainly the legs visible through the gap beneath the vehicle, remains observable. Cases in which the pedestrian was completely invisible were excluded, because OpenPose could not reliably extract meaningful lower-body keypoints in such situations. The generated image resolution was 1536×1024 pixels.
For annotation, two types of supervision were prepared. First, a person silhouette mask was obtained from the manually isolated pedestrian foreground and used as the ground-truth mask for silhouette reconstruction. Second, full-body keypoints were extracted from the non-occluded images using the OpenPose BODY 25 model and used as the paired OpenPose reference pose for FBPI. During training, lower-body keypoints extracted from the occluded images served as the input representation, while the corresponding full-body keypoints from the paired non-occluded images were used as the reference output. No manual keypoint annotation was used for FBPI training or evaluation in the current paper. Because these pose targets were automatically generated from the paired non-occluded images rather than manually annotated, the reported FBPI performance should be interpreted as consistency with the paired OpenPose reference poses. Each pose sample was represented as a 25×3 matrix, where each of the 25 BODY 25 joints was described by its x-coordinate, y-coordinate, and confidence score.
The dataset was divided into 800 training pairs, 100 validation pairs, and 100 test pairs. The split was performed at the paired-sample-ID level after ordering the paired sample IDs by index. The occluded image and the non-occluded image belonging to the same pair were always assigned to the same split; they were never separated across training, validation, and test partitions. Because the current synthetic construction used child-pedestrian foreground assets, the reported results should be interpreted as a controlled feasibility study under a child-pedestrian setting rather than as a universal benchmark for all pedestrian appearances.
Because HSV was not implemented, the quantitative results reported in this section correspond only to the implemented OLPD, FBPI, and PGSR components. Table 2 separates the measured latency scope. Because the original experiment log did not preserve the CPU/GPU model, inference runtime framework, batch size, or warm-up/repetition counts, a fully specified timing protocol cannot be reported retrospectively. The reported 8.676 ms should therefore be interpreted as a local, hardware-unspecified measurement of the FBPI + PGSR reconstruction path only. It excludes OpenPose BODY 25 inference, vehicle-mask prediction, keypoint filtering, and HSV. The 0.077 ms OLPD-related timing reported here does not measure OpenPose inference; it measures only keypoint filtering time after OpenPose outputs are available, using the known synthetic vehicle mask. When this post-OpenPose keypoint-filtering step is added to FBPI + PGSR, the combined measured latency becomes 8.753 ms, but this value still excludes OpenPose BODY 25 inference, vehicle-mask prediction, and HSV. No manual keypoint annotation was used for FBPI evaluation in this section. Accordingly, FBPI metrics should be interpreted as consistency with OpenPose-derived reference poses rather than as actual human pose accuracy. Moreover, because the dataset is constructed from only 10 background assets, 10 vehicle assets, and 10 child pedestrian assets, the reported numbers should be interpreted as a controlled feasibility study under synthetic conditions rather than as evidence of broad real-world recovery. In this section, oracle-mask OLPD results should be interpreted strictly as mask-given synthetic upper-bound results obtained with the synthetic vehicle-layer mask from the compositing pipeline; they do not measure automatic vehicle segmentation or deployment-time perception.
Before comparing against external generic completion baselines, we first separate the oracle-mask setting from the predicted-mask setting. Fig. 9 compares these two regimes. In the oracle-mask setting, the synthetic vehicle-layer mask is provided directly by the compositing pipeline, so the resulting OLPD behavior should be interpreted only as a mask-given synthetic upper-bound rather than as automatic vehicle segmentation or deployment-time perception. By contrast, the predicted-mask panel in Fig. 9 is included only as an illustrative external segmentation example in which an externally estimated vehicle mask is substituted for the oracle mask and then passed to the same downstream reconstruction path. The exact external mask-prediction procedure used to prepare that illustrative panel is not documented in sufficient detail in the current manuscript assets and is not part of the implemented bench-marked pipeline reported in this paper. Accordingly, the predicted-mask setting in Fig. 9 should not be read as a reproducible model specification or formal method comparison. Moreover, the current manuscript does not provide quantitative evaluation for predicted vehicle-mask IoU, OLPD lower-limb F1 under the predicted mask, FBPI OKS under the predicted mask, PGSR IoU/Dice under the predicted mask, or separated mask-prediction latency. Therefore, the predicted-mask results in Fig. 9 should be interpreted as qualitative evidence only rather than as quantitative support for practical deployment.
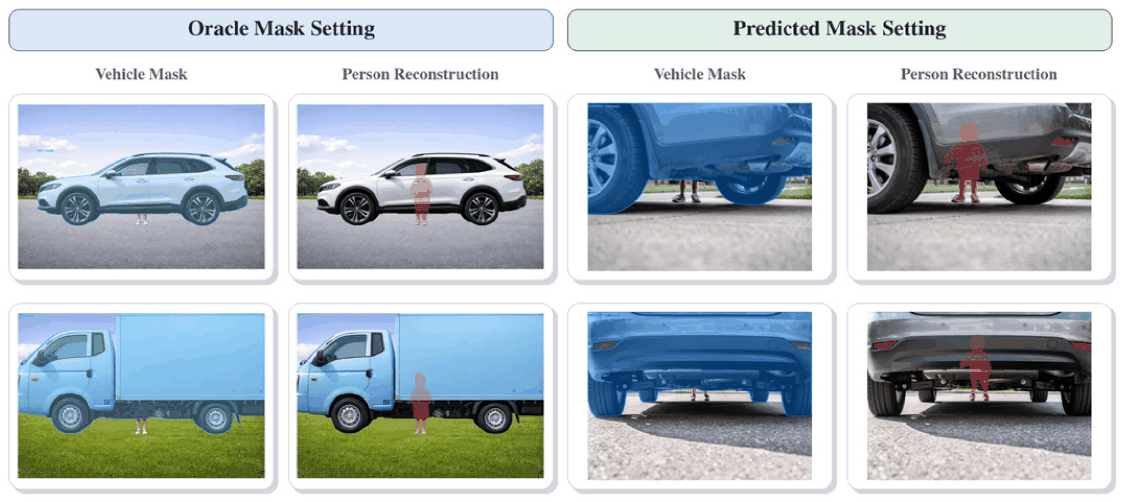
To analyze how vehicle-mask errors affect the OLPD–FBPI–PGSR pipeline, we applied four perturbation types: undersegmentation, oversegmentation, boundary jitter, and partial missing. Fig. 10 reports vehicle-mask IoU, OLPD lower-limb F1, FBPI OKS with respect to OpenPose-derived reference poses on occluded samples, and PGSR mask IoU across mild-to-extreme severity levels. Undersegmentation, oversegmentation, and boundary jitter caused only limited downstream change even at extreme severity. By contrast, partial missing was much more harmful because it removed visible lower-limb evidence before OLPD and then propagated errors to FBPI and PGSR. Under extreme partial missing, vehicle-mask IoU remained 0.973, but OLPD lower-limb F1 fell to 0.854 and both FBPI OKS and PGSR IoU deviated strongly from the oracle baseline.
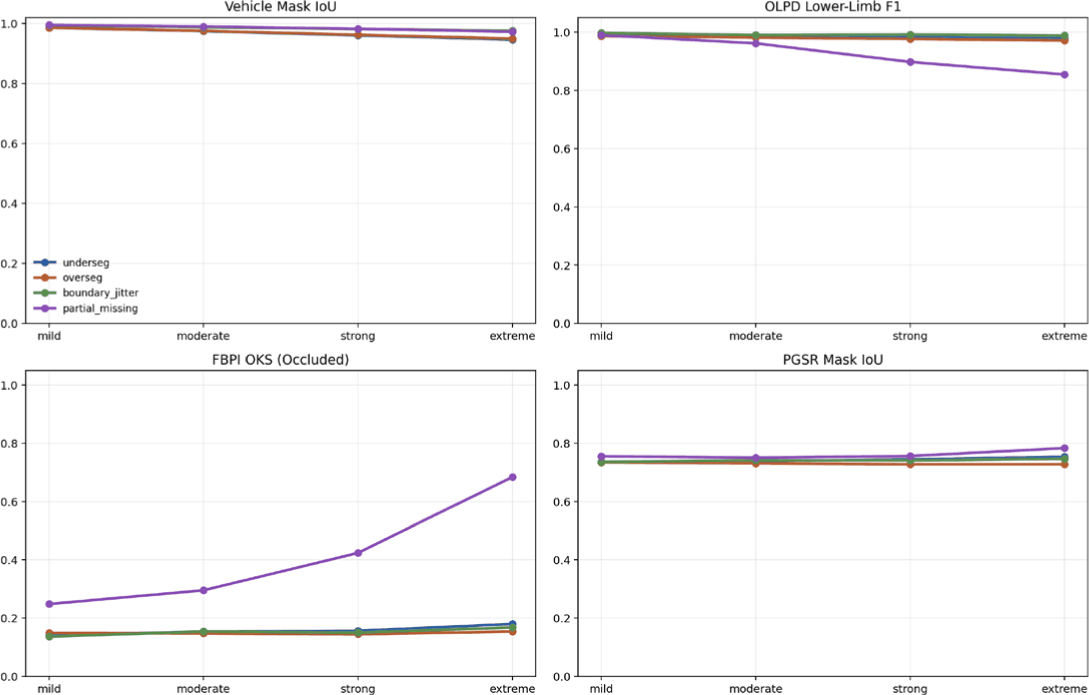
These results show that vehicle-mask IoU alone is not sufficient to explain downstream stability. Compared with contour drift or mild over-/under-segmentation, errors that erase visible lower-limb cues are more consequential because they directly remove the evidence used by OLPD. Accordingly, preserving lower-limb visibility evidence is more important in this pipeline than overall vehicle-mask overlap. The OLPD curves in Fig. 10 should therefore be interpreted as mask-given synthetic upper-bound sensitivity trends under a known occlusion mask rather than as automatic vehicle-segmentation performance.
We next strengthen the comparison beyond simple OpenPose-only or SAM-only references by additionally evaluating three generic full-body completion baselines: Stable Diffusion Inpainting, Stable Diffusion v1.5 img2img masked completion, and Simple LaMa inpainting. These methods operate on masked RGB completion rather than sparse lower-limb keypoints, and their completed RGB outputs are converted into person-mask hypotheses for comparison with our reconstructed silhouette. Therefore, the resulting comparison should be interpreted as a stronger cross-paradigm small-scale qualitative screening rather than as a perfectly stage-matched ablation.
Fig. 11 presents a qualitative comparison between OURS and these stronger generic full-body completion baselines on under-vehicle child samples.

Table 1 summarizes a small-scale qualitative screening on three representative synthetic/composited under-vehicle child samples, focusing on illustrative upward completion behavior and runtime relevance. Here, the top lift ratio corresponds to the previously reported height ratio, so a larger value indicates a stronger upward lift of the completed body into the hidden region for these three examples only; it should not be interpreted as a quantitative benchmark.
| Model | Top lift ratio | Runtime |
|---|---|---|
| OURS | 3.835 | 8.676 ms (FBPI + PGSR only) |
| SD Inpaint | 3.975 | 1.4125 s |
| SD1.5 Img2Img | 0.977 | 1.1771 s |
| Simple LaMa | 1.484 | 1.1824 s |
Within this small-scale qualitative screening, SD Inpaint showed the largest top lift ratio on the three representative synthetic/composited examples, whereas OURS remained close and was the only method with a measured lightweight reconstruction-path latency (8.676 ms for FBPI + PGSR only, excluding Open-Pose BODY 25 inference, vehicle-mask prediction, keypoint filtering, and HSV). Simple LaMa stayed closer to the visible evidence, and SD1.5 Img2Img was unstable. Overall, generic diffusion completion can produce strong upward lift, but the proposed staged pipeline remains more lightweight and structurally controlled for the under-vehicle setting. These observations should be interpreted as illustrative qualitative tendencies rather than as a quantitative benchmark.
For the implemented system, we therefore summarize the results at the pipeline level through visibility tolerance and component-wise latency scope rather than through stage-wise diagnostic tables. Any OLPD-related interpretation in this summary remains limited to the mask-given synthetic upper-bound under the oracle synthetic vehicle-mask setting; it does not evaluate automatic vehicle segmentation or deployment-time perception.
To make the MRV metric operational, let Avis denote the number of visible pedestrian pixels in the occluded sample and Afull denote the number of pedestrian pixels in the paired non-occluded ground-truth mask. The visible ratio is defined as rvis = Avis/Afull. We define Minimum Required Visibility (MRV) as the minimum visible ratio among test samples whose reconstruction satisfies both IoU ≥ 0.80 and Dice (F1) ≥ 0.90. Under this criterion, the observed MRV on the test set was 12.87%.
Because the original experiment log did not preserve the CPU/GPU model, inference runtime framework, batch size, or warm-up/repetition counts, Table 2 should be read as a local, hardware-unspecified latency summary of the measured reconstruction subpaths only. These values do not establish end-to-end real-time performance.
At the same time, the interpretation range of these results is narrow. The 10-background, 10-vehicle, and 10-child-pedestrian asset composition limits scene diversity, vehicle geometry variation, and especially the pose, scale, and silhouette distributions observed during training and evaluation. Because only child assets are used, the reported performance does not establish equivalent behavior for adult pedestrians or for broader variation in body shape, clothing, and self-occlusion. In addition, multi-person scenes and fully invisible cases are outside the evaluated distribution. Accordingly, the present numbers should be read as feasibility under controlled synthetic conditions rather than as evidence of robust real-world recovery.
5. Conclusions
This paper presented an implemented three-stage pose-guided reconstruction framework for partially visible pedestrians under vehicle occlusion. The current work focuses on recovering full-body structure and silhouette from sparse lower-limb evidence observable through the under-vehicle gap, rather than implementing a complete warning decision system. On the adopted synthetic dataset, the measured FBPI + PGSR reconstruction path required 8.676 ms per sample, excluding OpenPose BODY 25 inference, vehicle-mask prediction, keypoint filtering, and HSV, and adding only the post-OpenPose keypoint-filtering step yielded 8.753 ms. These values should be interpreted as local, hardware-unspecified measurements of the partial reconstruction path only, and they do not establish end-to-end real-time performance. Successful reconstruction was maintained down to a minimum visible ratio of 12.87% under the adopted criterion. The FBPI stage should be interpreted as full-body keypoint inference consistent with paired OpenPose reference poses rather than as measured human pose accuracy against manual keypoint annotation. In addition, PGSR in the current implementation is trained on paired OpenPose reference full-body poses from non-occluded images but is evaluated downstream with residual-fused FBPI outputs on occluded samples. Therefore, the reported PGSR behavior should be interpreted as a pose-conditioned upper-bound with respect to pose-input quality rather than as performance of a model trained on the exact deployment-time pose input. The additional oracle-versus-predicted mask comparison provides qualitative evidence only through an illustrative external segmentation example; it is not a reproducible benchmarked mask-prediction method specification in the current manuscript. At the same time, any OLPD-related interpretation in the current manuscript remains limited to the mask-given synthetic upper-bound under the oracle-mask setting and does not measure automatic vehicle segmentation or deployment-time perception. Taken together, these findings support feasibility under controlled synthetic conditions rather than robust real-world recovery, while HSV and downstream alert logic remain future work.
A notable limitation of this study is that the proposed Human Silhouette Verification (HSV) stage was not implemented or quantitatively evaluated in the current system. Although HSV was conceptually designed as a final quality-control module for rejecting implausible reconstructed masks, the present work reports no HSV-specific quantitative results and evaluates only the first three stages, namely lower-limb pose extraction, full-body pose inference, and pose-guided silhouette reconstruction.
A further limitation is that OLPD currently relies on the synthetic vehicle-layer mask available from the compositing pipeline. Accordingly, all reported OLPD results should be interpreted as mask-given synthetic upper-bound results for lower-limb keypoint filtering under a known occlusion mask. They do not evaluate automatic vehicle segmentation or deployment-time perception.
In addition, several aspects of the current experimental design directly limit how the reported results should be interpreted. The validation is restricted to a fully synthetic paired dataset constructed from 10 background images, 10 vehicle images, and 10 Pedestrian (Kid) assets. This small asset pool narrows scene diversity and constrains the pose, scale, and silhouette distributions seen during training and testing. Because the pedestrian assets are child-only, the reported numbers do not establish equivalent performance for adult pedestrians or for broader variation in body shape, clothing, and self-occlusion. Each sample also contains a single pedestrian instance, fully invisible cases were excluded because reliable lower-body keypoints could not be extracted by OpenPose, and the full-body keypoint supervision is derived from the paired Open-Pose reference pose on the non-occluded image rather than from manual keypoint annotation. No manually annotated keypoint subset was used to validate actual human pose accuracy; therefore, FBPI metrics should be interpreted as consistency with OpenPose-derived reference poses. The same paired non-occluded reference pose is also used as the PGSR training input, whereas inference uses the residual-fused FBPI output on the occluded sample. Consequently, the present manuscript includes a pose-input train–test distribution gap at Stage 3, and PGSR results should be interpreted as pose-conditioned upper-bound evidence rather than as a fully matched train/test evaluation under predicted pose input. In addition, the surviving manuscript assets do not preserve the exact internal projection from the 25 × 3 PGSR pose tensor to the first spatial encoder feature map, so Fig. 6 should be interpreted as a conceptual schematic rather than a fully reproducible layer-by-layer architecture. Moreover, Fig. 9 uses an illustrative externally estimated mask example whose exact mask-prediction procedure is not specified as part of the benchmarked pipeline, so that panel should be interpreted as qualitative evidence only. Accordingly, the present quantitative results should be interpreted as a controlled feasibility study under restricted synthetic conditions rather than as evidence of broad road-scene generalization.
Future work should therefore include real-image validation, stricter cross-asset evaluation, adult pedestrians, broader body-shape and clothing variation, multi-person scenes, fully invisible cases, quantitative benchmarking with predicted masks including predicted vehicle-mask IoU, OLPD lower-limb F1 under predicted masks, FBPI OKS under predicted masks, PGSR IoU/Dice under predicted masks, separated mask-prediction latency, and implementation of the HSV stage.

