
1 서론
현실과 가상을 연결하는 확장된 가상 세계인 메타버스는 확장현실 기술의 발전과 더불어 다양한 산업 분야로의 플랫폼 및 서비스가 구현되고 있다. 확장현실은 가상의 공간을 현실과 같이 구현하는 가상현실, 현실 세계 위에 가상의 객체, 정보 등을 표현하는 증강현실, 그리고 보다 확장된 개념으로 가상과 현실 세계가 합쳐져 새로운 환경과 정보를 생성하는 혼합현실을 아우르는 기술이다. 현실을 뛰어넘는 가상의 세계를 체험하거나 가상의 공간을 현실로 불러올 수 있는 확장현실 기술은 현실과 가상의 경계를 허물어 새로운 경험을 제공하는 기술로 발전하고 있다[1, 2].
최근의 가상현실은 HMD(Head Mounted Display)를 통해 차단된 시야에서 컴퓨터로 생성된 3차원의 그래픽 정보를 토대로 가상의 공간을 경험한다. 이를 통해 사용자는 현실 세계를 표현한 가상환경을 경험할 수도 있으면서 동시에 현실에서 경험할 수 없는 새로운 환경을 체험할 수 있다. Sra et al.[3]은 현실 세계의 실내 장면을 바탕으로 3차원 가상 장면을 재구성하여 현실 공간을 기반으로 걷기 가능한 가상환경에서의 영역 및 체험환경을 제공하는 연구를 진행하였다. 또한, HMD 사용자와 함께 HMD를 착용하지 않는 비몰입형 사용자도 함께 참여하는 비대칭 가상환경에 관한 연구를 통해 가상현실 체험환경의 폭을 넓히기 위한 시도들이 진행되기도 하였다[4]. 또한, 가상현실은 현실에서 경험하기 어렵거나 새로운 경험을 제공하는 기술로 응용되고 있다[5].
현실에서의 정보를 기반으로 하는 증강현실은 카메라 등을 통해 촬영된 이미지와 정보 위에 가상의 그래픽을 합성하여 증강된 현실 장면을 제공한다. 카메라를 통해 마커를 인식하고, 인식된 마커 위에 가상의 객체를 합성하는 방법으로 많이 사용됐으며 이미지나 3차원 객체, 지형 등을 인식하는 방법 등으로 발전하였다. 이러한 증강현실 기술은 CLO 3D와 함께 활용되어 증강현실 디지털 패션 콘텐츠를 제작[6]하는 데 사용되는 등 엔터테인먼트 분야를 비롯한 게임, 교육, 의료와 같은 다양한 분야에 응용되고 있다[7-10].
현실과 가상의 경계를 초월하여 확장된 현실 환경을 제공하는 혼합현실은 대표적인 혼합현실 HMD 기기인 메타 퀘스트 시리즈[11], 애플 비전 프로[12] 등을 통해 현실과 가상이 결합된 몰입감 높은 체험환경을 경험할 수 있다. Kong et al.[13]는 메타 퀘스트 프로를 활용하여 혼합현실 기반에서 가상 전기회로 실습 교육 콘텐츠를 제작하여 현실에서 발생할 수 있는 감전의 위험으로부터 안전하면서 새로운 교육 방법을 제안하였다. Kim et al.[14]는 가상현실과 혼합현실 사용자가 동시에 체험할 수 있는 탁구 콘텐츠를 제작하고 각각의 경험을 비교하는 연구를 진행하였다.
모션 캡처 기술은 센서나 카메라를 이용하여 사람의 동작이나 물체의 움직임을 감지하여 정교한 동작을 효과적으로 데이터화함으로써 애니메이션, 영화 등 다양한 미디어 산업에 활용되고 있다. 이러한 모션 캡처 기술은 메타버스 콘텐츠에서도 활용되어 액터의 움직임이 가상환경에서 아바타의 움직임으로 표현되어 몰입감 높은 상호작용과 현실적인 경험을 제공할 수 있다. Kammerlander et al.[15]은 가상현실과 모션 캡처를 활용하여 구성한 협업 가상환경에서 다양한 비율의 가상 캐릭터를 생성하는 방법에 관하여 연구하고 생성된 가상 캐릭터가 사용자에게 미치는 영향을 분석하였다. Fraser et al.[16]은 사실적인 가상 캐릭터의 얼굴 및 몸의 표현은 가상현실에서의 사용자와의 상호작용에 있어 현실감과 품질을 향상할 수 있음을 확인하는 연구를 진행하였다. 이처럼 현실과 가상을 연결할 수 있는 대표적인 기술 가운데 하나로 모션 캡처 기술이 활용되고 있다.
따라서, 본 연구는 현실과 가상환경이 상호작용하여 새로운 경험을 제공하는 혼합현실에 모션 캡처 기술을 응용하여, 혼합현실 기반의 체험환경에서 모션 캡처를 활용한 액터 기반 가상 아바타와 함께 실시간으로 상호작용하는 대화형 콘텐츠를 제작함을 목표로 한다. 그리고, 모션 캡처 기반 가상 아바타가 혼합현실 체험환경에서 사용자의 경험에 미치는 영향을 체계적으로 분석한다. 이를 위해 OptiTrack 모션 캡처 장비[17]를 활용하여 마커를 부착한 슈트를 착복한 액터와 메타 퀘스트 3 HMD를 착용한 혼합현실 사용자가 가상의 아바타와 현실 세계 사용자로서 상호작용 및 소통할 수 있는 체험환경 구축을 위해 유니티 3D 엔진[18]을 활용한 개발환경을 구축한다. 이를 위하여, 모션 캡처 플러그인(OptiTrack Unity Plugin)[19]과 Meta XR All-in-One SDK(Software Development Kit)[20]를 활용한 개발 공정을 정리한다. 통합개발 환경과 정의한 개발 공정을 토대로 구체적인 혼합현실 대화형 콘텐츠 제작 과정과 응용 방향을 제시하기 위하여 본 연구는 어린이를 대상으로 하는 약 복용 도움에 관한 주제의 콘텐츠를 직접 제작한다. 이는 약 복용에 관한 거부감이 크거나 어려움을 갖는 어린이를 대상으로 혼합현실 환경에서 캐릭터로 표현되는 가상 아바타와의 대화, 소통, 이야기를 통해 불안을 낮추고 정서적 안정을 유도하여 자연스럽게 약을 먹을 수 있도록 유도함을 목적으로 한다. 이를 위해, 액터 기반의 가상 아바타와 혼합현실 사용자가 서로 실시간으로 대화하고 상호작용할 수 있도록 유니티 3D 엔진에서 네트워크를 기반으로 한 음성과 동작 동기화 기능을 설계한다. 마지막으로, 제작된 혼합현실 대화형 콘텐츠가 제공하는 새로운 체험환경에서의 경험과 함께 모션 캡처 기반 가상 아바타와의 상호작용이 제공하는 가상환경에서의 현존감과 전반적인 만족도를 설문 실험을 통해 통계 분석한다[21-23].
본 논문의 주요 기여 내용은 다음과 같다.
1. 모션 캡처와 혼합현실 기반 통합개발 환경 구축: 모션 캡처 장비를 사용하여 마커를 부착한 슈트를 입은 액터 기반 가상 아바타와 메타 퀘스트 3를 착용한 혼합현실 사용자가 실시간으로 소통하고 상호작용할 수 있는 혼합현실 대화형 콘텐츠 제작을 위해 유니티 3D 엔진 기반의 통합개발 환경 구축 및 제작 공정 정리
2. 약 복용 도움 대화형 콘텐츠 제작: 혼합현실 기반의 체험환경에서 모션 캡처를 통해 캐릭터로 참여하는 액터 기반 가상 아바타와 혼합현실 사용자가 실시간으로 상호작용하며 이야기를 통해 자연스럽게 약을 먹을 수 있도록 유도하는 콘텐츠 제작하고, 이를 기반으로 설문 실험을 통한 사용자 평가를 진행함으로써 새로운 체험환경이 제시하는 응용 가능성 검증
2. 통합개발 환경 구축
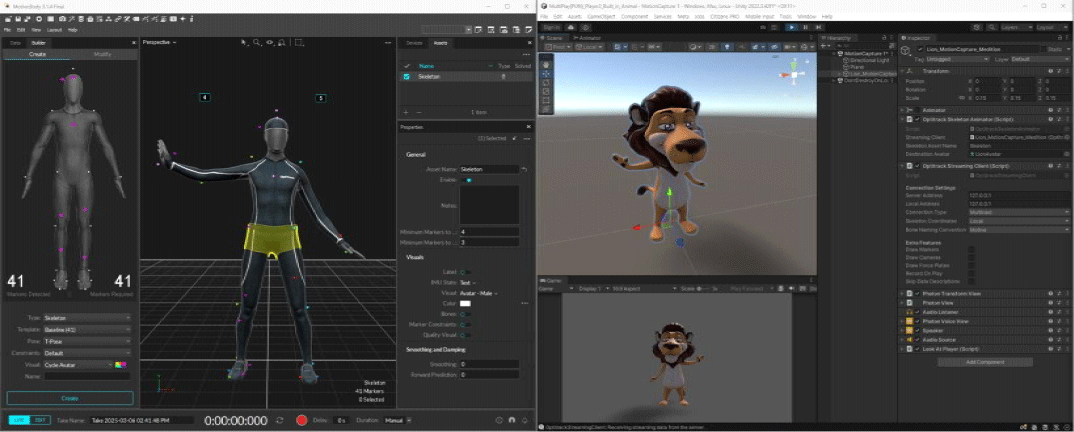
모션 캡처는 몸에 센서를 부착시키거나, 적외선을 이용하는 등의 방법으로 인체의 움직임을 디지털 형태로 기록하는 기술로 마커가 부착된 슈트를 입은 액터의 동작을 두 대 이상의 카메라를 통해 촬영하여 움직임을 정확히 측정하는 광학식 방법과 주요 관절 부위에 관성 센서를 부착하여 움직임을 추정하는 관성식 방법이 있다. 본 연구는 광학식 방법으로 OptiTrack Prime 17W 카메라 16대로부터 마커가 부착된 슈트를 착복한 액터의 동작을 실시간으로 추적한다(Figure 1). 그리고 모티브(Motive 3.1.4) 소프트웨어를 통해 슈트에 부착된 41개의 마커를 토대로 주요 관절과 뼈대로 구성된 스켈레톤(Skeleton)을 가상 아바타로 연결하여 실시간으로 애니메이션을 동기화할 수 있다.

추적된 액터의 움직임을 토대로 모티브 소프트웨어를 통해 생성된 스켈레톤 정보를 유니티 3D 엔진에서 연동하기 위해 플러그인(OptiTrack Unity Plugin 14.0)을 사용한다. 가상 아바타로 활용한 캐릭터 모델을 정의하고, 주요 기능인 스크립트 컴포넌트(OptitrackSkeletonAnimator.cs)를 추가한다. 또한, 모티브 소프트웨어에서 생성한 스켈레톤 이름과 컴포넌트의 이름 속성(Skeleton Asset Name)을 동일하게 입력하면 모티브 소프트웨어서 계산된 스켈레톤의 동작이 유니티 3D 엔진에서 정의한 캐릭터의 동작으로 실시간으로 동기화된다(Figure 2). 단, 유니티 3D 엔진에서 사용하는 캐릭터 모델은 리깅이 포함된 모델이어야 하며, 애니메이션 타입 설정을 Humanoid로 지정해야 한다. 또한, 만약 캐릭터 모델이 기존의 애니메이션 정보를 가지고 있다면 해당 애니메이션 동작이 아닌 모션 캡처 애니메이션과 동기화되기 위해 Animator 속성을 비활성화해야 한다.
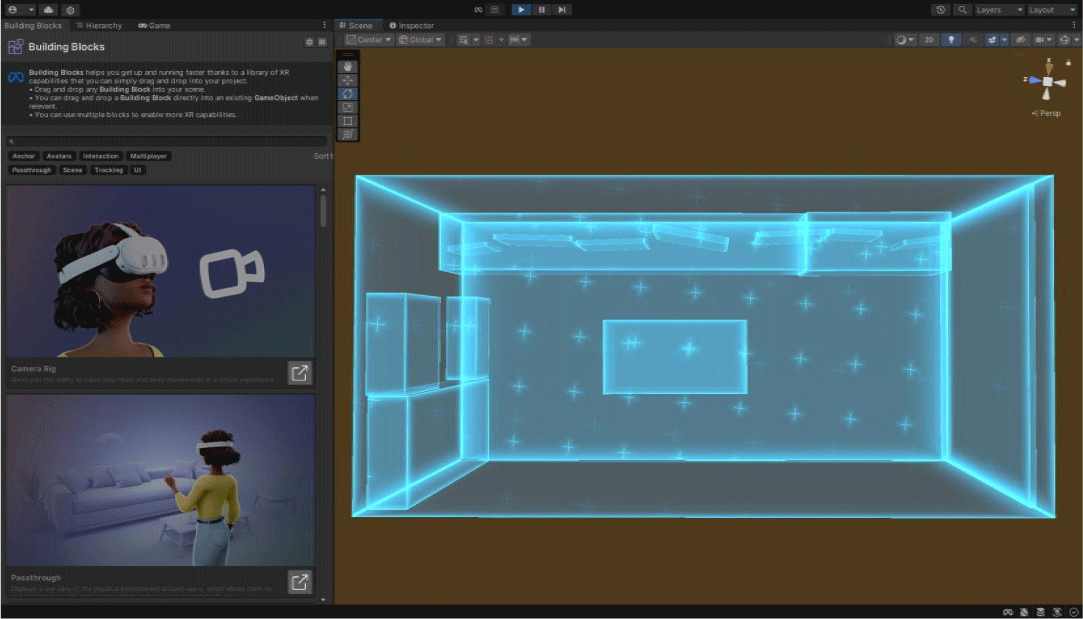
본 연구는 혼합현실 콘텐츠 제작을 위한 장비로 메타 퀘스트 3 HMD를 사용한다. 메타 퀘스트 3 HMD에는 내장된 2개의 RGB 카메라를 통해 풀 컬러 패스스루(Full Color Passthrough) 방식을 통해 현실 세계의 이미지를 HMD를 통해 확인할 수 있다. 유니티 3D 엔진에서 메타 퀘스트 3를 기반으로 콘텐츠 제작을 위한 개발 환경을 구축하는 방법으로 Meta XR All-in-One SDK를 활용한다. 이는 혼합현실 체험환경 구축에 필요한 다양한 기능을 Building Block 방식으로 제공하여 개발자가 쉽게 원하는 기능을 구현할 수 있도록 지원하고 있다.
메타 퀘스트 3에서 제공하는 공간 설정 기능은 현실 세계의 기본적인 물리적 구조인 바닥과 벽을 지정하고, 창문과 책상 등 현실 공간을 구성하는 객체의 경계를 지정하고 물리적 구조 정보에 관한 공간 정보를 저장하여 개발에 쉽게 활용할 수 있다. 또한, 이는 가상 객체와의 결합을 통해 표현되는 혼합현실 체험환경에서 자연스러운 장면을 표현하는 데 활용된다. 저장된 공간 정보를 유니티 3D 엔진으로 불러와 현실 세계의 물리적 구조를 가진 확장된 가상환경으로 재구성할 수 있으며, 이 역시 Meta XR All-in-One SDK의 Building Block의 Effect Mesh 기능을 통해 구현할 수 있다(Figure 3). 본 연구에서는 책상과 의자로 구성된 일반적인 사무실 실내 공간을 토대로 공간 정보를 저장하고 책상의 물리적 구조에 맞춰 모션 캡처 기반 가상 아바타와 함께 가상 객체가 책상 위의 지정된 위치와 방향에 배치될 수 있도록 설계한다(Figure 4). 마지막으로, Meta XR All-in-One SDK의 Building Block에서 제공하는 손 추적(Hand Tracking) 기능을 활용하여 가상 객체를 제어하는 등의 상호작용을 구현한다.
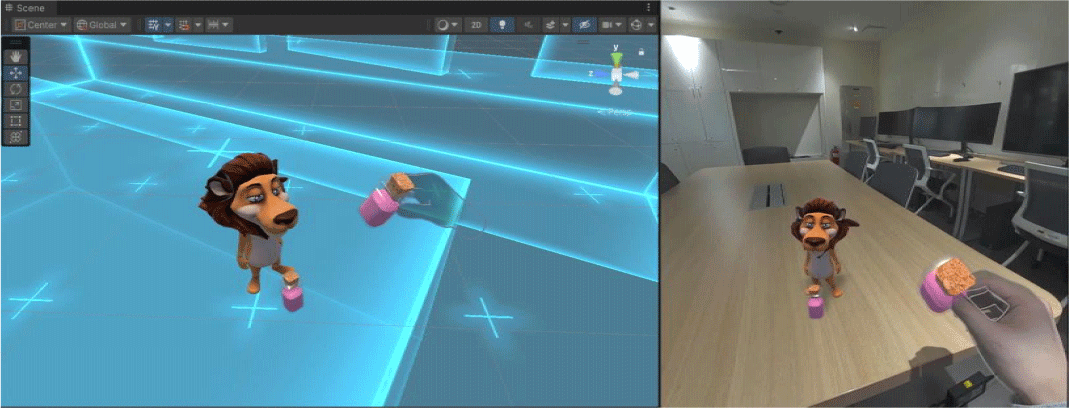
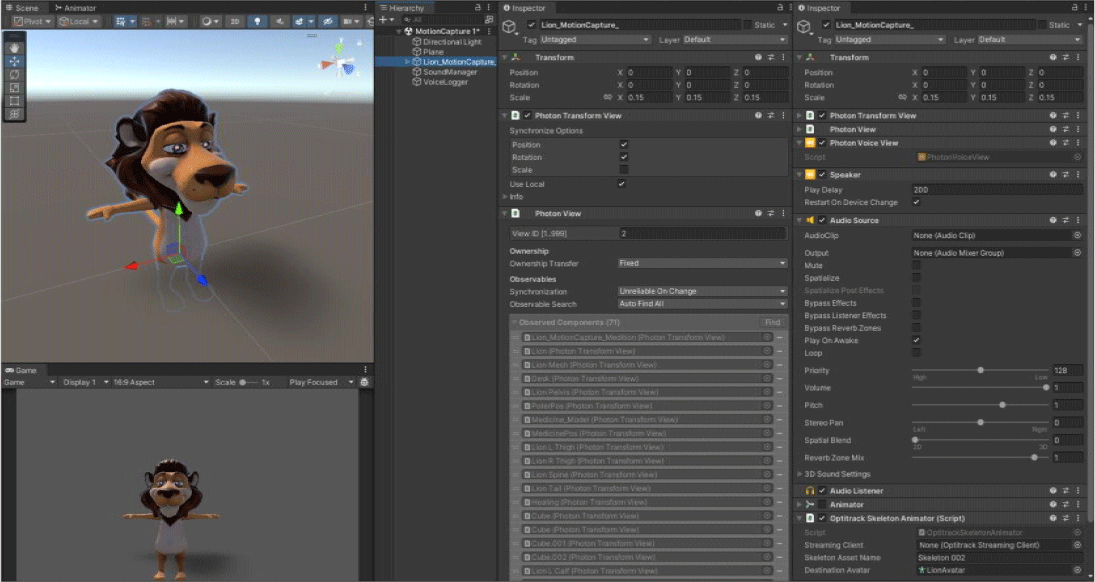
통합개발 환경 구축의 마지막 단계는 모션 캡처 기반 가상 아바타와 혼합현실 사용자 사이의 실시간 소통 및 상호작용을 위한 동기화이다. 서로 다른 공간, 참여 방식 그리고 플랫폼의 사용자 사이의 실시간 대화 및 통일된 행동 정보 공유를 위해서는 음성과 동작에 관한 동기화가 필요하다. 본 연구는 포톤 엔진(Photon Engine)에서 제공하는 유니티 3D 엔진 기반의 네트워크 기능인 PUN 2(Photon Unity Networking)[24]와 Photon Voice 2[25]를 활용하여 동기화 기능을 구현한다. PUN 2를 기반으로 액터를 통해 동작하는 가상 아바타와 혼합현실 사용자의 행동, 동작 등을 동기화하여 실시간으로 정확한 상호작용(Figure 5)을 가능하게 하며, Photon Voice 2를 기반으로 무선 이어폰을 착용한 액터와 메타 퀘스트 3 HMD에 내장된 스피커와 마이크를 통해 혼합현실 사용자와 음성으로 대화할 수 있도록 구현한다(Figure 6). 추가적으로, 혼합현실 사용자의 정면에 웹캠을 설치하여 액터 역시 혼합현실 사용자의 모습이 확인 가능하도록 영상 정보를 제공하였다.

3. 약 복용 도움 콘텐츠
본 연구에서는 모션 캡처 기반 가상 아바타와 혼합현실 사용자가 함께 참여하는 체험환경 구축을 위하여 동기화 기능을 포함한 통합개발 환경을 구현하고, 이를 기반으로 사용자가 실시간으로 소통 및 상호작용하는 대화형 구조의 콘텐츠 제작 응용을 목적으로 약 복용 도움이라는 주제를 제시하였다. 이는 약 복용에 대한 안 좋은 기억, 거부감 등을 갖거나 일반적인 어려움을 가진 어린이를 대상으로 한다. 캐릭터로 표현되는 가상 아바타의 이야기를 바탕으로 약 복용 과정에서 흥미롭고 긍정적인 경험을 제공하여 이후에도 부정적 감정을 줄일 수 있도록 하는 것을 목적으로 한다. 어린이 사용자의 선호, 호감 등을 반영한 캐릭터에 모션 캡처 기반의 가상 아바타를 통해 표현되는 자연스러운 움직임과 함께 혼합현실 콘텐츠를 통해 소통하고 체험하는 과정이 약 복용이라는 콘텐츠의 목적을 효과적으로 전달하는 데 도움을 주도록 한다. 다만, 본 연구에서 제작하는 약 복용 도움 콘텐츠는 의학적 목적이 아닌 체험형 콘텐츠로 실제 약을 사용하는 대신 약통만 실제와 같은 제품을 사용하고, 음료 등으로 대체하였다. 그리고, 콘텐츠를 진행하는 동안 옆에 보호자 또는 지도자가 함께하여 안전하게 체험할 수 있도록 진행하였다.

4. 실험 및 분석
약 복용 도움 대화형 혼합현실 콘텐츠는 모션 캡처 기반 가상 아바타와의 실시간 상호작용이 혼합현실 사용자에게 높은 몰입과 함께 콘텐츠의 목적을 효과적으로 전달하면서 동시에 만족하는 경험을 제공하는 것을 실험하기 위하여 제작된 결과이다. 즉, 의학적 목적보다는 가상 아바타와의 혼합현실 사용자 간 상호작용이 가지는 경험, 만족, 몰입 등에 대한 긍정적 요인을 확인하는 것이 핵심 목표이기 때문에 의학 전문가를 통해 어린이를 대상으로 실제 약 복용에 대한 거부감 완화 효과를 검증하는 것은 아니다. 따라서, 제안하는 체험환경에 관한 사용자 경험, 현존감, 만족도에 대한 사용자 평가는 혼합현실과 모션 캡처 등 관련 기술에 대한 이해도가 상대적으로 높은 성인을 대상으로 진행하고, 어린이와 학부모를 대상으로 콘텐츠 목적에 관한 주관적 설문 평가를 수행하였다. 그리고 실험에 대한 설명 시 성인에게는 해당 콘텐츠는 어린이를 대상으로 설계되었음을 안내하였다. Table 1은 액터와 혼합현실 사용자 사이의 대화 내용 중 일부로 가상 아바타와의 이야기 흐름을 파악할 수 있도록 정리한 것이다.
사용자 평가 실험은 제안하는 체험환경에 대한 비교 평가를 위하여 두 가지 체험 방식으로 나누어 설계한다.
-
액터가 수행하는 모션 캡처 기반 가상 아바타와 함께 참여하여 상호작용하는 혼합현실 체험환경
-
혼합현실 사용자가 기존의 GUI 방식으로 정의된 버튼을 누르면 사전에 정의된 행동과 대사가 실행되는 혼합현실 체험환경(Figure 8)

액터가 혼합현실 사용자의 행동, 반응, 대화에 맞춰 유연하게 이야기를 이끌어 가며 대응할 수 있는 체험환경을 정해진 대본과 행동에 맞춰 콘텐츠를 체험하는 기존의 GUI 방식과 비교하여 사용자 경험에 미치는 영향을 비교하기 위한 목적이다. 설문 실험은 콘텐츠가 제공하는 전반적인 경험에 대한 분석과 혼합현실 체험환경에서의 현존감 그리고 제작된 콘텐츠가 목적을 달성하는 데 있어 제안하는 새로운 상호작용 방식이 가지는 만족도를 분석하기 위해 3가지 설문지를 활용하여 진행한다. 우선, 사용자 경험과 관련하여 7개 항목과 14개의 설문 문항으로 구성된 GEQ(Game Experience Questionnaire)[21]의 In-game 모듈을 기반으로 5점 척도로 응답받는다. 또한, 모션 캡처 기반 가상 아바타와 GUI 방식 각각에 대한 유용성과 만족도를 비교 분석하기 위하여 USE (Usefulness, Satisfaction, Ease of use)[22] 설문지를 활용한다. USE 4가지 항목 가운데 Usefulness와 Satisfaction 항목의 문항을 선택하였으며, 7점 척도로 응답받았다. 마지막으로, 현존감을 확인하기 위해 PQ (Presence Questionnaire)[23] 설문지를 활용하였다. 24개의 문항, 7개의 항목으로 구성된 설문지 가운데 혼합현실 체험환경에서의 몰입을 분석하기 위한 Realism 항목과 이야기를 통해 상호작용하는 과정에서의 현존감을 비교하기 위한 Sounds 항목의 총 10개의 문항을 선별하여 7점 척도로 응답받아 설문에 활용하였다.
실험 참가자는 혼합현실 사용자로 메타 퀘스트 3 HMD를 착용하고 두 가지 체험 방식을 각각 체험한 다음 GEQ, USE, 그리고 PQ 설문지에 답변하는 과정으로 진행된다. 실험 순서는 참가자 중 절반은 제안하는 모션 캡처 기반 가상 아바타와 상호작용하는 체험환경을 나머지 절반은 GUI 방식의 체험환경을 먼저 진행하는 방식으로 설계하였다. 액터는 모션 캡처 사용에 대한 경험 및 지식을 가진 비전문가 두 명(30대 여성, 20대 남성)으로 구성되었으며, GUI 환경에서 가상 캐릭터의 대사를 녹음하여 음성 인터페이스로 활용하기 위해 두 명의 액터 목소리로 녹음하였다.
사용자 평가를 위한 설문 실험 참가자는 총 12명으로 남성 10명, 여성 2명으로 구성하였고, 나이는 19세부터 36세, 평균 26세이다. 모든 참가자는 두 가지 체험환경으로 구성된 콘텐츠를 각각 체험한 후 GEQ, USE, 그리고 PQ 설문지에 응답한다. Table 2는 각 체험환경에 따른 세 가지 설문지의 응답 결과를 정리한 것이다. 설문 결과를 토대로 통계 분석을 위한 과정으로 우선, 두 가지 체험환경에서의 결과에 따른 등분산 검정을 수행한다. 본 연구는 Levene’s test를 통해 설문 결과의 등분산 검정을 수행하였다. 등분산 검정 결과 모든 설문 결과에 대해서 유의확률보다 큰 값(p>0.05)이 나타나 등분산임을 가정할 수 있고, 따라서 이를 기반으로 두 체험환경 사이의 통계적 유의성을 비교 분석하기 위하여 Student’s t-test를 수행하였다. 경험에 관한 전반적인 결과, 유용성, 만족도, 그리고 현실감과 음성을 통한 대화 과정에서의 결과 모두 제안하는 모션 캡처 기반 가상 아바타와의 상호작용 과정이 높은 결과를 나타내었지만, Flow 항목(t=2.56, p<0.05)을 제외하고는 유의미한 차이는 나타나지 않았다. 가상 아바타가 혼합현실 사용자의 대화 과정에서 혼합현실 사용자의 반응, 대화 방식 등을 고려하여 유연하게 대처하는 과정이 전체적인 결과 향상에 도움을 준 것으로 판단할 수 있었다. 특히, 가상 아바타와의 상호작용(대화와 행동)을 통해 혼합현실 사용자가 콘텐츠에 집중함을 느낄 수 있었다는 결과를 보여주는 Flow 항목에서는 특히 유의미한 차이를 보일 수 있었다.
다음은 실험 순서에 따른 체험환경 경험의 차이를 비교 분석하였다. 본 연구에서는 참가자를 두 그룹으로 나누어 모션 캡처 기반 가상 아바타 체험환경과 GUI 방식의 체험환경을 각각 먼저 진행하는 방식으로 설계하였다. Table 3은 진행 순서에 따른 결과를 정리한 것으로, 같은 체험환경을 진행 순서에 따라 두 그룹으로 나누어 데이터를 비교한 결과를 포함하며 나중에 체험한 환경에서의 결과가 높게 나타나는 것을 확인할 수 있었다. 모션 캡처 기반 가상 아바타 체험환경의 경우 특히, GUI 방식을 체험하고 난 이후의 값이 뚜렷하게 달라짐을 보인다. 이는 가상 아바타가 제공하는 상호작용이 현실과 유사하고 사용자의 관점에서 더욱 집중하고 몰입할 수 있도록 유도하며 콘텐츠의 목적을 전달하는 데 유용하였음을 GUI를 먼저 체험한 다음 뚜렷하게 느꼈음을 나타내는 것으로 분석할 수 있다. 이 역시, 체험 순서에 따른 통계적 유의성을 확인하기 위하여 등분산 검정(Levene’s test)을 수행한 결과 모션 캡처 기반 가상 아바타와의 체험환경 설문 결과 가운데 GEQ의 Sensory and Imaginative Immersion과 USE의 Satisfaction 항목에서만 순서에 따른 결과가 등분산이 가정되지 않은 결과(p<0.05)를 보였다. 다만, 값의 차이가 크지 않고, 참가자 집단의 수가 적은 점을 고려하여 Student’s t-test를 수행하였다. 그 결과, GUI를 먼저 체험한 사용자 그룹의 모션 캡처 기반 가상 아바타 체험환경에서 체험 순서에 따른 PQ의 Sounds 항목(t=-3.75, p<0.05)에 관하여 유의미한 차이를 확인할 수 있었다. 이는 정의된 대사를 기반으로 진행되던 이야기 구조를 먼저 체험하고 난 이후에 액터와 자연스럽게 대화를 이어가는 체험환경을 경험하였을 때 청각적 현존감의 차이를 크게 느꼈던 것으로 판단한다.
마지막으로, 진행된 설문 실험을 위하여 본 연구에서는 2명의 액터가 콘텐츠를 진행하였다. 제작된 콘텐츠의 목적을 효과적으로 전달하기 위해서는 이야기를 이끌어가는 액터의 역할이 중요한 만큼 액터에 따른 결과 차이를 분석하였다. 참가자를 역시 두 그룹으로 나누어 절반은 30대 여성인 액터(A1)를 맡아 실시간으로 모션 캡처 기반 가상 아바타로 함께 참여하고, 같은 액터의 음성으로 녹음된 GUI 환경을 체험하도록 하였다. 나머지 절반은 20대 남성인 액터(A2)가 같은 방식으로 진행하였다. Table 4는 이러한 실험 설계를 바탕으로 설문 응답 결과를 정리한 것이다. 실험 순서에 따른 경험의 차이와 유사하게 액터에 따른 차이도 일부 명확하게 나타나는 것을 확인할 수 있다. 전반적으로 남성 액터(A2)와의 상호작용 경험이 더 긍정적이었음을 확인할 수 있었다. 액터에 따른 통계적 유의성을 확인하기 위하여 우선 등분산 검정(Levene’s test)을 수행한 결과 액터에 따른 체험환경을 수행하는 과정에서 GEQ의 Tension 항목에서만 등분산이 가정되지 않는 결과를 보였다. 하지만 이 역시도, 순서에 따른 등분산 검정 결과와 같은 이유인 점을 고려하여 Student’s t-test를 수행하였다. 그 결과, GUI 방식의 체험환경에서 액터에 따른 GEQ의 Flow 항목(t=-2.73, p<0.05)과 Negative affect 항목(t=2.71, p<0.05)에서 유의미한 차이를 보였다. 정의된 음성이 입력에 따라 재생되는 GUI 방식에서 액터 목소리의 연기력이나 어조에 대한 인상이 콘텐츠를 집중하는 과정을 방해하거나 지루하게 하는 등 부정적인 영향을 발생시킬 수 있음을 확인할 수 있었다. 하지만, 이 역시도 혼합현실 사용자와의 실시간 상호작용을 통해 상황과 성향에 맞춰 이야기를 이끌어 간다면 해결이 가능한 부분으로도 해석될 수 있다.
전체적인 설문 실험 결과, 대화형 콘텐츠를 체험하는 과정에서 기존의 GUI 방식에 익숙한 사용자들에게 본 연구에서 제안하는 새로움 체험환경은 몰입할 수 있고, 만족하며, 향상된 경험을 제공할 수 있을 것으로 판단한다. 또한, 콘텐츠의 목적을 잘 전달할 수 있는 전문적인 액터가 참여할 수 있는 방향으로 발전한다면 콘텐츠의 목적을 더욱 효과적으로 달성할 수 있고, 체험환경이 제공하는 긍정적인 효과는 더욱 극대화할 수 있을 것으로 기대한다.
본 연구에서 제작한 혼합현실 대화형 콘텐츠는 어린이의 약 복용 도움을 목적으로 하고 있다. 따라서, 어린이의 관점에서 제작된 콘텐츠가 실질적으로 도움이 될 수 있는지에 관한 판단이 필요하다. 다만, 혼합현실 장비를 직접 활용하여 체험하는데 발생할 수 있는 위험 또는 부정적 요인을 고려하여 콘텐츠 진행 과정을 영상으로 제작하였다. 총 4명의 11세 여자 어린이 참가자를 대상으로 진행하였고, 영상을 시청한 다음 Table 5에서 제시된 주관식 문항에 각자의 의견을 기록하였다. 단, 가상 아바타와의 상호작용이 미치는 영향을 확인하기 위하여 어린이 상담에 많이 쓰이는 방식으로 인형을 앞에 두고 인형과 대화하듯이 진행하는 방식을 함께 영상으로 제작하여 실험에 활용하였다(Figure 9). 즉, 어린이들은 제안하는 가상 아바타와의 체험환경과 인형 방식의 상담 체험환경 영상을 각각 시청한 다음 설문에 답을 기록하는 방식으로 진행된다. 그리고 이 과정에서 보호자의 입장도 함께 확인하기 위하여 같은 실험을 보호자에게도 진행하였다. 보호자는 평균 46세의 여성으로 구성되었다.

설문 결과 모든 어린이 참가자는 1번 문항에 ‘없다’라고 답하였으나, 연관 문항에서 3명은 쓴맛에 대한 경험은 있었다는 부연 답을 작성하였다. 그리고 2번 문항부터 4번 문항까지 모두가 가상 아바타라고 답하였다. 하지만 1명의 어린이는 마지막 5번 문항에서 인형 콘텐츠를 체험하고 싶다는 의견을 주었는데, 디지털 콘텐츠에 익숙해져 있는 어린이들에게 오히려 인형으로 진행되는 콘텐츠가 생소하게 느껴져서 호기심을 유발하는 의견을 내놓기도 하였다. 또한, 어린이의 시선에서 관심 있게 접근해야 할 의견으로 콘텐츠 체험 시간을 지루하지 않게 짧게 설정하면 좋다는 내용이 있었다. 제작된 콘텐츠의 체험 시간과 관련해서는 특별한 고민을 하지 않았었는데 숏폼과 같은 미디어에 익숙한 어린이의 시선에서는 콘텐츠의 내용과 방식도 중요하지만 시간 또한 중요함을 알 수 있었다.
마지막으로 보호자에게 같은 설문을 진행한 결과, 3명이 1번 문항에 ‘있다’라고 답하였으며, 그 이유로 어린이와 같이 쓴맛에 대한 경험이었다. 다음으로 2, 4, 5번 문항에는 모두 ‘가상 아바타’로 답하였으며, 3번 문항에서 1명의 보호자는 ‘인형’으로 답을 하였다. 가상 아바타보다 인형이 주는 친근함이 아이의 긴장, 부정적 환경을 개선하는 데 도움을 줄 수 있다는 의견으로 판단한다. 기타 의견으로 가상 객체인 약의 모양이나 효과를 더 화려하게 변경하여 쓴맛의 이미지를 상쇄하면 좋을 것 같다는 내용을 적어주기도 하였다. 주관적 설문 평가를 통해 액터가 진행하는 가상 아바타와의 상호작용이 아이들의 긴장을 낮추고 호기심을 유발하는 데 도움을 주는 것으로 확인되었다. 궁극적으로 약 복용에 직접적인 도움을 주는지는 추가적인 실험이 필요할 것으로 판단하지만 가상 아바타와 함께 참여하는 혼합현실 환경이 콘텐츠의 내용을 효과적으로 전달하고 목적을 달성하는 데 도움이 되는 새로운 체험환경으로 응용될 수 있다는 것이다.
5. 한계 및 토의
혼합현실 대화형 콘텐츠로 제작한 약 복용 도움 콘텐츠는 약 복용에 거부감이 크거나 어려움을 갖는 어린이를 대상으로 하고 있다. 하지만, 해당 콘텐츠는 새로운 체험환경과 이를 위한 통합개발 도구의 활용 및 검증을 위하여 제작되었다. 이러한 이유로, 의료 기관 또는 의학 전문가의 검증을 통해 해당 콘텐츠와 체험환경의 유용성을 객관적으로 실험하지 않았다. 또한, 어린이를 대상으로 혼합현실 콘텐츠를 체험하는 실험을 진행하는 것은 고려해야 할 조건이 많고 까다로워 현재는 성인을 대상으로 제작된 콘텐츠를 체험하고 설문을 진행하였다. 따라서, 향후 제안하는 체험환경에 기반하여 제안하는 체험환경에 관한 객관적 검증을 위해서 사용자의 관심과 흥미를 높일 수 있는 게임과 같은 엔터테인먼트 분야, 집중과 몰입을 통해 정보 전달 효과를 높이는 교육 등의 분야에 제안하는 모션 캡처 기반 가상 아바타를 활용한 혼합현실 콘텐츠를 다양하게 제작하고, 여러 연령대의 많은 수의 참가자를 대상으로 실험을 진행하여, 제안하는 체험환경 평가에 대한 신뢰도를 높이고 활용성을 확인하고자 한다.
다음으로, 액터를 통해 표현되는 가상 아바타 구현을 위해 사용된 모션 캡처 장비는 고가이며 큰 규모의 공간이 요구된다. 또한, 액터의 연기 역량 또한 콘텐츠의 몰입과 효과에 직접적인 영향을 미칠 수 있다는 한계가 존재한다. 이러한 점들은 제안하는 혼합현실 대화형 콘텐츠 제작을 위한 통합개발 환경 및 체험환경의 활용에 있어서 중요한 제약이 될 수 있다. 따라서, 상대적으로 저가의 관성식 모션 캡처나 키넥트와 같은 장비 등으로 가상 아바타를 대체하는 방법과 함께 OpenAI의 오디오 모델 등을 활용하여 상황에 맞는 음성으로 변환하거나 액터의 동작에 기반하여 사전에 제작된 애니메이션을 변형하여 사용하는 방식 등을 통해 액터에 대한 의존도를 낮추는 방향으로의 연구 등이 추가로 진행된다면 제안하는 방법의 활용성도 높아질 것으로 판단한다.
6. 결론
본 연구는 모션 캡처 기반 가상 아바타와 혼합현실 사용자가 함께 실시간으로 상호작용하는 대화형 콘텐츠 제작을 위한 통합개발 환경을 구축하고 새로운 체험환경을 제시하였다. 액터를 활용한 가상 아바타 구현을 위하여 OptiTrack 모션 캡처 장비를 활용하고, 슈트를 입은 액터의 움직임에 맞춰 가상 아바타의 애니메이션이 실시간으로 스트리밍되기 위한 개발과정을 정리하였다. 또한, 메타 퀘스트 3를 기반으로 Meta XR All-in-One SDK를 활용하여 혼합현실 개발 환경을 구축하는 제작 공정을 정의하였다. 마지막으로 모션 캡처 기반 가상 아바타와 혼합현실 사용자 사이의 상호작용을 위하여 음성과 동작을 정확하게 동기화하기 위한 네트워크 기능을 구현함으로써 새롭게 제시하는 체험환경 구축을 위한 통합개발 환경을 제안하였다.
구축된 통합개발 환경을 토대로 혼합현실 대화형 콘텐츠 제작 공정을 확인하기 위하여 약 복용 도움을 주제로 하는 콘텐츠를 제작하고, 이를 활용하여 설문 실험을 통해 사용자 경험, 유용성, 만족도, 몰입에 기반한 현존감 등을 분석하였다. 설문 실험 결과 제안하는 모션 캡처 기반 가상 아바타와의 상호작용을 통한 혼합현실 체험환경이 향상된 경험과 만족을 제공함을 확인할 수 있었다. 또한, 어린이와 보호자를 대상으로 제안하는 콘텐츠의 목적을 달성하는데 제안하는 체험환경이 가지는 이점을 확인하도록 주관적 설문 실험을 진행하였고, 가상 아바타와의 상호작용이 가지는 혼합현실 환경이 긴장을 낮추고 흥미를 유발하여 콘텐츠를 편안하게 체험할 수 있다는 결과를 확인할 수 있었다. 이와 같은 결과들을 통해, 본 연구에서 제작된 체험환경은 의료 행위에 대한 긍정적 경험을 유도하는 새로운 교육 및 치유적 응용 가능성을 제시하며 나아가 엔터테인먼트, 교육, 심리 치료 등 다양한 분야에서 사용자 중심의 대화형 혼합현실 콘텐츠 개발을 위한 실질적인 토대와 새로운 방향을 제시한다.



