




1. 서론
옛날 사진들은 대부분 흑백이며 화질이 선명하지 못한 경우가 많다. 많은 사람들이 이러한 사진으로부터 당시의 추억을 생생하게 느끼고 싶어 한다. 이를 위해 흑백 이미지의 원래 색상을 추측하여 컬러로 볼 수 있게 해주는 컬러화 작업이 필요하다. 컬러화 작업 시 유의해야 할 점은 두 흑백 이미지가 같은 명암 값을 가지더라도 원래의 컬러 값은 다를 수 있다는 것이다. 이는 흑백 이미지를 원래의 컬러로 완벽하게 복원할 수 있는 절대적인 방법은 없으며 오로지 임의로 채색하여 컬러 정보를 넣게 된다는 것을 의미한다. 대개의 컬러화 작업은 일종의 예술 작업으로 간주되어 왔으며, 컬러화를 위해선 숙련된 아티스트의 많은 시간과 노력이 필요하다.
컬러화의 또 다른 문제로는 이미지 손상의 문제가 있다. 과거의 흑백 사진들은 대부분 아날로그이며 시간이 지남에 따라 다양한 이유로 손상되는 경우가 많다. 이로 인해 대개의 경우 손상되어 있는 흑백 이미지를 입력받아 컬러화 작업을 진행하게 된다. 컬러화에 대한 기존 연구는 일반적으로 영상의 특징을 추출하고 추출된 특징을 분석하거나 유사한 참조 이미지를 통해 색칠한다. 이런 방법들은 대부분 손상된 영역을 고려하지 않아 손상된 영역을 포함하고 있는 흑백 이미지가 입력으로 주어졌을 때 컬러화가 견고하게 작동하지 않는 한계가 있다. 따라서 본 논문에서는 이와 같은 문제를 해결하기 위해 손상된 영역을 복원 후 컬러화를 수행하는 방법을 제안한다.
이미지 복원이란 일반적으로 사용 가능한 시각적 데이터를 기반으로 손상된 영역을 추정하여 채우는 작업을 말한다. 현실의 시각적 세계는 매우 구조화되어 있기 때문에 사람들은 손상된 이미지를 볼 때 남아있는 시각적 데이터로부터 손상된 영역의 내용을 추측할 수 있다. 그러나 손상된 영역은 단 한 가지의 내용이 아닌 다양한 내용으로 채워질 수 있기 때문에 이미지 복원은 컬러화와 마찬가지로 숙련된 아티스트의 많은 시간과 노력이 필요하다.
본 논문에서는 손상된 흑백 이미지의 컬러화를 위한 자동화된 방법을 제안한다. 복원 단계에서는 DCGAN[1] 생성 모델을 복원에 사용한 Yeh et al. [2]의 방법을 BEGAN[3] 생성 모델을 사용함으로써 개선하고 컬러화 단계에서는 CNN[4] 기반의 컬러화 모델을 사용하였다. 이후 실험 결과를 통해 본 논문에서 제안한 방법이 다양한 환경에서 기존 방법보다 복원 성능이 좋으며 복원된 흑백 이미지를 통한 컬러화로 보다 정확한 색칠이 가능함을 보인다.
2. 관련 연구
이미지 복원은 이미지의 누락되거나 손상된 영역을 재구성 하는 것을 말하며 일반적으로 오래된 사진 복원 또는 이미지 편집에 사용된다. 이러한 이미지 복원 작업을 위한 다양한 방법의 연구들이 진행되어 왔다. Bertalmio et al. [5]은 Diffusion 기반의 방법으로 대상 영역 주위의 로컬 이미지 Appearance를 전파하여 손상 영역을 복원하였다. 그러나 이 방법은 스크래치와 같은 작거나 좁은 영역에만 적용이 가능하였다. Efros et al. [6]은 Patch 기반의 방법으로 이미지의 사용 가능한 부분에서 유사한 영역을 검색하고 대상 영역에 붙여 넣어 손상 영역을 복원하였다. 그러나 이 방법은 복원에 필요한 텍스처가 입력 이미지에 없을 때에는 복원이 불가능하다. Hays et al. [7]은 데이터베이스 안에서 입력 이미지와 가장 유사한 이미지를 검색한 다음 일치하는 영역을 잘라 손상 영역에 붙여 넣어 이미지를 복원하였다. 그러나 이 방법 역시 데이터베이스에 입력 이미지와 유사한 이미지가 없을 경우 복원이 어렵다.
최근에는 딥러닝 기반의 방법들이 좋은 결과를 보여주고 있다. Pathak et al. [8]은 최근 영상 처리 분야에서 활발하게 활용되고 있는 CNN을 사용하여 입력된 Context에 맞는 손상된 영역을 예측하였다. 그러나 이 방법은 손상된 영역이 임의의 위치와 모양일 경우 복원 결과가 흐릿하고 비현실적인 경향이 있었다. Yeh et al. [2]은 DCGAN을 사용한 방법으로 손상된 이미지의 손상된 영역 주변 Context에 매치되는 이미지를 생성할 수 있는 Encoding을 생성 모델에서 찾아 이미지를 생성하고 복원에 사용하였다. 본 논문의 복원 단계에서는 Yeh et al. [2]의 방법을 개선하기 위해 BEGAN 생성 모델로 교체하여 사용하였다.
이미지 컬러화는 Grayscale 이미지를 사실적인 컬러 버전으로 출력하는 작업을 말하며 오래된 흑백 사진 컬러화 또는 이미지 편집에 사용된다. 이러한 컬러화를 위한 다양한 방법의 연구들이 진행되어 왔다. Levin et al. [9]은 Scribble 기반의 방법으로 사용자가 지정한 낙서의 색을 전체 이미지로 전파하여 컬러화 하였다. 그러나 이 방법은 일일이 사용자가 알맞은 컬러를 지정하여야 하며 많은 시행착오가 요구되었다. Welsh et al. [10]은 컬러화 하려는 대상 이미지와 유사한 Reference Image의 색상을 활용하여 컬러화 하였다. 그러나 이 방법은 사용자가 컬러화 하려는 이미지와 유사한 참조 이미지를 제공해 주어야 한다.
최근에는 컬러화 기법에서도 딥러닝 기반의 방법들이 좋은 결과를 보여주고 있다. Iizuka et al. [11]은 CNN 기반의 방법으로 개선된 신경망을 통해 Global Feature와 Local Feature를 동시에 사용하여 이미지 전반적으로 일관되고 좋은 품질의 컬러화를 수행하였다. 본 논문의 컬러화 단계에서는 CNN 기반의 모델을 만들어 컬러화에 사용하였다.
최근 합성곱 신경망은 인공 신경망의 특수한 변형으로 자연어 처리, 영상 인식 등 다양한 분야에 성공적으로 적용되고 있다. 합성곱 신경망은 기본적으로 여러 개의 합성곱 레이어와 서브 샘플링 레이어 그리고 일반적인 신경망 레이어로 구성된다. 합성곱 레이어에서는 여러 합성곱 레이어를 지나 low-level의 특징부터 시작하여 high-level의 특징까지 입력 데이터의 특징을 추출하고, 서브 샘플링 레이어에서는 데이터의 크기를 줄이며, 일반적인 신경망 레이어인 완전 연결 레이어에서는 추출된 특징을 통해 분류 작업을 한다.
최근 생성적 적대신경망[12]이 데이터 증강, 이미지 복원 등 다양한 응용 분야에 성공적으로 적용되고 있다. 생성적 적대신경망은 생성 모델을 훈련하기 위한 프레임워크로 훈련 데이터 샘플의 잠재적 분포를 추정하고 그 분포에서 새로운 샘플을 생성하는 것을 목표로 한다. 이 프레임워크는 생성기와 판별기로 불리우는 두 개의 적대적인 네트워크로 구성된다. 생성기는 훈련 데이터 샘플의 잠재적인 분포를 포착하고 새로운 데이터 샘플을 생성하는 것을 목표로 하며, 판별기는 생성된 샘플과 학습 데이터 샘플을 가능한 정확하게 구분하는 것을 목표로 번갈아 가며 학습한다. 학습이 끝나면 생성기는 학습 데이터와 동일한 분포에서 나오는 샘플을 생성할 수 있게 된다. 그러나 생성기와 판별기 사이에 균형을 맞추기 어려운 등의 이유로 학습이 어렵다. 이에 따라 최근 들어 학습을 안정화시키기 위한 많은 변형이 나오고 있다. 본 논문에서는 생성적 적대신경망의 변형 중 최근 시각적으로 큰 성능 향상을 보여준 BEGAN을 복원에 사용한다.
3. 제안 방법
본 장에서는 본 논문에서 제안하는 손상된 이미지에 대한 컬러 복원 시스템을 복원 단계와 컬러화 단계로 나누어 설명한다. 전체 프레임워크는 Fig. 1과 같다. 복원 단계에서는 손상된 흑백 이미지와 손상된 영역 마스크 그리고 랜덤 노이즈 벡터를 생성 모델의 입력으로 하여 손상된 흑백 이미지를 복원한다. 생성 모델과 복원의 상세한 과정은 3.1 절에서 자세히 서술되어 있다. 컬러화 단계에서는 복원 단계에서 복원된 흑백 이미지를 컬러화 모델의 입력으로 하여 컬러화를 수행한다. 컬러화 모델은 3.2 절에서 자세히 서술되어 있다. 각 단계의 결과는 Fig. 2와 같다. 또한 3.3 절에서는 두 모델 학습에 사용된 학습 데이터 셋과 파라미터에 대하여 자세히 서술하고 있다.
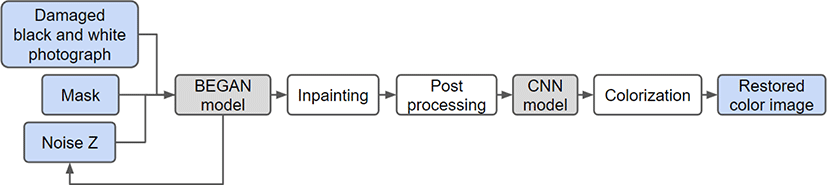

손상된 흑백의 이미지를 복원하는 단계에서는 최근 제안된 Yeh et al. [2]의 방법을 개선하여 사용하였다. Yeh et al.은 표준 DCGAN 생성 모델을 통해 손상된 영역 주변 픽셀의 Context 기반으로 손상된 영역의 자세한 내용을 예측하였다. DCGAN 생성 모델은 기존의 GAN 모델에 비해 고품 질의 그럴듯한 이미지를 생성할 수 있으나 여전히 만족스런 품질이라고 하기는 어렵다. 또한, 해상도가 높을수록 생성된 이미지와 학습 데이터 이미지를 판별기가 구분하는 것이 쉬워지므로 고해상도 이미지 생성이 어려우며 때문에 표준 DCGAN은 64x64의 낮은 해상도를 갖는다. 따라서 표준 DCGAN 모델에서 생성된 이미지를 사용하는 기존 복원 방법은 복원 가능한 해상도가 낮으며 복원의 품질도 우수하지 못하였다.
본 논문에서는 최근 고품질의 결과로 각광받고 있는 Berthelot et al. [3]의 BEGAN 생성 모델을 사용한다. BEGAN 생성 모델은 단순하지만 강력한 구조로 빠르고 안정적인 학습과 수렴이 가능하며 학습의 안정성을 위해 판별기와 생성기 사이의 균형을 조정해주는 개념이 존재한다. 구체적으로 BEGAN은 기존의 GAN 생성 모델들처럼 Data Distribution을 맞추기 위해 학습하는 대신 Auto-Encoder Loss Distribution을 맞추기 위해 학습한다. 이를 위해 판별기에 Auto-Encoder[13] 구조를 선택하였으며 학습 데이터 이미지와 생성된 이미지 각각에 대하여 Auto-Encoder로 복원되기 전 그리고 복원된 후 이미지 사이의 Loss를 계산한다. 그 다음 학습 데이터 이미지의 Image-wise Loss 정규분포와 생성된 이미지의 Image-wise Loss 정규분포 사이의 Wasserstein Distance[14]를 계산한다.
BEGAN의 논문에서는 L이 Pixel-wise Auto-Encoder Loss라 할 때 L(v)를 다음과 같이 표기하였다[3].
또한, 학습을 돕기 위하여 실제 이미지와 생성된 이미지의 Auto-Encoder Loss 분포의 기대값이 동일해질 때까지 균형을 맞춰준다. 학습을 안정성을 위해 판별기와 생성기 사이의 균형을 조정해주는 이 개념은 감마로 표현하며 다음과 같이 표기하였다[3].
여기서 감마값이 높아지면 generator에 조금 더 집중하게 되어 결과 이미지가 다양해지며, 감마값이 낮아지면 discriminator에 조금 더 집중하게 되어 결과 이미지가 덜 다양해지는 대신 퀄리티가 좋아지게 된다. 최종적인 BEGAN의 목표는 다음과 같다[3].
여기서 는 원본 이미지, zD와 zG는 z로부터의 샘플, θD는 discriminator에 대한 파라미터이며, θG는 generator에 대한 파라미터, kt는 감마값을 조정 위한 값이다. 즉, k는 생성기에 대한 가중치이며 k0은 0으로 초기화 된다. 따라서 초기에 생성기에서 구별하기 쉬운 값이 출력되어도 k값이 작아 판별기는 쉽게 만족하지 않게 되며 학습 도중 생성기와 판별기 사이의 균형을 맞춰주게 된다. 이러한 BEGAN 생성 모델을 기존 방법에서 사용하던 DCGAN 생성 모델 대신 복원에 사용하면 복원 결과의 해상도와 품질이 더 좋아질 것으로 기대하였다.
복원은 다음과 같은 순서로 진행된다. 먼저 원하는 유형의 이미지를 생성하도록 생성 모델을 학습한다. 이 때 BEGAN 생성 모델이 사용된다. 그 다음 학습된 생성 모델에 랜덤 노이즈 벡터 z를 입력하여 초기 이미지를 생성한다. 다음으로 초기 생성된 이미지와 손상된 이미지 그리고 손상된 영역 마스크를 통해 손상된 이미지에 가장 가까운 이미지를 생성할 수 있도록 z를 최적화한다. 이를 위한 Loss를 구하는 식은 다음과 같다.
여기서 W는 가중치 마스크로 손상된 영역에 가까울수록 해당 픽셀의 중요성이 크기 때문에 주변 손상된 픽셀의 수에 따라 가중치를 주는 것을 의미한다. 이렇게 정의된 Loss를 사용하여 입력 z에 대한 역 전파를 통해 최적화 된 z를 구 하지게 된다. 이 과정에서는 미리 정해진 반복 횟수만큼 반복하며 수식으로는 다음과 같이 쓸 수 있다.
다음으로 구해진 최적화 된 z를 통해 복원에 알맞은 이미지를 생성한다. 다음으로 생성된 이미지와 손상된 이미지에 입력 마스크를 통해 알파 블렌딩을 수행하여 복원한다. 마지막으로 복원했을 때 손상된 영역 주변과 생성된 영역의 픽셀이 조화롭지 않을 수 있기 때문에 간단한 후처리를 해 주며 여기서는 Poisson Blending을 사용하였다[15]. 이는 이미지의 세부 정보를 보존하면서 입력 이미지의 컬러와 일치하도록 컬러를 Shifting 하는 것으로 이러한 과정을 통해 손상된 흑백 이미지의 흑백 복원이 완료된다.
앞서 복원된 흑백 이미지를 컬러화하기 위한 컬러화 모델은 이전에 제안된 CNN 기반의 모델들을 참고하여 Table. 1과 같이 구성하였다. 본 논문에서는 얼굴 이미지만을 대상으로 하기 때문에 비교적 간단한 구조를 사용하였다. 여기서 컨볼루션 레이어는 컨볼루션-배치 정규화-ReLU 활성 함수로 구성하였다. 또한 이미지의 원래 크기로 변환하기 위해 전치 컨볼루션 레이어를 사용하였다[16]. 출력 레이어에서는 Sigmoid 활성 함수를 사용하였으며 Loss Function으로 MSE(Mean Squared Error), 모델 최적화를 위해 ADAM 최적화를 사용하였다.
컬러화 모델의 입력으로는 L*a*b* Color Space에서의 밝기를 나타내는 L* 값을 사용하며 출력으로는 색을 나타내는 a*b* 값을 사용한다. 따라서 흑백 이미지가 컬러화 모델에 입력되면 여러 컨볼루션 레이어를 지나 알맞은 a*b* 값을 추정하게 된다. 그리고 추정된 a*b* 값과 입력에 사용된 L* 값을 조합하여 컬러 복원된 최종 결과 이미지가 얻어진다.
앞서 언급한 BEGAN 생성 모델과 CNN 모델을 학습하기 위한 데이터 셋은 CelebFaces Attributes(CelebA) 데이터 셋[17]을 추가적으로 가공하여 사용하였다. CelebA 데이터 셋은 200,000개 이상의 유명 인사 이미지가 포함된 대규모 얼굴 속성 데이터 셋이다. 여기에는 큰 포즈 변화와 다양한 배경이 포함되어 있으며 Face Attribute Recognition, Face Detection 등의 컴퓨터 비전 작업을 위한 훈련과 테스트에 사용할 수 있다. 본 논문에서는 원활한 학습을 위해 가려진 얼굴과 같은 부적절한 데이터를 제거하였다. 따라서 Paul Viola와 Michael Jones의 Haar Feature-based Cascade Classifier[18]를 사용하여 Face Detection을 수행하였고 찾아진 얼굴을 128x128의 해상도로 조정하여 사용하였다. 이를 통해 부적절한 데이터가 제거되었으며 결과적으로 학습에 154,224개의 이미지, 테스트에 2,029개의 이미지가 사용되었다. 또한, 테스트에는 추가적으로 LFW(Labeled Faces in Wild)[19]의 데이터와 인터넷에서 임의로 찾은 데이터 또한 사용되었다.
두 모델은 모두 텐서플로우(TensorFlow)를 사용해 구현하였다. 복원 작업을 위한 BEGAN 생성 모델의 구조는 BEGAN 논문의 방법을 따랐다. 본 논문에서는 128x128의 이미지를 학습하기 위하여 Gamma는 0.7, 배치 사이즈는 16, 최적화로 Adam, 학습률로 0.0001을 사용하였다. 컬러화 작업을 위한 CNN 모델은 앞서 언급하였던 구조와 같으며 학습에는 배치 사이즈는 16, 최적화로 Adam, 학습률로 0.001을 사용하였다.
4. 실험 결과
본 실험에서는 제안한 방법의 타당성을 입증하기 위해 컬러화 전 복원 작업 여부 및 생성 모델에 따른 성능 비교를 수행하고, 다양한 유형의 데이터와 마스크에 대한 성능 변화를 보여준다. 또한, 질적 평가와 양적 평가 결과 그리고 실패 사례를 서술한다.
손상된 이미지에 대한 복원 작업 여부가 최종 컬러화 결과에 미치는 영향을 알아보기 위해 비교하여 실험한다. 실험은 컬러화를 한 후 복원한 결과와 복원한 후 컬러화를 한 결과로 나누어 진행한다. Fig. 3(a)는 컬러화를 한 후 복원한 결과로 컬러화의 결과가 손상된 영역에 영향받아 주변 컬러가 이상하게 색칠됨을 볼 수 있다. 또한 이는 복원에 사용될 이미지가 잘못된 컬러로 생성되게 하므로 최종적으로 조화롭지 않은 컬러의 복원 결과가 나오게 된다. 반면 Fig. 3(b)는 복원 후 컬러화를 한 결과로 컬러 정보가 아닌 흑백 정보만을 통해 복원하므로 구조에 더 집중하여 흑백 이미지를 복원할 수 있다. 또한 잘 복원된 흑백 이미지를 통해 컬러화 작업을 진행함으로써 최종적으로 조화로운 컬러가 나온다. 이러한 결과를 기반으로 본 논문에서는 복원 작업을 수행한 후 컬러화를 진행한다.

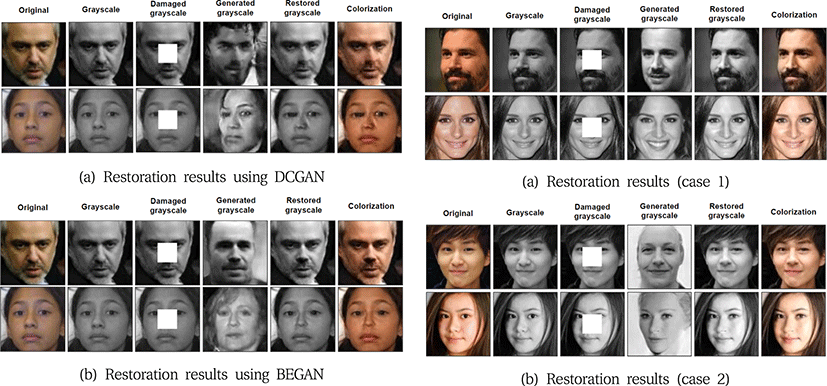
DCGAN 생성 모델을 사용한 기존 복원 방법[2]과 BEGAN 생성 모델을 사용한 본 논문의 복원 방법 성능 차이를 확인하기 위하여 각 복원 결과를 비교하여 실험한다. 이전 방법에서 사용한 DCGAN 생성 모델은 표준적인 DCGAN 생성 모델로서 64x64의 이미지로 복원의 해상도가 제한된다. 따라서 명확한 비교를 위해 DCGAN 복원 결과를 128x128 해상도로 조정하여 비교한다. Fig. 4(a)는 DCGAN 생성 모델을 사용한 기존 복원 방법으로서 생성된 흑백 이미지의 품질이 그리 좋지 못하였다. 생성된 이미지에는 노이즈가 포함되어 있으며 최종적으로 컬러 복원된 결과 역시 만족할 수 없는 품질인 경우가 많았다. Fig. 4(b)는 BEGAN 생성 모델을 사용한 본 연구의 복원 결과로서 생성된 흑백 이미지가 대체적으로 좋은 품질을 보여주고 있다. 최종적으로 컬러 복원된 결과 역시 만족할 수 있는 품질인 경우가 많았다.
인종이 달라짐에 따라 결과가 어떻게 달라지는지 알아보기 위하여 다양한 인종별로 성능을 실험했다. 실험을 위한 이미지는 백인, 흑인, 황인으로 나누었으며 결과는 Fig. 5와 같다. 학습에 사용된 CelebA 데이터 셋은 주로 백인의 이미지로 구성되어있으며 그 다음으로는 흑인의 이미지가 많고 황인의 이미지는 거의 없다. 따라서 일반적으로 서양인의 큰 코와 동양인의 작은 코와 같은 인종별 특징의 차이로 동양인의 경우 어색한 복원 결과가 나올 것이라 예상되었다. 실험 결과 대부분의 경우 좋은 복원 결과를 보였으나 황인의 경우 예상대로 다소 어색한 복원 결과가 존재하였다.

다양한 유형의 마스크에 따라 복원의 성능이 어떻게 달라지는 지 알아보기 위하여 마스크 유형별로 성능을 실험한다. 실험에 사용한 마스크는 총 4개의 형태로 O, X, -, 왼 쪽 절반의 마스크다. 여기서 O 마스크는 주로 얼굴 윤곽을 일부를 함한 부분, X 마스크는 주로 코 전부와 눈 일부분, - 마스크는 주로 입 부분, 왼쪽 절반 마스크는 왼쪽 절반이 제거된다. Fig. 6(a),(b),(c)의 O, X, - 마스크에서 대부분의 복원은 성공적이었다. 그러나 Fig. 6(d)와 같은 왼쪽 절반이 사라진 경우 복원에 실패하는 경우가 많았다. 이는 정보가 한쪽 면에서만 주어져 조건이 되는 영역이 작아졌기 때문으로 추정된다. 이러한 줄어든 조건은 많은 이미지가 복원에 사용가능해지며 결과적으로 어색한 복원 결과가 나올 수 있다.

복원된 흑백 이미지를 수치를 통해 평가한다. 평가를 위해 논문의 흑백 복원 결과와 인종별, 다양한 마스크별, DCGAN 생성 모델을 사용한 흑백 복원 결과를 흑백 원본 Ground Truth 이미지와의 PSNR과 SSIM을 통해 비교한다. 각 결과에는 10개의 이미지를 임의로 뽑아 사용하였다.
| 흑인 | 황인 | 백인 | 다양한 마스크 | DCGAN | BEGAN | |
|---|---|---|---|---|---|---|
| PSNR | 24.55 | 28.11 | 23.83 | 20.25 | 26.90 | 26.64 |
| SSIM | 0.9310 | 0.9600 | 0.9395 | 0.7844 | 0.9399 | 0.9419 |
인종별 결과는 질적 결과와 다르게 황인의 경우가 제일 높은 수치가 나왔다. 다양한 마스크별 결과는 왼쪽 절반 등 보다 많은 영역이 제거되었으므로 다른 값들보다 낮은 수치를 보인 것으로 추정된다. BEGAN 생성 모델을 사용한 흑백 복원 결과는 시각적으로 보았을 때 DCGAN 생성 모델을 사용한 결과보다 훨씬 좋은 품질을 보였으나 수치 평가에서는 다른 결과를 보였다. 이는 Ground Truth 이미지와 다르지만 보기에는 자연스럽게 복원됐기 때문으로 보인다. 종합적으로 보았을 때 수치적 결과는 판단기준으로 모호한 것으로 추정된다.
사용자 연구 또한 수행해보았다. 총 5명의 사용자에게 복원의 자연스러움을 평가해줄 것을 요청하였다. 설문조사는 다음과 같이 진행되었다. 복원된 이미지만을 임의로 40장 뽑아 사용자들에게 1장씩 이미지를 보여주며 진짜와 가짜를 판별해줄 것을 요청하였다. 그 결과 대략 50%로 사용자들을 속일 수 있었다. 속일 수 없었던 이유로는 뚜렷한 경계선, 동양인의 얼굴에 맞지 않는 큰 코, 여자 얼굴에 있는 굵은 수염 등의 부자연스러움이 원인으로 추정된다.
컬러 복원 실패 사례는 다음과 같다. Fig. 7 상단의 그림은 손상된 이미지가 여자이지만 굵게 수염이 난 이미지로 복원되었다. Fig. 7 중단의 그림은 손상된 이미지에 이미 눈이 있지만 눈이 있는 이미지가 복원에 사용되었다. Fig. 7 하단의 그림은 손상된 이미지가 남자이지만 다른 성별의 이미지가 복원에 사용되었다. 본 논문의 복원 방법은 근본적으로 Low-Level의 픽셀 Context를 고려하며 눈의 크기, 사람의 성별 정보 등의 High-Level의 Context를 고려하는 것이 아니기 때문에 주변 픽셀과는 잘 일치하지만 어색한 이미지들을 생성하는 것으로 추정된다.

5. 결론 및 향후계획
본 논문에서는 CNN을 이용한 컬러화 모델과 BEGAN 생성 모델을 이용한 복원을 통해 손상된 흑백 얼굴 이미지를 컬러로 복원하기 위한 방법을 제안하였다. 기존 컬러화 방법은 흑백 이미지에 손상된 영역이 있을 때 손상된 영역 주변의 컬러화에 문제에 생긴 반면 제안한 방법은 이를 해결하기 위해 컬러화 전 BEGAN 생성 모델을 통해 복원 단계를 추가하여 컬러화 작업을 하였다. 이 과정에서 기존 복원 방법에 비해 큰 해상도와 고품질의 복원 결과를 보여주었으며 또한 복원을 마친 흑백 이미지의 컬러화를 통해 기존 컬러화 방법 대비 자연스러운 결과를 보여주었다.
본 논문의 한계로는 논문에서 사용된 복원 방법이 Low-level의 Context 그리고 손상된 영역 주변만을 고려하기 때문에 전체적인 얼굴의 방향성이나 또는 원래의 눈과 복원된 눈이 다른 방향을 바라보는 등의 문제가 있음을 확인하였다. 또한 조건이 작은 경우 어색한 복원 결과를 보여주는 경우가 많음을 확인하였다.
향후에는 발전된 생성 모델의 적용 또는 High-level의 Context를 고려한 얼굴의 방향성 등의 정보를 추가하여 복원함으로써 개선할 것이며 이로 인해 성능이 향상 될 것으로 기대한다.