




1. 서론
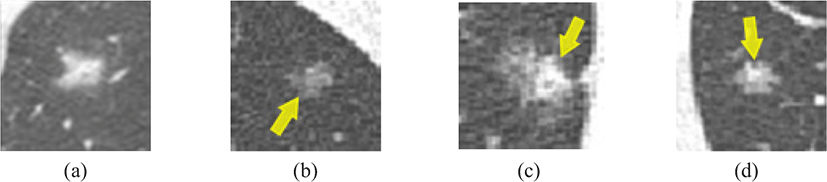
일반적으로 폐 결절(pulmonary nodule)은 폐 내부에 생긴 지름 3cm 미만의 작은 구상 병변으로 최근 컴퓨터 단층촬영(Computed Tomography; CT)이 보편화되고 획득되는 영상의 화질이 개선되면서 이전에는 발견되지 못했던 1cm 미만의 간유리음영 결절(ground-glass nodule)을 보이는 병변도 폐 결절에 준하여 임상적 접근을 하고 있다[1]. 간유리음영 결절은 흉부 CT 영상에서 폐 실질(lung parenchyma)에 비해 상대적으로 밝기값이 높고 흐릿하게 나타나는 간유리음영 성분(Ground-glass Opacity)을 포함하며, 간유리음영 성분만 포함하고 있는 순수 간유리음영 결절(pure GGN)과 간유리음영 성분과 그 내부에 고형 성분을 포함하고 있는 혼합 간유리음영 결절(part-solid GGN)로 분류된다[2]. 최근에는 결절 내부에 위치하는 고형 성분의 특성과 악성도 간 상관관계가 있다는 연구 결과가 보고되었으며 이에 따라 2013년 플라이슈너 소사이어티(Fleichner Society) 가이드라인에서는 간유리음영 결절 추적 시, 순수 간유리음영 결절, 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절, 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절을 구분하여 기준을 제시했고[3], 2017년도 플라이슈너 소사이어티 가이드라인에서는 고형 성분의 크기로 나누는 기준이 5mm에서 6mm로 변경되었으며, 결절 내부의 고형 성분의 크기에 따른 치료법을 다르게 할 것을 제안하는[4] 등 간유리음영 결절 진단 시 결절 내부의 고형 성분의 크기에 대한 관심이 지속적으로 이어져 오고 있다. Figure 1은 흉부 CT 영상에서 나타나는 폐 결절 유형별 특성을 나타내는 영상으로Figure 1(a)의 고형 결절에 비해 Figure 1(b)의 순수 간유리음영 결절은 간유리음영 성분이 상대적으로 어두운 밝기값을 보이고, Figure 1(c)의 혼합 간유리음영 결절은 흐릿하게 나타나는 간유리음영 성분과 내부에 밝게 나타나는 5mm 이상의 고형 성분을 함께 가지고 있다. Figure 1(d)의 혼합 간유리음영 결절은 흐릿하게 나타나는 간유리음영 성분과 내부에 밝게 나타나는 5mm 미만의 고형 성분을 함께 포함하고 있으나 그 크기가 작아 Figure 1(b)의 순수 간유리음영 결절과 유사한 밝기값 특성을 보인다. 따라서 간유리음영 결절을 내부 고형 성분의 크기 및 포함 여부에 따라 분류하는 것이 필요하다.
흉부 CT 영상에서 폐 결절을 분류하기 위한 관련연구는 크게 두 가지 접근 방법이 있다. 고식적인 특징(hand-crafted feature)을 이용해 특징을 추출하여 기계학습 기반의 분류방법으로 분류하는 접근기법과 딥러닝 기반의 분류방법으로 분류하는 접근기법이다. 먼저 고식적인 특징을 이용해 분류하는 관련연구로는 히스토그램 특징, 백분위 CT 밝기값 특징, 텍스처 특징, 형태학적 특징 등을 이용해 특징 추출 후 서포트 벡터 머신(support vector machine; SVM), 결정 트리(decision tree), 랜덤 포레스트(random forest), K-최근접 이웃(K-nearest neighbor), 베이지안 분류기(bayesian classifier) 등의 분류기를 학습시켜 고형 결절을 악성 또는 양성 결절로 분류하는 연구들이 있다[5, 6, 7]. 폐 결절을 분류하는 연구 중 일부는 간유리음영 결절 데이터를 포함하고 있으나 연구 목적이 폐 결절을 악성도에 따라 분류하기 위한 것으로 간유리음영 결절은 일부만 포함하고 있고 간유리음영 결절 내부의 고형 성분 크기를 고려하여 분류하는 연구는 거의 이루어지고 있지 않다. 간유리음영 결절을 분류하는 연구로는 다중뷰 기반의 2529개의 특징을 추출해 랜덤 포레스트 분류기를 이용하여 간유리음영 결절의 고형 성분의 포함 여부 및 크기에 따라 순수 간유리음영 결절, 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절, 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절로 분류하는 연구가 있다[8, 9]. 고식적인 특징을 추출하여 폐 결절 및 간유리음영 결절을 분류하는 연구는 병변에 적합한 특징을 추출하므로 훈련에 사용한 병변의 특성과 유사 데이터에서는 좋은 성능을 보일 수 있지만 상이한 데이터에 적용하면 분류 성능이 낮아지는 한계점이 있다.
최근 들어 폐 영상 데이터베이스 컨소시엄(The lung Image Database Consortium; LIDC)과 같이 폐와 관련된 데이터베이스들이 공공 데이터로 제공되면서 의료 영상에 딥러닝 기법이 활용되고 있으며 폐 결절 분류를 위한 연구들은 다음과 같다. Tajbakhsh 등은 악성 결절을 6가지 타입의 양성 결절과 분류하는 6개의 인공신경망(ANN)을 이용해 획득한 결절 타입에 대한 확률의 평균값으로 최종 분류결과를 얻는 다중 MTANNs(Massive-Training ANN)을 제안하고 컨볼루션 신경망(CNN)과의 비교 실험을 통해 제안 방법이 더 우수한 결과를 보임을 제시하였다[10]. Liu 등은 폐 결절 내부 정보와 주변 정보를 함께 학습하기 위해 세 가지 종류의 다해상도 영상을 채널 정보로 사용하는 다중뷰 컨볼루션 신경망을 이용하여 악성 또는 양성 결절로 분류하였다[11]. Shen 등은 폐 결절의 내부 정보를 효과적으로 추출하기 위해 두 개의 중간 컨볼루션 레이어에서 획득된 특징맵에서 중앙부를 잘라내어 최종 특징맵과 연결하는 Multi-crop 컨볼루션 신경망을 제안하여 악성 또는 양성 결절로 분류하였다[12]. Dey 등은 결절의 내부 정보와 주변 정보를 함께 고려하기 위해 두 가지 3차원 다해상도 영상을 입력으로 사용하는 DenseNet을 이용해 악성 또는 양성으로 분류하였다[13]. 딥러닝을 이용한 폐 결절 분류 연구는 대부분 고형 결절을 분류하는 연구가 다수이며, 간유리음영 결절을 일부 포함한 경우에도 내부 고형 성분의 크기를 고려해 분류하고 있지 않다.
본 논문에서는 간유리음영 결절의 밝기값, 재질 및 형상 증강 입력 영상의 활용을 제안하고, GGN-Net을 이용해 간유리음영 결절을 결절 내부 고형 성분의 포함 여부 및 크기에 따라 순수 간유리음영, 고형 성분의 크기가 5mm 미만인 혼합 간유리음영, 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 총 세 개의 클래스로 자동 분류하는 방법을 제안한다.
2. GGN-Net을 이용한 간유리음영 결절 분류
CT 영상의 밝기값은 X-선이 몸을 투과할 때 부위별 밀도에 의해 흡수 정도를 상대적으로 표현하는 HU(Hounsfield Unit)으로 나타내며 물은 0HU, 공기는 –1000HU, 뼈는 1000HU로 지정하고, 선형변환(linear transformation) 수식에 따라 부위별 정해진 절대적인 수치범위가 지정된다. 그러나 환자 데이터에 따라 촬영된 CT 장비가 상이하거나 동일한 CT 장비에서도 촬영 프로토콜이 다르면 촬영기기 내에서 영상을 재구성하는 과정에서 밝기값에 일부 차이가 있을 수 있다. 따라서 CT 영상에서 결절을 비롯한 폐 구조물이 잘 보이도록 정한 폐 윈도우 셋팅 값을 참고하여 식 (1)과 같이 0~255범위로 데이터 간 밝기값 정규화를 수행한다.
이 때, WL과 WW는 윈도우 레벨(windowing level)과 윈도우 폭(window width)으로 각각 –700HU, 1500HU로 지정한다. P[i]는 정규화된 입력 영상의 i번째 화소를 의미하고, p[i]는 본래 입력 영상의 i번째 화소를 의미하며, low는 밝기값 정규화 범위의 최소값, high는 밝기값 정규화 범위의 최대값을 나타낸다.
또한, CT 영상은 촬영 프로토콜에 따라 FOV(Field Of View)가 달라 화소 크기가 상이하여 데이터 간 화소 공간을 맞춰주는 화소 공간 정규화(pixel spacing normalization)를 수행한다. 이 때, 본 논문에서 사용한 실험데이터의 화소 공간은 0.52~0.81mm2 범위를 가지므로 가장 작은 화소 공간인 0.52mm에 맞춰 화소 공간 정규화를 수행한다.
간유리음영 결절은 내부 고형 성분의 유무 및 크기에 상관없이 간유리음영 성분을 포함하고 있고, 내부 고형 성분의 크기가 작은 경우 혼합 간유리음영 결절과 순수 간유리음영 결절 간 시각적 구분이 어려우며, 대부분의 간유리음영 결절의 직경이 3cm 미만의 작은 크기를 가지므로 결절의 특징을 잘 반영할 수 있는 정보 제공이 필요하다. 따라서 본 절에서는 밝기값 정보 뿐 아니라 결절 내부의 재질 및 형상 증강 입력 영상을 제안한다.
입력 영상을 구성하는 관심 영역(Region of Interest; ROI)은 결절이 영상 가운데 위치할 수 있도록 지정한다. 이후, 간유리음영 결절의 특성이 가장 잘 반영된 56x56크기를 가지는 ROI를 입력 영상으로 사용한다. 입력 영상의 각 특징은 다음과 같다. Figure 2(a)는 폐 결절 분류 네트워크에서 일반적으로 사용하는 입력 영상으로 결절 내부와 결절 주변의 혈관 및 흉벽 등 주변 영역의 밝기값 정보를 함께 고려하는 입력 영상이다. Figure 2(b)는 간유리음영 결절의 크기가 작아 주변 혈관이나 흉벽 정보에 의해 결절이 오분류되는 가능성을 줄이기 위해 결절을 두 배의 크기로 일정하게 증강하여 간유리음영 결절의 내부의 밝기값 및 재질에 집중할 수 있는 입력 영상이다. Figure 2(c)는 혈관 및 흉벽 정보를 제거하여 결절의 크기 및 형상 정보에 집중할 수 있는 입력 영상이다.

간유리음영 결절과 주변 혈관 및 흉벽 등의 밝기값을 고려한 입력 영상 뿐 아니라 간유리음영 결절 내부의 재질과 결절의 형상 정보를 효과적으로 추출할 수 있는 입력 영상을 함께 고려함으로써 결절의 직경이 3cm 미만인 간유리음영 결절에서 내부 고형 성분의 유무 및 특징을 효과적으로 반영할 수 있다.
기존 폐 결절 분류 네트워크의 경우 결절의 다양한 정보를 고려하기 위해 다해상도 영상을 채널 정보로 사용하거나 입력 영상의 일부 영역을 특징맵으로 사용하는 등 하나의 네트워크 구조만 이용해 훈련한다는 한계가 있다. 따라서 본 절에서는 간유리음영 결절을 순수 간유리음영 결절(GGN-P), 결절 내부의 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절(GGN-S), 5mm 이상인 혼합 간유리음영 결절(GGN-L) 총 세 개의 클래스로 분류하기 위해 다양한 입력 영상을 여러 개의 네트워크를 모듈을 통해 획득한 특징맵을 내부 네트워크에서 통합하여 훈련하는 간유리음영 결절 네트워크(GGN-Net)를 제안한다.
GGN-Net의 입력 영상은 Figure 3과 같이 밝기값 정보, 증강을 이용한 결절 내부의 재질 정보, 배경을 제거한 결절의 형상 정보가 반영된 입력 영상의 조합을 사용한다. 이 때, 각 입력 영상은 3차원적 공간 정보를 반영하기 위해 측상면(axial plane), 관상면(coronal plane), 시상면(sagittal plane)을 사용하고, 간유리음영 결절의 특징이 가장 잘 반영된 영상을 사용하기 위해 총 9개의 입력 영상을 사용한다. 각각의 입력 영상은 특징맵 생성을 위한 두 개의 컨볼루션 계층(convolution layer)과 두 개의 최대값 풀링 계층(max-pooling layer)으로 이루어진 컨볼루션 모듈을 거쳐 완전 연결 계층(fully-connected layer)에서 추출된 특징들을 모두 합한다. 컨볼루션 계층은 5x5와 3x3 크기의 필터를 사용하여 컨볼루션(convolution) 연산을 수행하며 각각 64장, 128장의 특징맵을 생성한다. 활성화 함수로는 ReLU(rectified linear unit)[14]함수를 사용하고, 입력 영상의 출력 크기가 줄어드는 것을 방지하기 위해 제로패딩(zero-padding)을 적용한다. 최대값 풀링 연산 계층은 2x2 크기 필터를 사용하여 가장 높은 값을 특징값으로 추출하여 풀링하는 연산을 수행한다. 각 컨볼루션 모듈에서 추출된 9개의 특징맵을 통합하기 위해 입력된 여러 요소를 하나의 요소로 생성해주는 연결(concatenate) 연산을 수행한다. 연결된 특징값은 완전 연결 계층을 거쳐 총 1024개의 특징으로 만들어진다. 1024개의 뉴런들은 과적합을 피하기 위해 랜덤하게 뉴런들의 활동을 50% 제한하는 드랍아웃(dropout)계층을 거쳐 소프트맥스(softmax) 함수를 이용해 세 개의 클래스의 확률값으로 출력된다.
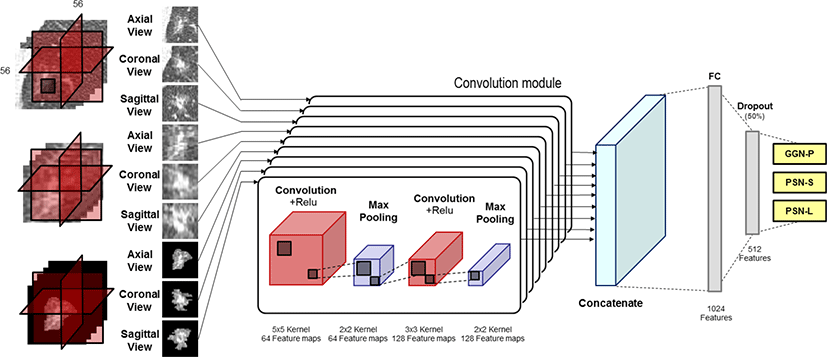
제안하는 네트워크는 다양한 입력 영상에서 컨볼루션 모듈을 통해 추출한 특징값들을 통합해서 훈련함으로써 각기 다른 영상에서 가장 의미 있는 값으로 추출된 특징값들이 함께 고려되어 결절의 분류 성능을 향상시킬 수 있다. 또한, 실험에 사용되는 간유리음영 결절들의 크기는 모두 3cm 미만으로 입력 영상의 크기가 작기 때문에 고단계 특징(high-level feature)을 추출할 수 있는 깊은 네트워크가 아닌 저단계 특징(low-level feature)을 추출하는 얕은 네트워크로 구성한다.
3. 실험 및 결과
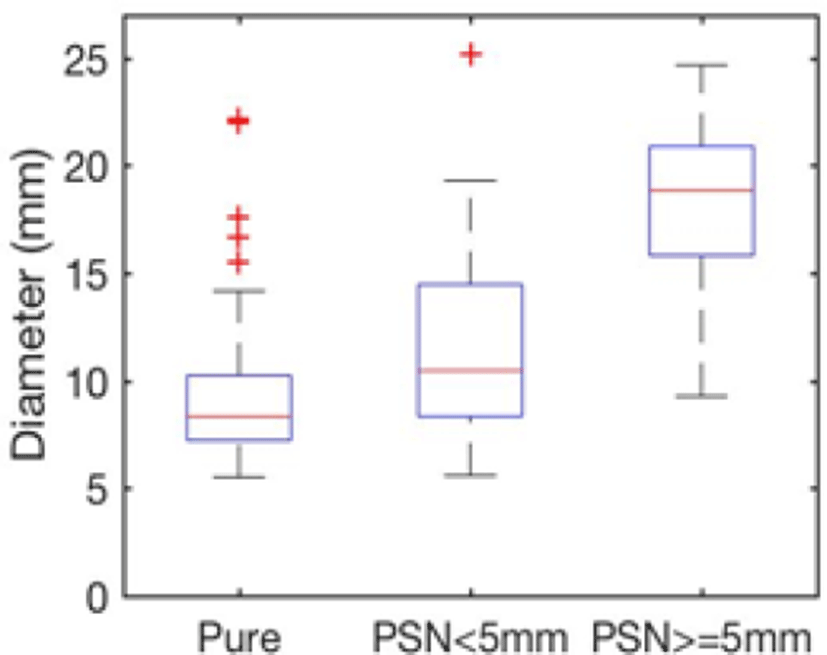
실험을 위해 사용된 데이터는 순수 간유리음영 결절 90개와 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절 38개, 5mm 이상 고형 성분의 크기를 가지는 혼합 간유리음영 결절 23개로 간유리음영 결절의 타입 선별과 고형 성분의 직격 측정은 서울대학교 병원 영상의학과 전문의에 의해 수행되었다. 실험 데이터는 총 151개의 데이터를 사용했고 간유리음영결절의 직경 분포는 Figure 4와 같다.
데이터 간 불균형 및 과적합을 해소하고, 데이터 확장(data augmentation)을 수행하기 위해 영상 생성 시 z축 방향으로 90°, 180°, 270° 회전을 적용했다. 제안 방법의 실험을 위해 훈련 데이터 셋과 테스트 데이터 셋을 4:1 비율로 랜덤하게 구성하고, 데이터 확장을 수행한 훈련 데이터는 순수 간유리음영 결절 72개, 결절 내부의 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절 71개, 결절 내부의 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절 68개 총 211개이다. 테스트 데이터 셋은 순수 간유리음영 결절 18개, 결절 내부의 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절 7개, 결절 내부의 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절 4개 총 29개이다. 훈련 및 테스트 데이터로 사용된 흉부 CT 영상은 서울대학교병원 영상의학과에서 SIEMENS Sensation -16, Definition, SOMATOM Definition CT Scanner와 Philips Brilliance-64, Ingenuity CT Scanner 5개의 기기를 이용하여 120-kVp를 이용한 low-dose 프로토콜로 촬영한 영상으로, 영상 해상도는 512x512, 화소의 크기는 0.52~0.81mm2, 슬라이스 간격은 1mm이다.
제안 네트워크 모델은 파이썬(Python) 딥러닝 라이브러리인 텐서플로우(Tensorflow)를 기반으로 구현되었으며, 네트워크 모델의 훈련과 테스트는 GeForce GTX 1080 GPU 4개가 탑재된 서버에서 수행되었다. 학습에 사용된 학습 비율(learning rate)은 0.001, 미니 배치(mini-batch) 크기는 20, 손실 함수(loss function)는 교차엔트로피(Cross-Entropy)를 사용하였고, 최적화를 위해 아담 옵티마이저(Adam Optimizer)를 사용하였다.
간유리음영 결절의 분류 성능을 평가하기 위해 각 클래스 간 분류 정확도(accuracy), 민감도(sensitivity), 특이도 (specificity)를 식(2)을 통해 측정하며, 혼동 행렬 (confusion matrix)을 이용하여 세 개 클래스 분류 결과를 제시한다.
이 때, TP는 간유리음영 결절의 해당 클래스를 옳게 분류한 개수이고, TN은 해당 클래스를 제외한 나머지 클래스를 옳게 분류한 개수이고, FP은 해당 클래스를 옳지 않게 분류한 개수이고, FN은 해당 클래스를 제외한 나머지 클래스를 옳지 않게 분류한 개수이다.
입력 영상이 간유리음영 결절 분류 결과에 미치는 영향을 비교하기 위해 Table 1과 같이 비교 입력 영상을 구성하였다. Method A는 본래의 영상을 사용하는 경우, Method B는 간유리음영 결절의 크기를 일정하게 증강하여 결절 내부 재질에 집중하는 경우, Method C는 간유리음영 결절의 형상에 집중하는 경우, Method D는 간유리음영 결절의 형상에 집중하면서 결절 내부 재질에도 집중하게 하는 경우로 Method A, B, C, D는 단일 입력 영상을 사용한 경우이다. Method E, F는 단일 입력 영상을 조합한 복수 입력 영상을 사용한 경우이다.
| Method A |

|
Method B |

|
| Method C |

|
Method D |

|
| Method E |

|
||
| Method F |

|
||
| Proposed Method |

|
||
Table 2는 입력 영상의 구성에 따른 간유리음영 결절 분류 성능을 나타내는 표이다. 밝기값 및 결절 내부 재질 정보에 집중하는 단일 입력 영상을 사용한 Method A와 B의 정확도는 72.41%, 68.97%로, 재질에 집중한 경우 본래 영상을 사용한 경우보다 순수 간유리음영 결절과 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절의 특이도가 낮았다. 결절 형상 정보를 증강하는 단일 입력 영상을 사용한 Method C의 정확도는 75.86%로 본래 영상을 사용한 경우보다 모든 클래스에서 정확도가 향상되었다. 결절 형상 정보와 내부 재질 정보를 함께 증강한 입력 영상을 사용한 Method D의 정확도는 75.86%로 Method C와 같았는데 순수 간유리음영 결절과 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절의 정확도는 크게 향상됐으나 결절의 형상과 재질의 특성이 뚜렷하지 않은 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절의 정확도가 낮아졌기 때문으로 확인되었다. Method E의 경우 Method D의 한계를 극복하고자 Method A의 입력 영상을 함께 사용하였다. 고형 성분의 크기가 5mm 미만인 혼합 간유리음영의 정확도가 개선되었으나 고형 성분의 크기가 5mm 이상인 혼합 간유리음영의 정확도는 낮아져 전체 정확성이 향상되지 않는 한계를 그대로 가지고 있음을 알 수 있었다. Method F는 Method D에 본래 영상과 결절 내부 재질을 증강한 영상을 추가 고려한 구성이다. 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절의 민감도와 특이도가 상승하였으나 순수 간유리음영 결절의 민감도와 특이도가 낮아졌기 때문으로 확인되었다. 결절 형상 정보를 증강한 영상에 본래 영상과 결절 내부 재질 정보를 증강한 영상을 함께 사용하는 제안 방법의 정확도는 82.76%로 결절의 형상과 재질의 특성이 뚜렷하지 않은 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절의 민감도가 낮은 편이나 특이도가 개선되었고, 순수 간유리음영 결절과 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절의 민감도가 개선되어 모든 방법 중 가장 높은 정확도를 보였음을 알 수 있었다.
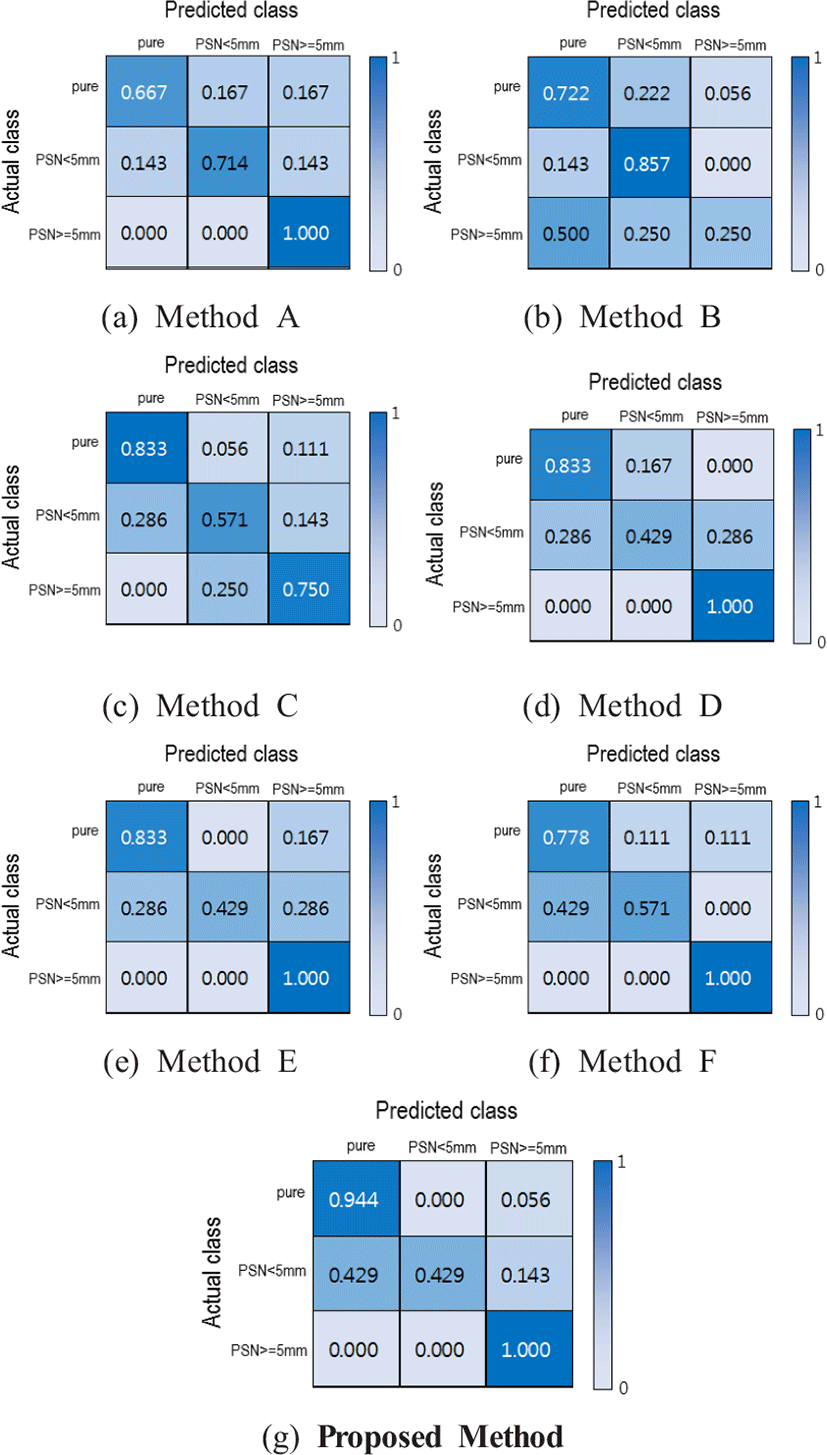
Figure 5는 클래스별 분류 성능을 확률로 나타내는 혼동 행렬이다. 혼동 행렬의 각 요소는 0~1 범위의 값을 가지며 행렬의 행은 실제 클래스, 행렬의 열은 예측 클래스를 나타내며 대각 행렬의 성분이 큰 값을 가질수록 분류 성능이 우수함을 나타낸다. Method A는 간유리음영 결절과 관련된 특징이 추출될 때 결절 주변 구조물에 영향을 받아 유사 구조물이 있는 경우 오분류 하는 경우가 있고, 특히 순수 간유리음영 결절을 고형 성분의 크기가 5mm 미만인 혼합 간유리음영과 고형 성분의 크기가 5mm 이상인 혼합 간유리음영으로 오분류 하는 경우가 발생했고, 순수 간유리음영 결절의 분류 정확성이 제안 방법보다 27.7% 낮은 결과를 보였다. Method B는 재질 정보가 증강되어 순수 간유리음영 결절과 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절의 분류 성능이 Method A에 비해 향상되었으나 관심영역을 일정하게 증강시키면서 크기가 큰 결절의 경우 경계 부분의 밝기값 정보가 손실되어 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절이 순수 간유리음영으로 오분류 되는 확률이 크게 증가하였다. Method C와 Method D는 배경에 존재하는 혈관과 흉벽 등을 제거하여 형상 정보에 집중하였기 때문에 Method A와 Method B보다 순수 간유리음영 결절의 분류 성능이 향상되었으나 결절의 형상과 재질의 특성이 뚜렷하지 않은 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절이 순수 간유리음영 결절과 고형 성분의 크기가 5mm 이상인 혼합 간유리음영 결절로 오분류되는 경우가 크게 증가하였다. Method E와 F는 밝기값과 재질 정보뿐만 아니라 결절의 형상 및 결절 내부 재질이 함께 증강되어 순수 간유리음영 결절의 정확도가 Method A에 비해 향상되었으나 Method D와 유사하게 고형 성분의 크기가 5mm 미만인 혼합 간유리음영 결절의 오분류율이 크게 증가하였다. 제안 방법에서는 밝기값 정보 뿐 아니라 결절 내부 재질 증강 정보와 결절 형상 및 재질을 함께 증강한 정보를 고려함으로써 전체 분류 성능이 가장 우수한 결과를 보였다. 특히 고형 성분의 크기가 5mm 이상인 혼합 간유리음영의 오분류율은 0%였으며, 순수 간유리음영 결절의 오분류율은 5.4%로 모든 방법 중 가장 좋은 분류 성능을 보였다.
4. 결론
본 논문에서는 흉부 CT 영상에서 간유리음영 결절을 순수 간유리음영 결절, 5mm 미만의 고형 성분을 포함하는 혼합 간유리음영 결절, 5mm 이상의 고형 성분을 포함하는 혼합 간유리음영 결절 총 3개의 클래스로 분류하기 위하여 GGN-Net을 이용한 간유리음영 결절 자동 분류 방법을 제안하였고, 결절 내부의 고형 성분 및 유무와 결절의 특성을 효과적으로 반영할 수 있도록 밝기값 정보를 고려한 입력 영상, 증강을 이용해 내부 재질의 정보를 고려한 입력 영상, 배경을 제거해 간유리음영 결절의 형상 정보를 고려한 입력 영상의 조합으로 입력 영상을 재구성하여 82.75% 정확도를 보였다. 향후 연구 방향으로는 LIDC 공공 데이터베이스 데이터를 확보하여 본 네트워크의 분류 성능에 대한 평가를 진행하고자 한다.