




1. 서론
최근 가상현실 기술이 발전하고 다양한 기기들이 보급됨에 따라 사용자의 몰입감을 증폭시키는 가상현실 콘텐츠에 대한 요구가 증가하고 있다. 기존 가상현실 콘텐츠는 대부분 버튼 방식의 일반 컨트롤러를 사용하기 때문에 사용자와 가상현실의 객체 사이의 상호작용이 부자연스럽고 직관성이 떨어지는 단점이 있다.
사용자에게 가장 자연스러운 인터페이스는 사람이 일상생활에서 사용하는 손 제스처를 가상공간 속에서도 인식할 수 있도록 하는 것이다. 이와 같은 손 제스처 인식에 대한 연구로 키넥트나 립모션과 같은 장비를 이용한 손 제스처 인터페이스에 관한 연구[1-6]가 있었지만 특화된 장비 혹은 센서가 필요하고 조명이나 거리와 같은 주변 환경에 제약을 받는다는 단점이 있었다.
최근에는 큰 규모의 데이터 세트를 수집하는 것이 용이해지고 GPU를 활용한 고성능 컴퓨팅이 보편화됨에 따라 딥러닝(Deep Learning) 기술을 이용하여 손 제스처를 인식하고자 하는 연구들이 이뤄지고 있다. 이와 관련한 기존 연구로 스테레오 비디오로부터 구한 깊이 정보와 색 정보를 이용하여 검출한 손 윤곽선 정보를 학습시켜 인식하는 연구[7], 깊이 카메라로 얻은 관절 정보를 학습하여 인식하는 연구[8] 그리고 칼라 영상과 깊이 영상을 결합하여 3차원 합성곱 신경망(Convolutional Neural Network)으로 학습하여 인식하는 연구[9] 등이 있다. 하지만 위의 연구들 역시 특정 장비나 센서를 필요로 하거나, 낮은 인식률을 보이는 문제점을 지니고 있다.
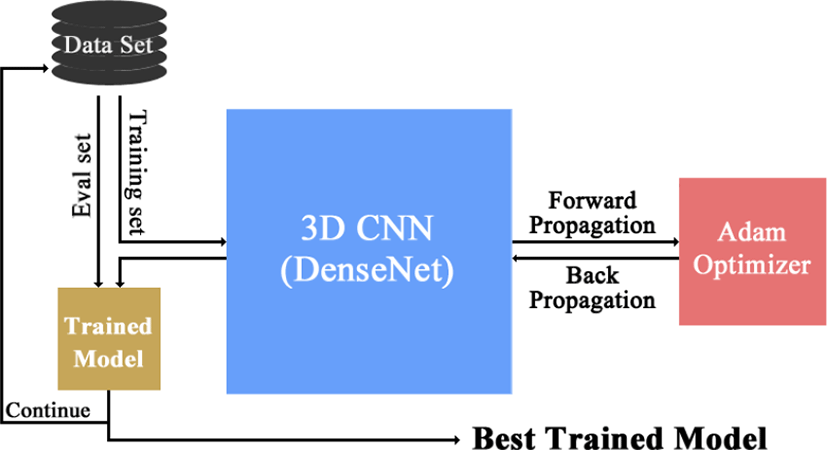
본 논문에서는 가상현실 기기에 부착한 RGB 형식의 카메라 이외 별도 센서 없이 딥러닝 기술인 합성곱 신경망을 통해 사용자의 손 제스처를 실시간으로 인식하는 3D 가상현실 게임을 소개한다. 먼저 사용자가 가상현실 게임의 사용자 인터페이스를 조작하고 마법을 구현하는 등의 명령을 수행하기 위한 제스처를 정의한다. 정의한 손 제스처 인식을 위한 합성곱 신경망은 압축 계층을 지닌 고밀도 연결 구조를 사용하여 신경망이 깊어질수록 정보를 손실하는 문제를 보완하고 적은 파라미터로 높은 속도와 인식률을 제공하는 DenseNet[10]을 3차원으로 확장하였다. 본 방법의 검증을 위하여 조명, 배경, 영상의 손 위치와 거리 등 다양한 상황을 고려하여 제작한 10가지 정적 및 동적 손 제스처 데이터 세트로 실험한 결과 평균 50ms의 속도로 94.2%의 인식률을 보여 가상현실 게임의 실시간 사용자 인터페이스로 사용 가능함을 알 수 있었다.
본 논문의 구성은 다음과 같다. 2장에서 본 연구에서 사용한 합성곱 신경망 구조를 소개하고 3장에 손 제스처 유형 및 데이터 세트 제작 방법과 손 제스처 인식 과정을 설명한다. 4장에서는 본 방법을 적용한 가상현실 게임을 소개하고 5장에서 실험결과를 기술한 후 6장에서 향후 연구 방향을 기술한 후 결론을 맺는다.
2. 합성곱 신경망
합성곱 신경망은 사람의 사고방식을 컴퓨터에게 가르치는 머신 러닝의 한 분야인 딥러닝 알고리즘 중 하나로 영상 인식과 음성 인식 모두에서 뛰어난 성능을 보인다. 합성곱 신경망은 기존의 완전 연결 신경망에 합성곱 연산과 최대 풀링을 추가하여 데이터의 공간 정보를 유지하면서 인접 데이터와의 특징을 효과적으로 추출한다.
최근에는 신경망의 구조가 더욱 복잡해지고 깊어짐에 따라서 성능의 향상보다 기존의 신경망 구조를 최적화하는 것에 초점을 맞추고 있다. 대표적인 예로 인셉션(Inception) 구조를 사용한 GoogLeNet[11]과 고밀도 연결 구조(Dense Connectivity)를 사용한 DenseNet은 파라미터 수를 획기적으로 감소시킴으로써 파라미터 저장을 위한 메모리 사용량을 감소시켰다.
DenseNet은 각 계층의 합성곱 연산 후의 출력을 그 이후의 모든 계층에 연결하는 고밀도 연결 구조를 사용해 신경망이 깊어질수록 초기 계층의 정보를 잃어버리는 문제를 해결하였다. 또한 단순한 행렬 덧셈으로 계층 사이를 연결했던 ResNet[12]의 합산(Summation) 방식 대신 이전 계층의 특징맵을 결합해 기존 정보를 유지하며 계층 사이를 연결하는 결합 (Concatenation) 방식을 제안하였다.
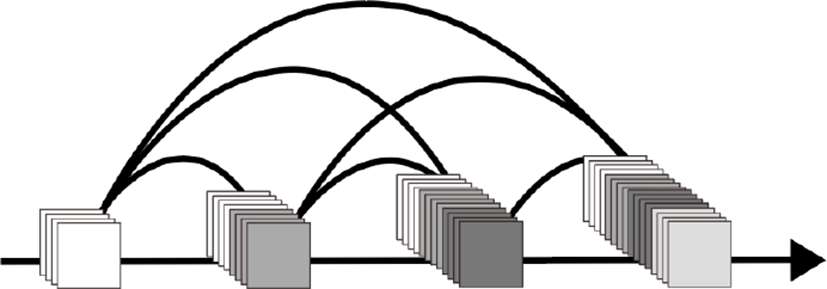
Figure 2와 같이 하나의 고밀도 연결의 수행되는 범위를 고밀도 구역(Dense Block)이라 하고 각 구역 사이의 이행 계층(Transition Layer)에서 평균 풀링을 수행하여 특징맵의 크기를 축소시킨다.
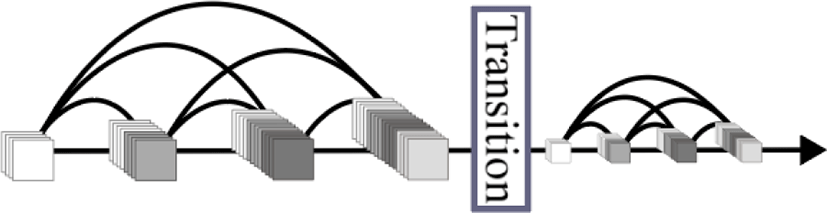
마지막으로 파라미터 수를 줄이기 위해 기존 모델에 비해 합성곱 계층에서 사용하는 커널의 깊이를 축소시키고 NIN(Network In Network)[13]의 1×1 합성곱 연산을 적용한 병목 계층(Bottleneck Layer)과 압축 계층(Compression Layer)을 추가하였다. 병목 계층은 고밀도 구역 내 합성곱 계층의 이전 단계에서 특징맵의 깊이를 조정하고, 압축 계층은 고밀도 구역의 끝에서 이행 계층으로 넘어가는 특징맵의 깊이를 조정하여 파라미터 크기를 줄인다.
손 제스처는 시작부터 끝까지 손의 모양과 위치가 변하지 않는 정적 제스처와 시간에 따라 위치가 변하는 동적 제스 처로 분류된다. 본 논문은 정적 제스처와 동적 제스처를 모두 분류하기 위하여 공간적인 특징만을 고려하는 기존의 DenseNet에 시간상의 정보를 고려할 수 있도록 Figure 3과 같은 차원을 확장한 구조의 3D DenseNet 구조를 제안한다.
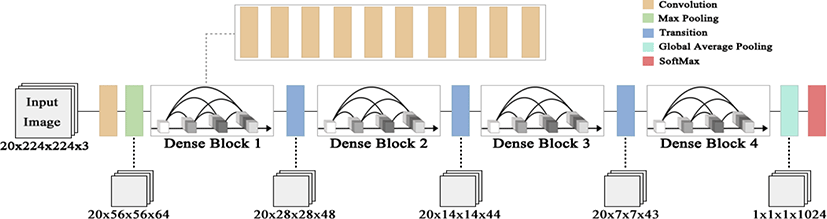
신경망은 4개의 고밀도 구역으로 구성되어 있고 각각의 고밀도 구역은 10개의 합성곱 계층을 가진다. 크기가 20×224×224인 데이터를 입력받아 첫 번째 합성곱 계층과 네 개의 이행 계층, 전역 평균 풀링을 거쳐 특징맵의 크기가 축소된다. 병목 계층과 압축 계층을 제외한 모든 합성곱 계층은 3×3×3 크기의 커널을 사용한다. 각 고밀도 구역에서 출력된 특징맵은 25%의 압축률을 가지는 압축 계층을 거쳐 이행 계층의 평균 풀링을 수행한다. 마지막 이행 계층 이후에는 파라미터 수를 줄이기 위하여 20×7×7 크기의 커널을 사용하는 전역 평균 풀링을 수행한다. 그리고 난후, 1024개의 뉴런을 가지는 은닉 계층을 거쳐 10개의 라벨로 이루어진 출력 층을 가지는 완전 연결 계층(Fully Connected Layer)을 수행한다.
3. 손 제스처 인식
손 제스처 인식 기술은 사람이 손을 이용하여 미리 정해진 동작을 했을 때, 그것이 어떤 동작인지를 인식하는 기술을 말한다. 본 장에서는 가상현실 게임을 위한 손 제스처를 정의하고 실험 데이터 세트 제작 방법과 학습과정을 설명한다.
가상현실에서 사용자와 객체 사이의 상호작용을 위한 손 제스처는 친숙하고 직관적이며 인식의 정확도가 높아야 한다. 이 점을 고려하여 Table 1과 같은 정적인 형태의 4가지 손 제스처 와 동적인 형태의 6가지 손 제스처 유형을 정의하였다.
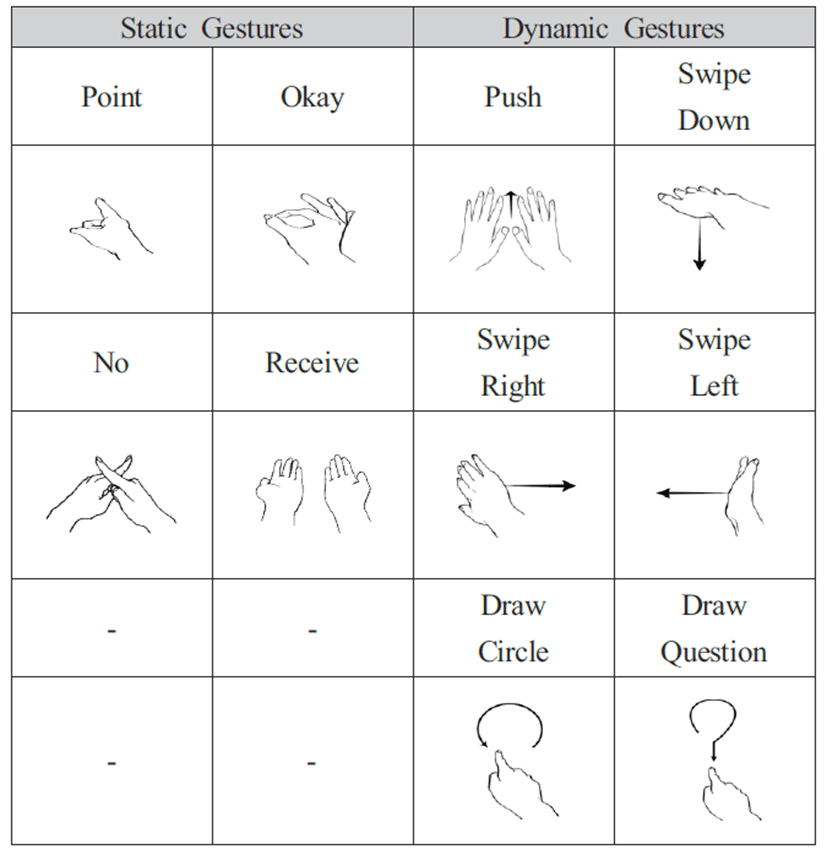
데이터 세트는 640x480 해상도의 카메라로 촬영되었고, 4명의 학습자가 참가하여 Table 1에서 정의한 손 제스처를 다양한 위치, 각도, 거리에서 시행하여 제작하였다. 초당 20프레임으로 구성된 손 제스처 영상은 1000세트 총 20,000장을 제작하였고, 과적합 문제를 개선하기 위해 제작된 손 제스처 영상의 손의 위치와 크기, 조명을 다양하게 후처리하여 5배 증가시켜 총 100,000장을 제작하였다. 총 100,000장 중 90%인 4,500세트는 학습데이터로, 나머지 10%인 500세트는 평가 데이터로 사용하였다.
4. 장치 및 게임 소개
본 논문은 마이크로소프트의 라이프캠 HD-3000을 사용하여 사용자가 실시간으로 취하는 손 제스처를 입력받고, HMD(Head Mounted Display)로 HTC와 Valve사에서 공동 출시한 Vive를 사용하여 가상현실 게임을 개발하였다(Figure 5). Vive는 적외선 센서인 베이스 스테이션을 통해 HMD를 추적하여 실제로 사용자가 이동한 거리나 방향을 인식한다.

본 논문은 Vive에서 제공하는 외부 컨트롤러를 사용하지 않고 라이프캠 HD-3000을 Vive와 연동하여 손 제스처를 통해 게임 내 모든 명령을 수행하는 가상현실 게임을 개발하였다.
본 논문은 손 제스처 인터페이스를 적용하여 생존게임 장르의 가상현실 게임을 개발하였다. Figure 6에서 보는 바와 같이 게임화면 내에 사용자가 취하는 손 제스처를 실시간으로 보여주어 조작을 좀 더 용이하도록 하였고, 사용자는 정의된 손 제스처를 취하여 마법, UI 조작 등의 게임 내 명령을 수행할 수 있다.

-
번개 (Lightning)
검지로 정면을 가리키는 정적 제스처를 취하면 사용자가 바라보는 방향으로 번개 마법이 발사된다.
-
확인 (Confirmation)
검지와 엄지를 둥글게 하여 O 모양을 그리는 정적 제스처를 취하면 확인 명령을 수행한다.
-
닫기 (Close)
양손의 검지를 서로 교차하여 X 모양을 그리는 정적 제스처를 취하면 열려있는 도움말, 마법 책 등의 UI를 닫는 명령을 수행한다.
-
마법 책 (Skill Book)
양 손바닥이 위를 바라보게 펴고 있는 정적 제스처를 취하면 마법들을 배울 수 있는 마법 책이 내려온다.
-
화염 구체 (Fireball)
양손으로 미는 동적 제스처를 취하면 사용자가 바라보는 방향으로 화염 구체 마법이 발사된다.
-
유성 (Meteor)
손바닥을 아래로 향하게 펴고 아래로 내리는 동적 제스처를 취하면 플레이어 전방에 유성들이 떨어진다.
-
이전/다음 (Previous/Next)
손바닥을 화면의 왼쪽에서 오른쪽으로 이동하는 동적 제스처를 취하면 마법 책이 이전 페이지로 넘어가고 화면의 오른쪽에서 왼쪽으로 이동하는 동적 제스처를 취하면 마법 책이 다음 페이지로 넘어간다.
-
얼음 구체 (Iceball)
검지로 원을 그리는 동적 제스처를 취하면 사용자가 바라보는 방향으로 얼음 구체 마법이 발사된다.
-
도움말 (Help)
검지로 물음표 모양을 그리는 동적 제스처를 취하면 도움말이 열린다.
Table 2와 Table 3은 게임 내에서 정의한 제스처를 실행한 화면이다.


5. 실험
본 실험은 프로세서 Intel Core i5 8400, 그래픽 카드 GeForce GTX 1080Ti, RAM 16GB 등으로 구성된 장비에 Python 3.5 기반의 Tensorflow 1.5.0으로 신경망을 구축하고 Unity 3D 2018.2.8.f1 엔진으로 가상현실 게임을 개발하여 실험을 진행하였다.
본 논문에서 제안한 3D DenseNet 구조의 학습 모델에 대한 성능 검증을 위하여 동일한 조건으로 GoogLeNet 구조의 학습 모델을 구축하여 비교 실험을 진행하였다. Table 4와 Figure 7은 두 학습 모델의 제스처 별 인식률을 나타낸 것이다.
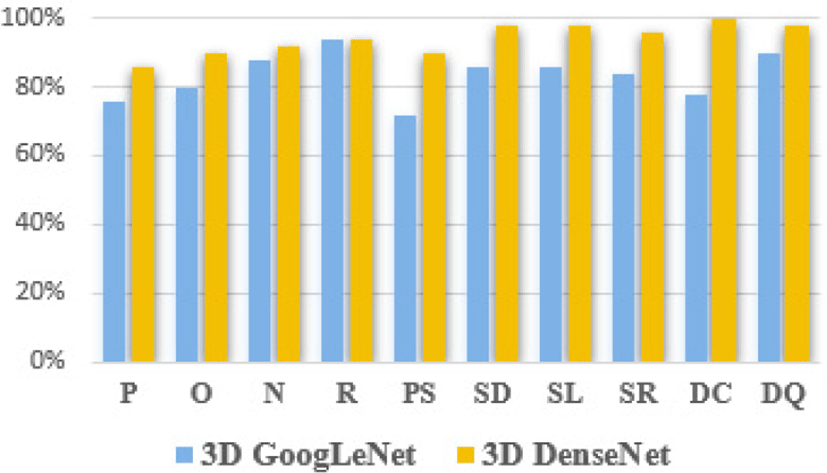
3D DenseNet 학습 모델은 3D GoogLeNet 학습 모델보다 전체적으로 우수한 인식률을 보였다. 두 학습 모델에 대하여 대부분의 인식률이 정적 제스처가 동적 제스처보다 떨어지는 것으로 보아 정적인 형태의 데이터를 입력받는 2차원 합성곱 신경망에 비해 3차원 합성곱 신경망은 동적인 형태의 데이터를 입력받아 손의 공간적인 특징보다 시간적 차원의 특징을 우선적으로 추출하는 것을 알 수 있었다.
Table 5와 Table 6은 두 학습 모델의 파라미터 수를 나타낸 것이다. 파라미터 수는 DenseNet 학습 모델이 GoogLeNet 학습 모델보다 6배 가까이 적은 것을 확인할 수 있다. 이를 통해 DenseNet 학습 모델이 메모리 측면에서도 우수함을 알 수 있다.
Table 7은 가상현실 게임 상에서 본 논문에서 제안한 3D DenseNet 학습모델과 3D GoogleNet 학습모델의 손 제스처 인식 처리시간을 비교한 것이다. 두 가지 방법 모두 실시간으로 손 제스처 인터페이스를 제공하는 것이 가능함을 알 수 있었다.
| Trained Model | Average Processing Time | Standard Deviation |
|---|---|---|
| 3D DenseNet | 50ms | 3ms |
| 3D GoogLeNet | 71ms | 5ms |
6. 결론
본 논문은 가상현실 기기에 부착한 RGB 형식의 카메라 이외 별도의 센서나 장비 없이 실시간으로 정적 손 제스처와 동적 손 제스처를 인식하기 위한 3D DenseNet 기반 신경망 구조를 제안한 후 가상현실 게임 상에서 실시간으로 손 제스처 인터페이스로 적용 가능함을 보였다.
가상현실 환경에서 손 제스처를 이용하여 몰입감 있고 자연스러운 인터페이스를 제공하려면 간단한 정적 및 동적 제스처 뿐만 아니라 스토리를 가지는 손 제스처의 인식이 필요하다. 향후 연구로 스토리 형식의 손 제스처 인식이 가능한 딥러닝 모델에 대한 연구를 수행하고자 한다.