





1. 서론
인공위성 기술의 지속적인 발전으로, 고품질의 위성 영상을 쉽게 얻을 수 있게 되었다. 특히 가시광선 영역의 위성영상은 많은 지리 정보를 표현할 수 있기 때문에 지질학, 기상, 농업 등 많은 분야에서 중요하게 활용되고 있다. 위성영상은 센서가 취득하는 전자기파의 파장 영역대에 따라 다른 특성을 가진다. 모든 가시광선 영역대를 감지하여 생성한 전정 영상 (panchromatic image, Figure 1a)은 공간해상도는 높지만 흑백의 단일 색상만을 가지고 있으며, 특정 파장 영역을 감지하여 생성한 다중분광 영상 (multi-spectral image, Figure 1b) 이나 적외선 영상 (infrared image, Figure 1c) 특정한 분광특성을 활용하기 용이하지만 공간해상도가 낮다.
이를 극복하기 위해, 고해상도 영상과 저해상도 영상의 장점들을 융합하여 고해상도의 컬러 영상이나 적외선 영상을 생성하는 영상 융합 기반의 해상도 향상 기법 들이 활발하게 연구되고 있다. 위성영상을 연구 하는 원격탐사 분야에서는 고해상도의 전정 영상을 이용 하여 저해상도의 다중분광 영상의 공간해상도를 높이는 기법을 pan-sharpening이라 부른다.

본 논문에서는 정합된 두 위성영상을 융합하기 위해 구조-텍스처 분할 (structure-texture decomposition) 기법을 이용하는 새로운 프레임워크를 제안한다. 기존의 영상 융합 기법은 multi-scale transform 기법이나 영상 도메인 변환을 거친 후에 입력 영상을 조합하고 역변환 (inverse transform)하여 융합영상을 생성하기 때문에 도메인 변환 및 역변환 과정에서의 픽셀 정보 손실이나 조합 정책 선택의 어려움이 있다. 본 논문이 제시하는 프레임워크 에서는 입력 영상의 도메인을 변환하지 않을 뿐 아니라, 구조-텍스처 영상 모델에 따라 단순 덧셈을 이용해 영상을 조합하기 때문에 기존 방법에서 발생하는 어려움을 극복할 수 있다.
구조-텍스처 분할 기법은 영상 (I)을 전반적인 형태를 표현하는 구조 영상 (S)과 작은 디테일들을 표현하는 텍스처 영상 (T)의 합으로 정의하는 구조-텍스처 영상 모델 (I = S + T)을 기반으로 한다 (Figure 2). 정합된 고해상도 영상과 저해상도 영상은 동일한 지역 및 구조물을 동일한 위치에서 촬영한 결과이기 때문에 고해상도 영상의 텍스처 영상과 저해상도 영상의 구조 영상 간에도 구조-텍스처 영상 모델을 적용시킬 수 있다. 이에 착안 하여 전정 영상의 고해상도 디테일을 저해상도 영상에 효과적으로 전달할 수 있는 영상 융합 프레임 워크를 고안하였다.

2. 기존 연구
위성영상 융합은 고해상도 영상의 디테일을 추출하기 위한 과정과 추출한 디테일을 저해상도 영상에 조합하는 과정에 의해 수행된다. 따라서 위성영상 융합 기술은 영상의 디테일을 추출하는 방법에 따라 크게 Component substitution (CS) 기법과 Multi-resolution analysis (MRA) 기법으로 분류된다.
CS 기법은 두 위성영상 데이터를 디테일을 표현하기 용이한 도메인으로 변환시킨 후, 저 해상도 영상으로부터 변환한 데이터의 디테일 영역을 고 해상도 영상의 변환 데이터로 치환하는 방식으로 융합 하는 기법이다. MRA 기법은 고해상도 영상을 다중 스케일 분해 기법으로 분해한 뒤 추출한 디테일을 저해상도 영상에 주입시켜 융합하는 기법이다.
CS 기법은 다중분광 영상의 컬러 데이터를 변환하는 방식에 따라 다양한 방향으로 연구되어 왔다. IHS (Intensity, Hue, Saturation) 기법 [1]은 다중분광 영상의 컬러 데이터를 명도, 색상, 채도로 변환하고, 명도 부분을 전정 영상 데이터로 치환하여 융합영상을 생성한다. 전정 영상의 데이터가 다중분광 영상의 명도와 완전히 일치하지 않기 때문에 분광정보가 손상되는 문제가 있다. 이를 극복하기 위해 다중분광 영상으로부터 적응적으로 명도 데이터를 생성하는 adaptive IHS 기법 [2]이 연구되었다. 또한 주성분 분석을 통해 데이터를 변환하여 융합하는 PCA 기법 [3]이나 Gram-Schmidt 과정을 통해 컬러 데이터를 정규 직교 basis로 변환하여 융합하는 Gram-Schmidt 기법 [4], 이를 보완한 adaptive Gram-Schmidt 기법 [5] 들이 연구되었다.
MRA기법은 영상을 분해하는 방법이 개발됨에 따라 다양한 기법들로 연구되어 왔다. 가장 널리 알려진 MRA 기법은 wavelet 변환을 이용하는 방법[6]이다. wavelet 변환은 서브 샘플링 시킨 원본 영상을 수평, 수직 방향의 성분들을 계산하기 때문에 작은 디테일을 추출하기에 용이하지만 경계의 방향에 따라 블록 현상이 나타나는 단점이 있다. 이를 극복하기 위해 에지 방향을 고려하여 영상을 분해하는 contourlet이나 curvelet을 이용한 MRA 기법 [7,8]들이 연구되었다.
최근에는 딥러닝과 같은 머신러닝 기법을 도입하여 위성 영상을 융합하는 기법들이 활발하게 연구되고 있다 [9,10].
입력 영상을 구조 영역과 텍스처 영역으로 분할하기 위해 영상의 에지를 보존하면서 스무딩하는 edge-preserving 필터를 활용할 수 있다. Bilateral filter [11]는 뚜렷한 에지 근처에서는 유사한 픽셀 값들만 값이 섞이게 하여 에지를 보존하는 필터이다. Guided filter [12]는 참조 영상의 에지가 입력 영상에 전달되도록 하는 필터로, 윈도우 내에서 선형 변환 연산하기 때문에 속도 측면에서 유리하다는 장점이 있다. Cho et al. [13]은 bilateral filter를 할 때 뚜렷한 에지 너머의 픽셀 값이 섞이지 않도록 윈도우의 위치를 조정하는 patch shift 기법을 고안하여 효과적으로 텍스처를 제거하는 bilateral texture filter를 제시하였다.
Li et al. [14]은 윈도우 내의 전체 변화량을 측정하는 windowed total variation과 변화량의 절대 값의 총량을 측정하는 windowed inherent variation을 조합하여 영상의 구조 영역과 텍스처 영역을 구분하는 Relative total variation (RTV) 기법를 고안하였다. Jeon et al. [15]은 RTV를 확장한 Directional RTV (dRTV)를 고안하여 영상의 스케일에 따라 윈도우의 크기를 적응적으로 변화시킬 수 있는 구조-텍스처 분리 기법을 제시하였다.
Lee et al. [16]은 윈도우 내에서 텍스처가 제거된 변화량을 측정할 수 있는 interval gradient operator를 고안하여 직관적이면서 병렬처리하기 용이한 구조-텍스처 분리 기법을 제시하였다.
3. 알고리즘
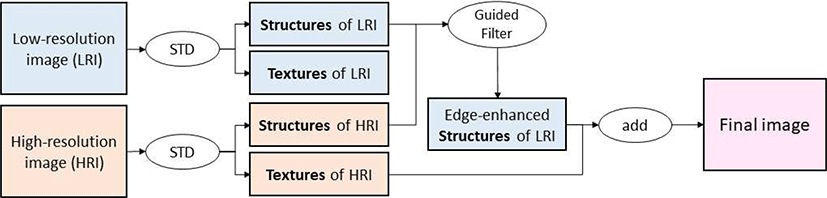
본 논문에서 제안하는 구조-텍스처 분할 기반 영상융합 프레임워크는 세 단계로 이루어진다. 첫 단계는 두 입력 영상을 각각 구조 영상과 텍스처 영상으로 분할하는 단계로, 자세한 내용은 3.1절에서 설명된다. 저해상도 영상의 구조 영상은 저품질의 구조 경계를 가지고 있기 때문에 이를 고해상도 영상의 텍스처 영상과 합치면 경계 부근에서 고해상도 영상의 품질이 유지되지 않는다. 이를 위해, 두 번째 단계에서 저해상도 영상의 구조 영역에 있는 에지의 품질을 높이기 위해 고해상도 영상의 구조 영역을 참조하여 guided filter가 수행된다. 두 번째 단계는 3.2절에서 자세히 설명된다. 세 번째 단계는 필터링 된 저해상도 영상의 구조 영상과 고해상도 영상의 텍스처 영상을 합쳐서 최종 영상을 생성하는 단계로, 3.3절에서 설명된다.
전체 알고리즘의 흐름을 Figure 3에서 확인할 수 있다. 두 입력 영상은 동일한 장소를 표현하도록 정합되었으며, 동일한 픽셀 사이즈로 조정되었다. 영상의 픽셀 사이즈를 조정할 때, 원본 데이터가 손실되지 않도록 nearest neighbor 방법을 이용하였다.
구조-텍스처 영상 모델에서 구조 영역은 영상의 전반적의 형태를 표현하기 때문에 부드럽게 변하거나 단일 색상인 무지(無地)영역과 급격하게 변하는 구조 경계로 구성된다. 이에 반해, 텍스처 영역은 영상의 디테일을 표현하기 때문에 작고 반복적인 진동 신호로 구성된다. 입력 영상은 구조 영역과 텍스처 영역이 합쳐진 형태로 표현되기 때문에 두 영역이 합쳐진 신호라는 것을 고려할 수 있는 방법이 필요하다. 본 논문에서는 이현준 등이 제안한 interval gradient[14]을 이용하여 구조 영상과 텍스처 영상으로 분할하였다. 3.1.1부터 3.1.3까지는 [16]에서 제안한 방법을 본 논문에서 적용한 내용을 간략하게 서술한다.
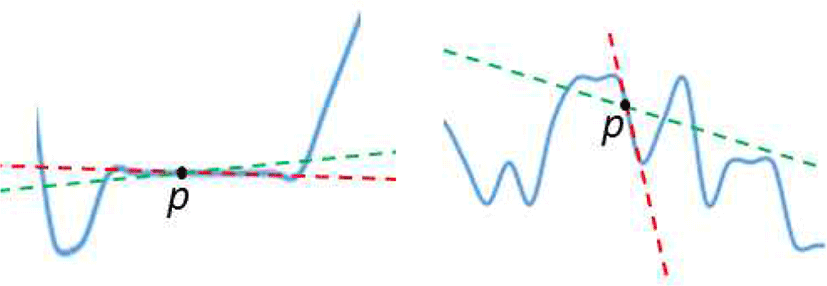
일반적인 gradient (∇I)p는 중심 픽셀 p와 인접한 픽셀의 세기 차이를 이용해 변화량을 측정한다. 이를 수식으로 나타내면 (∇I)p=Ip+1−Ip과 같다. 이와 달리 interval gradient (∇ΩI)p는 중심 픽셀 p 주변 영역의 픽셀들을 모두 고려하여 p 중심의 국소 영역의 평균적인 변화량을 측정한다. 이를 수식으로 표현하면 다음과 같다.
위 식에서 과 는 각각 p로부터 σ만큼 왼쪽에 인접한 영의 과 오른쪽에 인접한 영역 의 잘린 가우시안 평균 (clipped Gaussian average)을 연산한 결과로, 다음과 같이 표현된다.
p가 텍스처가 없는 영역에 위치하는 경우에는 순간 변화량과 평균 변화량이 유사하기 때문에 일반 gradient와 interval gradient의 연산 결과가 비슷하지만, p가 텍스처가 포함된 영역에 위치하는 경우에는 순간 변화량과 평균 변화량이 다르기 때문에 일반 gradient와 interval gradient의 연산 결과가 다르게 나타난다 (Figure 4).
일반 gradient와 interval gradient의 관계를 이용하면 텍스처가 제거된 gradient (∇′I)p를 다음과 같이 정의할 수 있다.
식 (4)를 이용하면 p가 텍스처가 없는 영역의 픽셀인 경우에는 (∇'I)p가 (∇I)p의 값을 따르며, p가 텍스처가 포함된 영역에 있는 경우에는 (∇'I)p가 (∇ΩI)p의 값을 따른다. εs는 분모가 0이 되는 것을 피하기 위한 작은 상수로, [16]에서 제시한 1.0×10-4의 값을 사용하였다.

영상의 gradient가 (∇'I)p를 따르도록 단순 누적시킨 값 Rp는 영상의 원래 정보가 크게 손실된다.
이를 해결하기 위해, 선형최적화를 이용하여 영상의 원래 정보를 유지하면서 (∇'I)p를 따르는 신호를 재구축한다.
ap과 bp은 Rp을 선형 변환하기 위한 계수이며, є은 ap가 너무 커지는 것을 막기 위한 상수 이다. 편미분을 이용 하여 식 (6)의 해를 구하면 다음과 같다.
μσ(x)는 x를 중심으로 σ의 범위 내에서 구한 산술 평균 함수이며, є은 분모를 0으로 만들지 않기 위한 상수이다. 본 논문에서는 σ = 3, є = 1.0× 10-5를 선택하였다. 최적화된 신호는 Sp=apRp+bp와 같이 구한다. 위의 최적화 과정은 1차원 신호를 기준으로 진행된 것으로, 이를 2차원 영상에 적용하기 위해 영상의 x축과 y축 방향으로 반복적인 최적화를 수행하였다.
최적화 결과로, 입력 영상의 텍스처가 제거된 구조 영상이 생성되며, 텍스처 영상은 원본 영상의 픽셀 값에서 구조 영상의 픽셀 값을 빼서 생성한다 (Figure 5).
고해상도 영상의 텍스처 영역은 디테일을 가지고 있고, 저해상도 영상의 구조 영상은 밴드 특성을 가지고 있지만 최종 영상에는 고해상도 구조 영상이 가진 고품질의 경계 정보 또한 포함되어야 한다. Figure 6a, 6b에서 두 영상의 구조 경계의 품질 차이를 확인할 수 있다.
저해상도 구조 영상의 경계를 샤프닝하기 위해 guided filter [12]를 사용하였다. Guided filter는 입력 영상의 경계를 샤프닝하기 위해 참조 영상의 경계 정보를 활용하는 필터로, 선형 최적화를 통해 비슷한 역할을 하는 joint bilateral 필터보다 빠른 연산을 보장한다는 특징이 있다. 필터링 결과, 고해상도 구조 영상의 고품질 경계 정보가 전달되는 것을 확인 할 수 있다 (Figure 6c).

4. 실험 결과
본 장에서는 제안한 프레임워크를 통해 생성된 융합 영상을 확인하고, 기존의 영상 융합 기법을 통해 생성된 영상과 정량적으로 비교·분석한다.
실험을 위해 입력 영상으로 Quickbird2, WorldView2, WorldView3 위성으로 촬영한 전정 영상과 다중분광 영상을 이용 하였다. 각 입력 영상의 사양은 Table 1에서 확인할 수 있으며, Figure 7에서 융합 결과를 확인할 수 있다.
| 영상 |

|

|

|
|
|---|---|---|---|---|
| 위성 | Quickbird2 | WorldView2 | WorldView3 | |
| 해상도 | 전정 | 61cm | 46cm | 31cm |
| 분광 | 244cm | 185cm | 124cm | |
| 영상 크기 | 526 x 491 | 500 x 500 | 500 x 500 | |

융합된 영상은 저해상도 영상의 분광 특성과 고해상도 영상의 공간해상도가 보존되어야 한다. 본 논문에서 제안한 방법과 기존 방법을 비교하기 위해 분광정확도와 공간정확도를 구분하여 비교·분석하였다. 비교하기 위한 기존 방법으로는 원격탐사 분야의 ArcGIS나 ENVI와 같은 상용 소프트웨어에서 널리 사용되는 IHS [1], PCA [3], Gram-Schdmit (GS) [4], Adaptive Gram-Schmidt (GSA) [5], wavelet [6] 방법을 선택하였다. 각 방법에 의한 결과 영상은 Figure 8에서 확인할 수 있다.
입력 저해상도 영상과 융합된 결과 영상의 분광정확도를 비교하기 위해, 융합된 영상을 저해상도 영상의 해상도로 다운 샘플링한 후, Gaussian blur를 적용하였다. 두 영상을 평가하는 지표로는 rooted mean square error (RMSE), 픽셀 값의 각 거리 (angular distance)를 측정하는 spectral angular mapping (SAM), 그리고 영상의 구조를 비교하는 Structural similarity (SSIM)을 사용하였다 [ 17, 18]. Table 2에서 비교 결과를 확인할 수 있다. 각 수치는 입력 영상으로 사용한 세 영상의 평균값이다. RMSE, SAM는 수치가 0에 가까울수록 정확도가 높은 지표이며 SSIM은 1에 가까울수록 정확도가 높은 지표이다. 본 논문에서 제시하는 방법이 분광정확도 측면에서 가장 좋은 수치를 보여주고 있다는 것을 확인할 수 있다.
공간정확도는 두 영상의 디테일이 비슷할수록 높은 수치를 가진다. 본 논문에서는 입력 고해상도 영상과 융합된 결과 영상의 공간정확도를 비교하기 위해, 두 영상의 그라디언트 영상을 이용하였다. x와 y방향의 그라디언트 영상을 생성한 뒤, 동일 방향의 영상 간의 평가 지표를 구하고 평균값을 계산하였다. Table 3에서 비교 결과를 확인할 수 있다. 공간정확도가 매우 우수하게 보존되는 IHS, GS 방법의 특징에도 불구하고 두 방법과 비교가능한 수준의 수치를 보여주고 있는 것을 확인할 수 있다.
본 논문에서는 구조-텍스처 분할 기법을 기반으로 동일 지역을 촬영한 고해성도 위성영상과 저해상도 위성영상을 융합하여 공간해상도를 개선하는 프레임워크를 제시 하였다. 기존 방법들은 고해상도의 영상의 공간해상도와 저해상도 영상의 분광 특성을 모두 보존하는데 어려움이 있는 반면, 제시하는 방법은 분광 특성이 구조 영역에, 높은 공간해상도의 디테일이 텍스처 영역에 있다는 것에 착안하여 고안되었기 때문에 두 입력 영상의 특징을 우수하게 보존한다. 실험 결과를 통해, 기존 방법대비 분광정확도와 공간정확도가 모두 높다는 것을 확인할 수 있었다. 하지만, 융합 결과가 구조-텍스처 분할 결과에 의존한다는 단점이 있다. 향후에는 고해상도 전정 영상과 저해상도 적외선 영상을 융합하는 방법을 연구할 계획이다. 전정 영상과 적외선 영상은 파장대가 다른 영역의 전자기파를 측정하였기 때문에 구조-텍스처 영상 모델을 그대로 적용하기 어렵다는 문제가 있다.

