





1. 서론
최근 4차 산업혁명 시대의 기반 기술인 자율비행에 관한 연구가 활발히 이뤄지고 있다[1]. 그러나 기존 연구는 비교적 단가가 높은 LiDAR 센서를 기반으로 하므로 자율비행 기술이 널리 보급되기 위해서는 단가가 낮은 센서를 적용하는 자율비행에 관한 연구가 필요하다[2].
자율주행 및 자율비행에서 LiDAR 센서의 대체재로 가장 적합한 것은 카메라 기반의 객체 인식이다(Figure 1). 과거의 카메라 기반 자율비행은 카메라 영상의 해상도가 낮고, 부족한 도로 데이터를 기반으로 학습을 수행하므로 정확도가 떨어지는 단점이 있었다. 그러나 최근 자율주행 기술이 상용화되면서 많은 도로 데이터가 확보되었고, 카메라 영상의 해상도가 커지고 무게도 경량화됨에 따라 상대적으로 단가가 낮은 카메라를 이용한 자율주행 및 자율비행이 가능해지고 있다[3].
이에 따라 자율주행의 연구방향은 LiDAR 기반에서 카메라 기반으로 변화되고 있으며, 자율비행의 경우는 LiDAR를 기반으로 하는 연구가 다수를 이루고, 카메라를 기반으로 자율비행을 실현하고자 하는 연구가 시도되고 있는 단계이다[4]. 최근 자율주행 자동차의 상용화에 따라 카메라를 이용한 자율주행에 관한 다양한 연구결과가 공개되었지만, 아직 상용화가 미비하고 자율주행에 비해 한 개의 공간 축을 추가로 고려해야 하는 자율비행에 대해서는 아직까지 카메라를 사용한 연구가 많이 부족한 실정이다[5]. 관련 연구로 교통 규칙을 준수하는 자동차와 자전거의 주행 데이터로 훈련을 수행하여 충돌 가능성과 조향 각도를 동시에 예측하는 DroNet이라는 합성곱 신경망 네트워크를 제안하였으나, 위험 상황에서 행동하는 방법을 학습하기 위해서 전문 비행 조종사가 회피하는 충돌궤적을 별도로 제공하여야 하는 단점이 있다[6]. LiDAR 방식과 비교하여 카메라를 이용하면 색이나 글자 등 다양한 시각 정보를 처리할 수 있으므로 확장성 측면에서 카메라에 대한 연구가 필요하다.
자율비행 기술 중 장애물 회피는 매우 중요한 기술이다. 기존 연구는 초음파 또는 LiDAR 센서 등을 활용하여 장애물을 회피하는 기술을 연구하고 있다[7][8]. 하지만 초음파 센서는 거리가 조금만 멀어져도 대기 중에서 크게 감쇠하기 때문에 주로 단거리에서 쓰이며 LiDAR에 비해 정확도가 떨어지는 단점이 있다[9]. LiDAR는 초음파 센서에 비해 비교적 높은 정확도를 보이며 최근 연구에서 많이 활용되고 있지만, 단가가 높고 색이나 글자 등 다양한 시각정보 처리 능력이 제한적인 단점이 있다. 따라서 본 논문은 비교적 단가가 낮고 시각 정보를 이용한 확장성이 높은 카메라를 기반으로 YOLOv4Tiny를 통한 객체검출을 수행하고, Unity ML Agent를 활용하여 주어진 상황에서 최적의 행동을 선택하는 머신러닝을 수행하여 드론 비행시 발생하는 장애물에 대한 회피 알고리즘을 제안한다. 그리고 기존의 LiDAR 기반 장애물 회피 알고리즘과 성능을 비교해 보고자 한다(Figure 2).
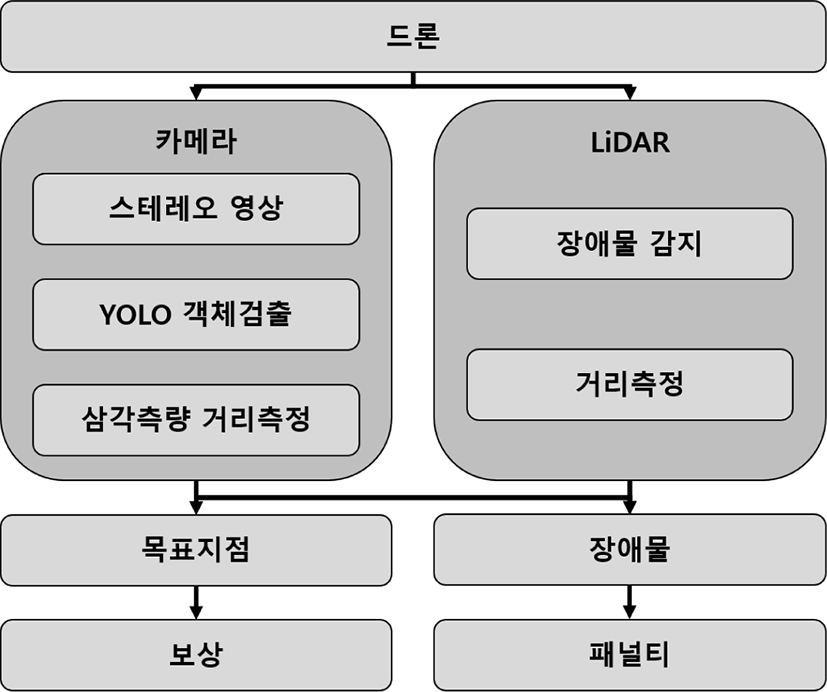
카메라 기반 장애물 회피 알고리즘은 3차원 공간상의 학습환경에서 드론, 장애물, 목표지점 등을 무작위로 위치시키고, 가상 카메라를 이용하여 전면 스테레오 카메라를 통해 스테레오 영상정보 데이터를 얻어 YOLOv4Tiny 객체 검출을 수행한다. 그리고 난 후 스테레오 카메라의 삼각측량법을 통해 검출된 객체와의 거리를 측정한다. 이 거리를 기반으로 장애물 유무를 판단하고, 만약 장애물이면 패널티를 책정하고 목표지점이면 보상을 부여한다.
본 논문에서 제시하는 알고리즘의 성능을 비교하기 위하여 LiDAR 기반 장애물 회피 자율비행 강화학습 방식을 설계하였다. LiDAR(Light Detection and Ranging)는 빛 감지 및 거리 측정의 줄임말로, 감지 센서를 통해 특정 물체의 거리를 측정하는 기법이다[10]. 전파를 사용하는 RADAR와 비슷하지만 LiDAR는 전파 대신 레이저와 같은 빛으로 물체를 감지한다는 점이 다르다. LiDAR 시스템은 빛을 목표 물체로 발사하여 반사되는 빛을 광원 주위의 센서로 검출한다. 빛이 되돌아오기까지 걸린 시간(ToF, Time of Flight)을 측정하고, 빛의 속도(c)는 언제나 항상 일정하다는 성질을 이용하여, 목표물까지의 거리(D)를 높은 정확도로 계산한다(Figure 3). LiDAR는 자율주행 자동차 외에도 3D 항공지도, 지리지도, 공장 안전 시스템, 스마트 무기, 가스 분석 등에 사용된다[9].
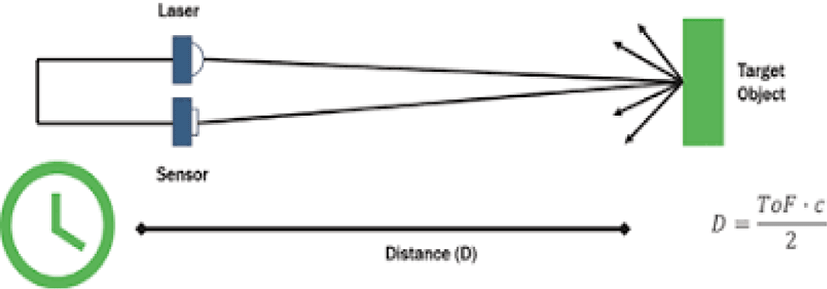
LiDAR 기반 장애물 회피 알고리즘도 마찬가지 방법으로 3차원 공간상의 학습환경에 드론, 장애물, 목표지점을 무작위로 위치시키고, Unity의 Raycast를 이용하여 드론을 기준으로 상, 하, 좌, 우, 전과 10도 각도로 벌어진 전면 상, 하, 좌, 우 9개 방향으로 객체를 감지한다. 감지한 객체정보를 바탕으로 LiDAR 거리측정 방법(Figure 3)으로 거리를 측정한 후 이를 기반으로 보상이나 패널티를 준다.
본 논문에서 제시하는 카메라 기반 장애물 회피 알고리즘과 LiDAR 기반 장애물 회피 알고리즘은 Unity ML Agent를 이용하여 머신러닝을 진행한다. 드론 비행을 하면서 검출된 객체가 목표지점인지 장애물인지를 판별한 다음, 드론으로부터 목표지점까지의 거리에 따른 보상을 지속적으로 부여하고, 드론이 목표지점에 도착할 정도로 짧은 거리가 측정되면 해당 에피소드를 종료하고 보상을 부여한다. 만약, 검출된 객체가 장애물이면 거리에 따른 패널티를 부여하고, 드론과 충돌할 수 있는 짧은 거리가 측정되면 해당 에피소드를 종료하고 패널티를 부여한다. 에피소드가 종료되면 해당 에피소드에서 획득한 보상과 패널티를 합산하여 더 나은 보상을 받을 수 있는 다음 행동을 선택하게 된다.
본 방법을 다양한 환경에서 구현한 결과 카메라 기반 장애물 회피 알고리즘은 평균 정확도 87.60%, 평균 목표지점 도달시간 28.93s, LiDAR 기반 장애물 회피 알고리즘은 평균 정확도 87.20%, 평균 목표지점 도달시간 24.15s로 LiDAR 기반 장애물 회피 알고리즘과 비교하여 카메라 기반 장애물 회피 알고리즘도 비슷한 수준의 높은 정확도와 평균 목표지점 도달시간을 보여 활용도가 높음을 알 수 있었다.
본 논문의 구성은 다음과 같다. 2장에서 본 논문에서 제안하는 카메라 기반 강화학습을 이용한 자율비행 드론의 장애물 회피 알고리즘을 소개한다. 3장에서 다양한 환경에서 본 방법의 성능을 실험한 결과를 보인 후, 4장에서 결론을 맺는다.
2. 카메라 기반 강화학습을 이용한 드론 장애물 회피 알고리즘
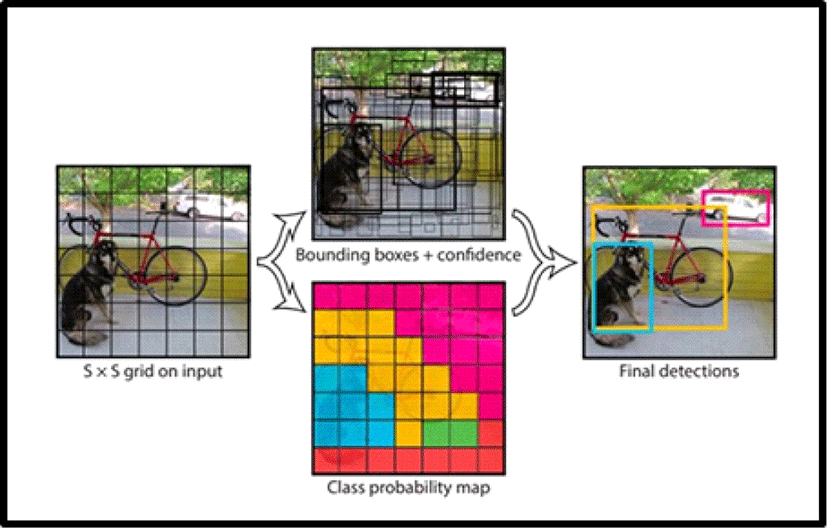
본 논문은 자율 비행시 객체를 탐지하기 위한 모델로 YOLO를 사용한다. YOLO(You Only Look Once)는 객체 검출을 한 번만 보고 알아낼 수 있다는 의미에서 만들어진 것으로, 실시간 객체 인식(Real-time Object Detection System)에 매우 좋은 성능을 보인다. 단일 프레임 내에서 복수의 객체를 인식할 수 있으며 입력 이미지를 S x S grid로 나누어 각 그리드 셀(Grid Cell) 중앙에 객체가 있는지 예측하는 아이디어를 기반으로 구현되었다(Figure 4). 전체 이미지에 대해 단일 신경망을 적용하여 인식 속도가 빠르다는 장점이 있다[11].
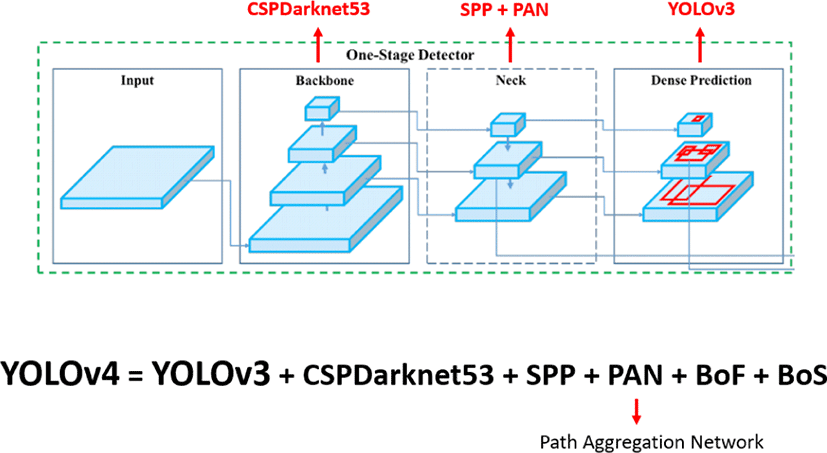
YOLOv4는 YOLO의 개선된 4번째 버전으로 YOLOv3 head를 기반으로 정확도 손실을 최소화하면서 속도의 측면에서 이득을 취하기 위해 CSPNet 기반의 CSPDarkNet53을 백본(Backbone)으로 사용하고, 검출 성능을 높이기 위해 SPP(Spatial Pyramid Pooling)와 PAN(Path Aggregation Network)을 Neck에 적용하였으며, 정확도를 높이기 위해 BoF(Bag of Freebies)와 BoS(Bag of Specials)를 적용한 구조이다(Figure 5)[12].
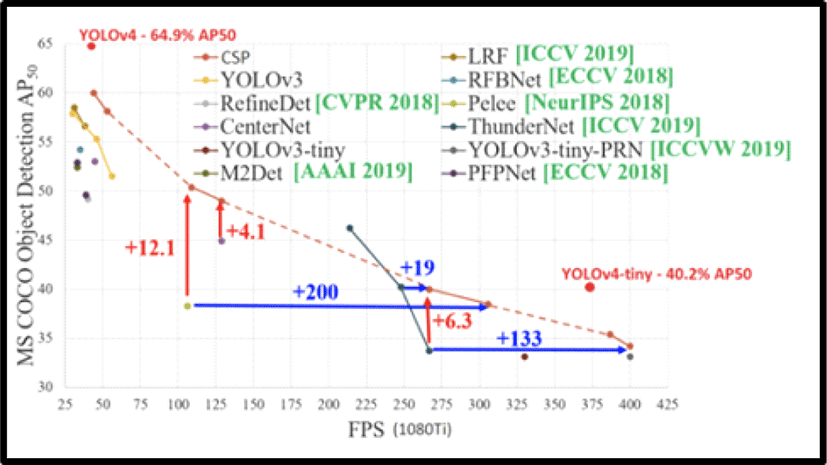
YOLOv4Tiny는 YOLOv4의 압축 버전으로 CSP 백본의 컨볼루션 계층(Convolutional Layer)의 수가 29개의 학습된 컨볼루션 계층(Pretrained Convolutional Layer)으로 압축되었고 YOLO 계층의 수가 기존의 3개에서 2개로 줄어들었다. 즉, 구조를 간단히 하고 파라미터를 감소시킨 네트워크로 기존의 YOLOv4와 비교하여 RTX1080Ti 환경에서 YOLOv4는 64.9% AP, 약 48 FPS, YOLOv4Tiny는 40.2% AP, 약 374 FPS로 YOLOv4Tiny가 AP는 다소 낮지만 대신 FPS가 높다는 장점이 있어 모바일이나 임베디드 기기에 적합하다(Figure 6).
양안식 스테레오 비전 시스템은 삼각측량을 기반으로 양안식 측정 방법을 통해 목표 물체의 3차원 정보를 얻을 수 있다[13].
Figure 7에 대하여 P는 목표지점, OL과 OR은 동일한 초점거리 카메라의 시축 센터(Visual Center), PL과 PR은 각각 목표물을 바라보는 투시점, xL과 xR은 카메라 이미지의 PL과 PR에 대응하는 왼쪽과 오른쪽의 수평 좌표계이다.
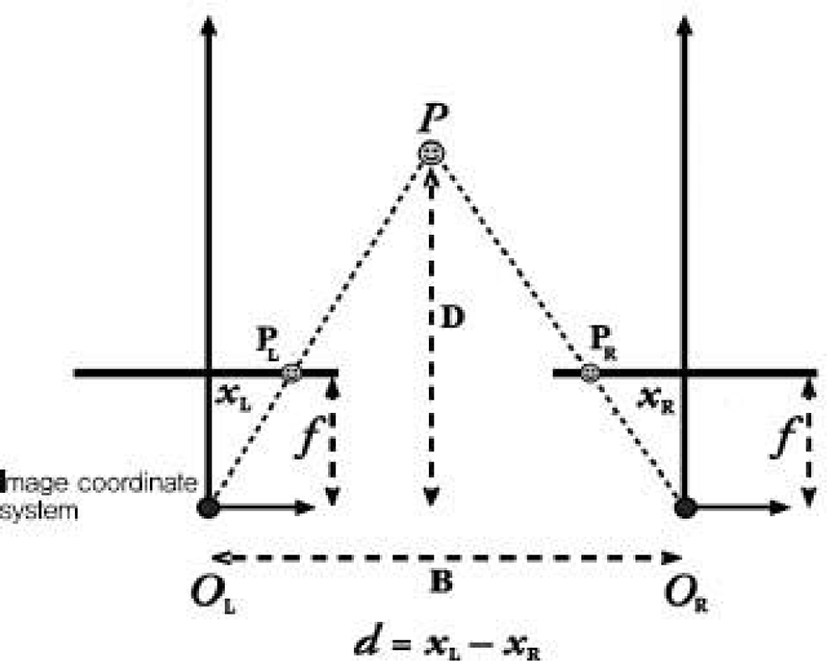
양안식 스테레오 비전 측정 방법[14][15]에 따라 OL, OR, PL, PR은 각각 이미지의 좌표를 의미하며, B는 두 카메라의 이격거리, f는 카메라의 초점거리, xL-xR은 disparity(d)로 정의된 시차오차, D는 카메라와 목표물(P)까지의 거리로 명시했을때 다음의 두 식으로 정리된다(식 (1)과 (2)). 식 (1)은 D와 B의 비율은 f와 xL-xR의 비율과 같으므로 이것을 D에 대해 정리한 식이다. 마찬가지로 식 (2)는 D와 W의 비율은 f와 w의 비율과 같으므로 이것을 f에 대해 정리한 식이다. 이때, w는 CCD(Charge-Coupled Device)에 의한 목표물 이미지의 폭(mm), W는 CCD에 의하여 표시될 수 있는 목표물의 크기를 의미한다.
Figure 8은 본 논문에서 제시하는 카메라 기반 장애물 회피를 위한 드론 자율비행 강화학습 알고리즘을 도식화한 것이다. 먼저 Unity ML Agent의 Communicator로부터 x, y, z축 각각에 대하여 어떤 방향으로 이동하는 행동을 수행할지에 대한 정보를 전달받는다. 전달받은 정보를 통해 수행할 행동이 결정되면 행동을 수행하고, 드론에 설치된 스테레오 카메라로부터 스테레오 영상정보를 얻는다. 얻은 영상정보를 YOLOv4Tiny를 통해 목표지점인지 장애물인지를 판단하고 거리측정에 따른 보상이나 패널티를 부여한다. 받은 보상이나 패널티 정보는 다시 Unity ML Agent의 Communicator로 전달되고 다음 수행할 행동을 결정한다.
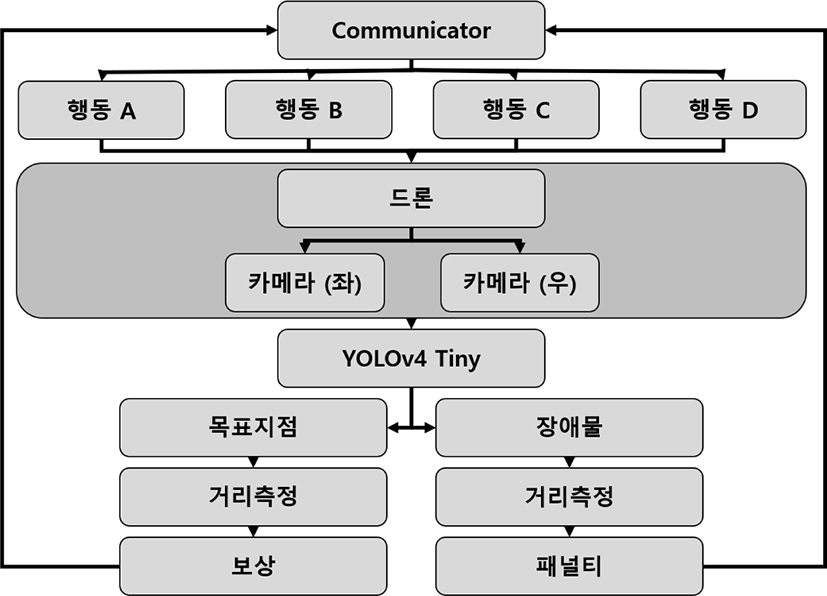
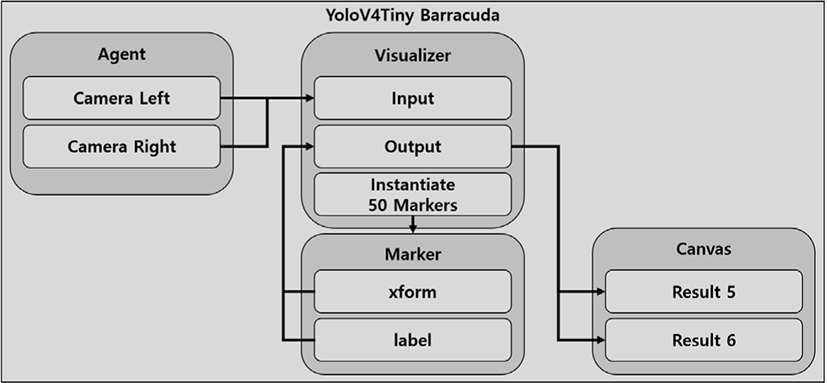
Figure 9는 YOLOv4Tiny 기반 객체 검출 흐름도를 나타낸다. 스테레오 카메라를 통해 획득한 각 스테레오 영상에 대해 YOLOv4Tiny를 사용하여 검출된 객체에 대한 정보를 추출한다. 그림의 label 정보를 통해 검출된 객체의 신뢰도를 확인하고 검출된 객체가 목표지점인지 장애물인지 확인한다. 또한 검출된 객체가 표시될 박스의 네 꼭지점의 x, y 좌표를 포함하는 xform을 통해 객체의 위치정보를 얻는다.
그다음 순서로, 카메라의 기하학적 해석에 기반한 삼각측량법(식 (1))을 사용하여 드론과 검출된 객체 간의 거리(Triangulation Distance)를 측정한다. 식 (3)은 본 논문에서 사용한 삼각측량 거리측정을 통한 강화학습 상태 정보 관측값의 계산식이다. 삼각측량을 통해 측정한 거리값을 사전에 미리 정의한 측정 가능한 최대거리(Limit Distance)로 나누어 0 ~ 1로 정규화시킨다. 즉, 측정한 거리가 가까울수록 0에 가까워지며, 거리가 멀수록 1에 가까워진다. 검출된 객체가 없어 측정할 거리가 없을 경우 –1을 반환한다.
Figure 10은 본 논문에서 제시하는 LiDAR 기반 장애물 회피 드론 자율비행 강화학습 알고리즘을 도식화한 것으로 카메라 기반 장애물 회피 알고리즘과 비슷한 방식으로 수행된다. 단지, 객체를 검출하고 검출된 객체까지의 거리를 측정할 때 카메라 대신 LiDAR 센서를 사용한다는 점에서 차이가 발생하며 빛을 이용해 거리를 측정하기 때문에 별도의 검출된 객체의 위치정보가 사용되지 않는다.
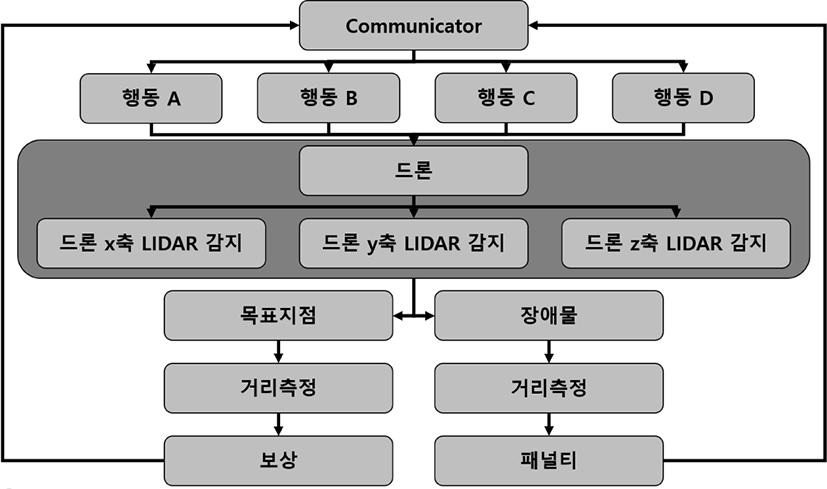
드론의 x, y, z축을 기준으로 미리 정의된 측정 가능한 최대거리(Limit Distance) 범위 내에서 물체를 탐지한다. 식 (4)는 본 논문에서 사용한 LiDAR 기반 거리 측정을 통한 강화학습 상태 정보 관측값의 계산식이다. 식 (3)과 동일한 방식으로 처리되고 단지 LiDAR를 통해 거리를 측정한다는 차이점이 있다.
3. 실험
본 실험은 프로세서 Intel Core i5-6600, 그래픽카드 NVIDIA GeForce GTX 1060 6GB, RAM 16GB으로 구성된 PC 장비와 C# Script 기반의 Unity ML Agent를 개발도구로 사용한 환경에서 진행되었다.
기존의 머신러닝은 많은 양의 코드 작성을 필요로 하고, 고도로 전문화된 툴을 사용해야 하는 반면, Unity사에서 제공하는 머신러닝 패키지인 Unity ML Agent[16]는 지능형 에이전트를 통해 심층적인 강화학습을 보다 편리하게 적용할 수 있도록 한다. 본 논문은 Unity ML Agent의 PPO 기반 강화학습을 적용하였다. PPO 기반 강화학습은 상태가 주어졌을 때 행동을 결정하고 상태의 가치를 평가하는 Actor-Critic 방식의 학습에 대해 매 Iteration 마다 N개의 Actor가, T개의 timestep 만큼의 데이터를 모아 학습하는 방식을 가진다[17]. 즉, NT개의 데이터를 통해 대리손실함수(Surrogate Loss)를 형성하고 확률적 경사 하강법(Mini-Batch SGD)을 적용해 학습하는 일련의 과정을 K Epoch에 걸쳐 반복 수행한다. 본 논문은 Unity ML Agent에서 제공하는 다중 Agent를 통한 PPO 기반 분산 강화학습을 수행하여 학습시간을 효과적으로 단축시켰다.
학습에 사용된 상태 정보 데이터는 Table 1과 2와 같다. Table 1은 카메라 기반 장애물 회피 강화학습에 사용되는 상태 정보이고, Table 2는 LiDAR 기반 장애물 회피 강화학습에 사용되는 상태 정보이다.
| Observe Status | Params | Description |
|---|---|---|
| Agent Positioin | 3 | 드론의 위치정보 |
| Agent Velocity | 3 | 드론의 속도정보 |
| Agent Angular Velocity | 3 | 드론의 각속도 정보 |
| Target Position | 3 | 목표지점의 위치정보 |
| Camera Observation | 50 | 카메라 탐지물체 거리정보 |
| Observe Status | Params | Description |
|---|---|---|
| Agent Positioin | 3 | 드론의 위치정보 |
| Agent Velocity | 3 | 드론의 속도정보 |
| Agent Angular Velocity | 3 | 드론의 각속도 정보 |
| Target Position | 3 | 목표지점의 위치정보 |
| Ray Observation | 9 | LiDAR 탐지물체 거리정보 |
본 논문은 학습하는 과정에서 장애물 충돌과 같은 다양한 상황으로 발생할 수 있는 드론의 손상을 방지하고 시간적/공간적 제약에 자유로운 비행 시뮬레이션 환경을 구축하여 실험을 수행하였다. 실험을 위해 구축한 환경은 사물 형태의 장애물 244개를 골고루 배치한 1km 길이의 일자형 트랙 형태의 환경에 대해 3,500,000 step을 학습하였다. 그리고 실제 속도를 고려해 드론의 최대속도는 50m/s로 제한하였다.
본 논문의 성능 검증을 위해 위에서 구축한 환경에 대하여 카메라 기반 장애물 회피 자율비행 강화학습과 LiDAR 기반 장애물 회피 자율비행 강화학습의 시뮬레이션을 수행하였다.
Table 3은 구축한 환경에 대한 카메라 기반 장애물 회피 알고리즘의 정확도와 목표지점 도달시간을 나타낸다. 5회 각 100번씩 수행한 결과 평균 87.60%의 정확도와 약 28.93s의 목표지점 도달시간이 걸린 것을 확인할 수 있었다.
| Test | Simulation | Accuracy | Time |
|---|---|---|---|
| Test 1 |

|
90.00% | 28.93s |
| Test 2 |
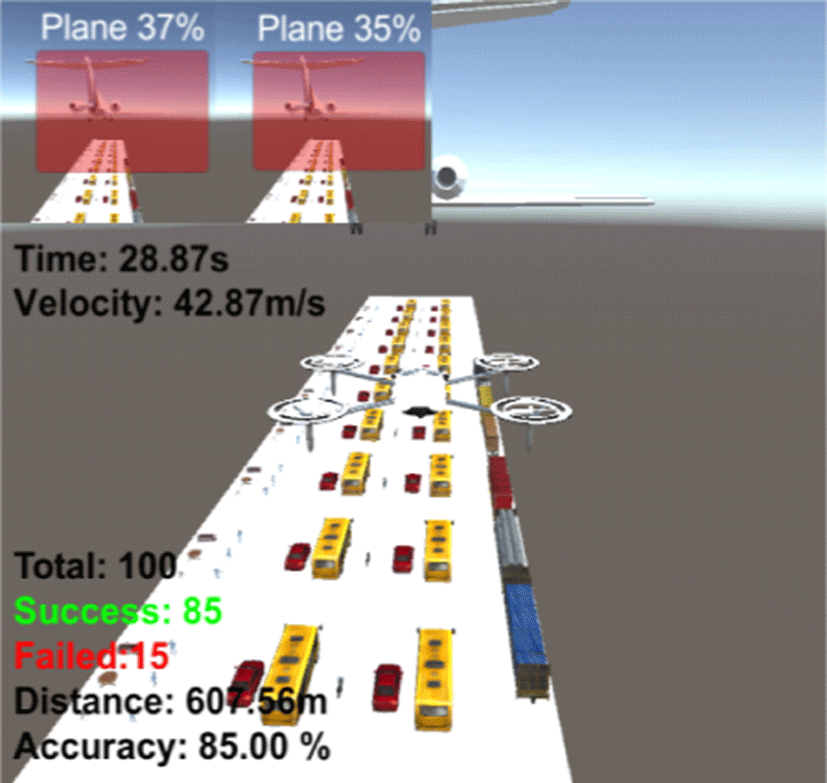
|
85.00% | 28.87s |
| Test 3 |
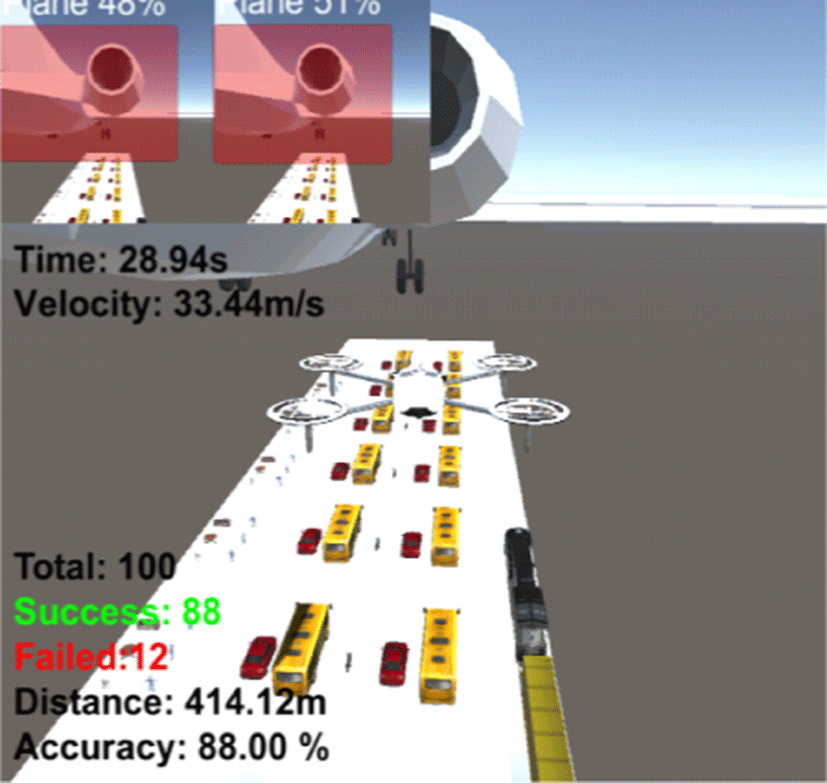
|
88.00% | 28.94s |
| Test 4 |
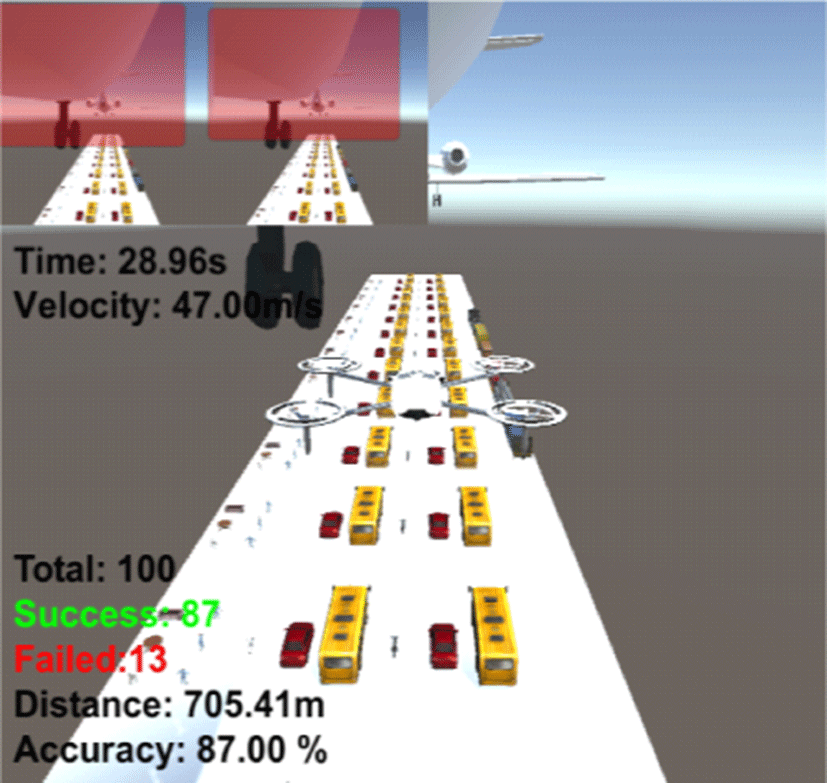
|
87.00% | 28.96s |
| Test 5 |
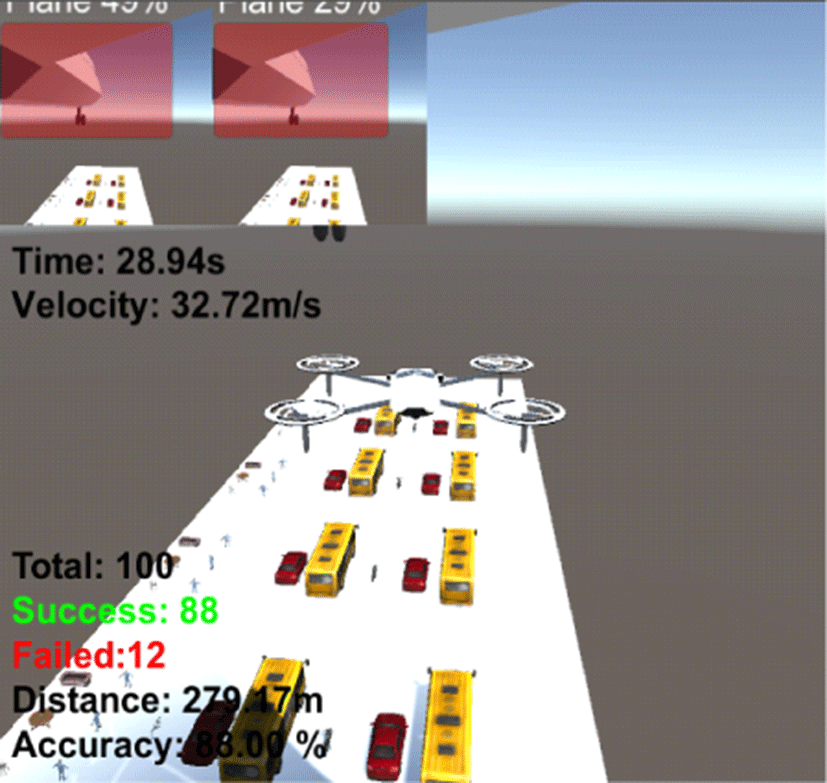
|
88.00% | 28.94s |
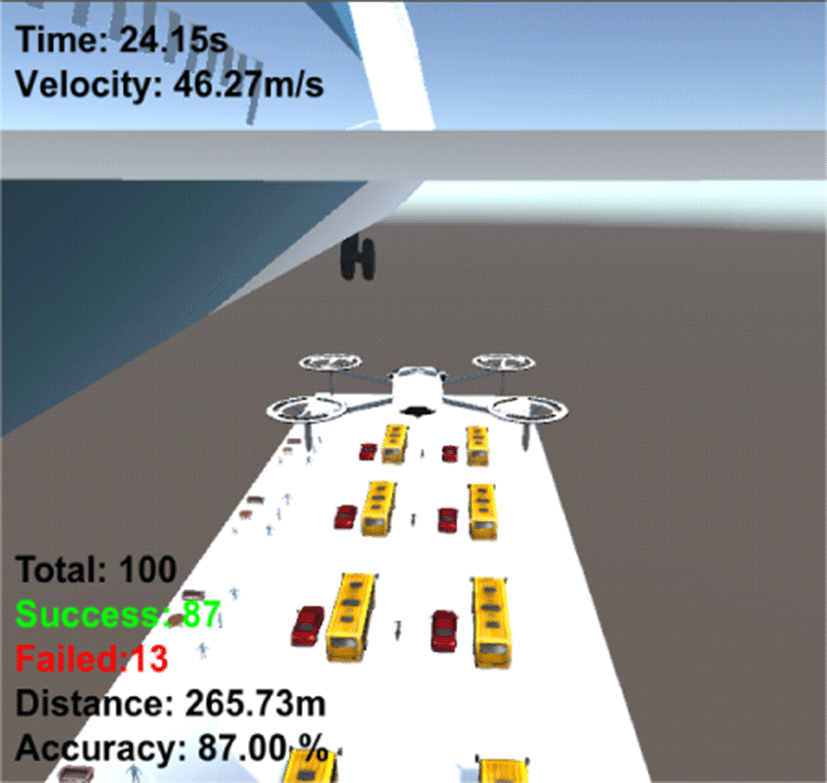
Table 4는 구축한 환경에 대한 LiDAR 기반 장애물 회피 알고리즘의 정확도와 목표지점 도달시간을 나타낸다. 5회 각 100번씩 수행한 결과 평균 87.20%의 정확도와 약 24.15s의 목표지점 도달시간이 걸린 것을 확인할 수 있다.
| Test | Simulation | Accuracy | Time |
|---|---|---|---|
| Test 1 |

|
87.00% | 24.15s |
| Test 2 |

|
86.00% | 24.17s |
| Test 3 |
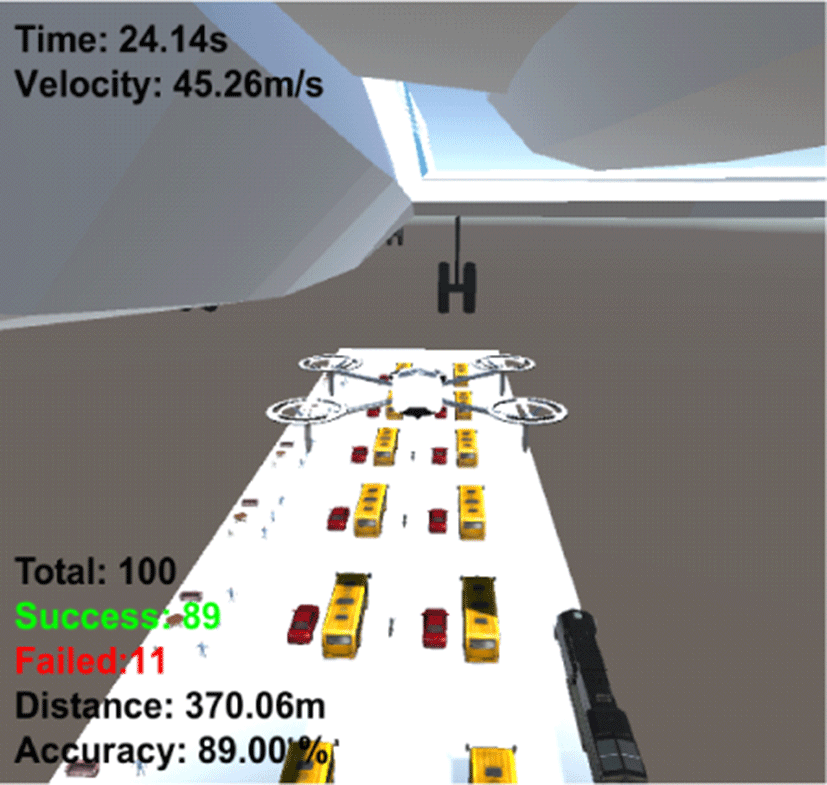
|
89.00% | 24.14s |
| Test 4 |
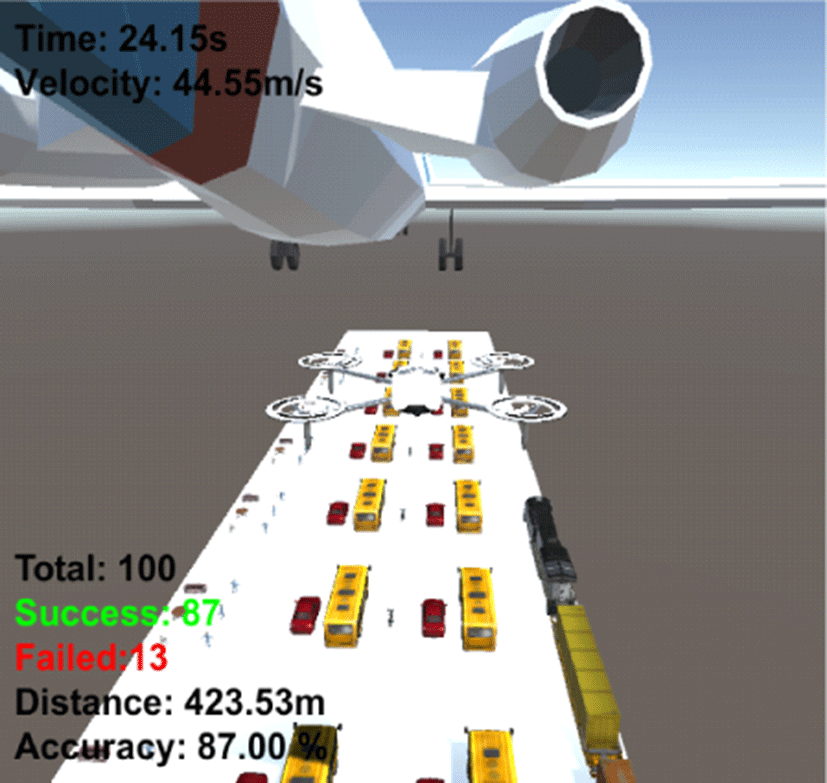
|
87.00% | 24.15s |
| Test 5 |
|
87.00% | 24.15s |
두 가지 알고리즘을 비교한 결과 카메라 기반 장애물 회피 자율비행 시뮬레이션이 LiDAR 기반 장애물 회피 자율비행 시뮬레이션보다 평균 0.40% 더 높은 정확도를 보였고, LiDAR 기반 장애물 회피 자율비행 시뮬레이션이 카메라 기반 장애물 회피 자율비행 시뮬레이션보다 평균 4.78s 더 빠른 목표지점 도달 시간을 보였다(Table 5).
| Classification | Camera | LiDAR |
|---|---|---|
| Avg Acc | 87.60% | 87.20% |
| Avg Time | 28.93s | 24.15s |
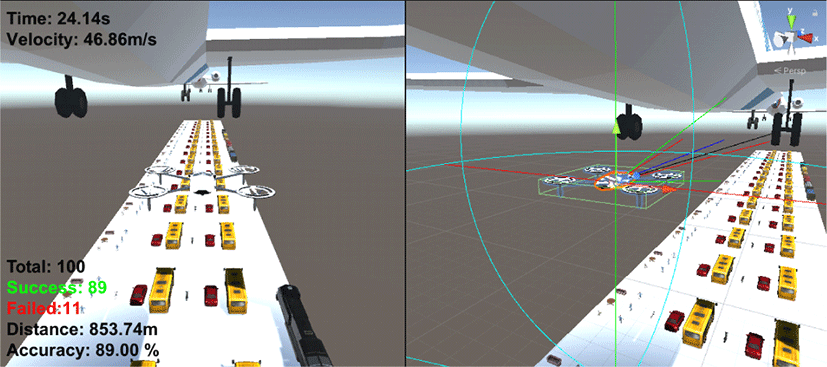
Figure 11과 12는 각각 카메라 기반과 LiDAR 기반 비행 시뮬레이션의 실행화면으로 학습된 가중치를 가지고 테스트 환경에서 실행한 화면을 캡처한 것이다. 테스트 환경에서 두 방식 모두 장애물을 회피해 목표지점을 잘 찾아가는 것을 확인할 수 있다.

4. 결론
본 논문은 단가가 상대적으로 저렴하고 시각 정보를 이용한 확장성이 높은 카메라 기반의 PPO 강화학습을 이용한 드론의 장애물 회피 알고리즘을 제안한다. YOLOv4Tiny를 활용한 객체검출을 통해 장애물을 검출하고 스테레오 카메라의 기하학적 해석에 따른 삼각측량 거리측정에 따라 장애물을 회피하는 분산강화학습을 통해 자율비행을 구현하는 방법을 제시한다. 실험결과 카메라 기반 장애물 회피 알고리즘은 평균 정확도 87.60%, 평균 목표지점 도달시간 28.93s를 보였고, LiDAR 기반 장애물 회피 알고리즘은 평균 정확도 87.20%, 평균 목표지점 도달시간 24.15s을 보여 카메라 기반 장애물 회피 알고리즘도 높은 정확도와 평균 목표지점 도달시간을 보임을 알 수 있었다. 위의 결과를 바탕으로 장애물 회피 자율비행 강화학습에서 단가가 높은 LiDAR 센서 대신 카메라가 사용될 수 있는 가능성을 확인했다. 향후 연구로 카메라 기반 장애물 회피 알고리즘의 성능을 최적화하는 방법에 관한 연구를 수행하고 실제 환경에서의 실험을 수행할 예정이다.

