





1. 서론
폐암은 국내 뿐 아니라 전 세계에서 사망률이 가장 높은 암종 중 하나이다[1]. 폐암의 병기 결정, 치료 계획 수립 및 치료 효과 모니터링을 위해 흉부 컴퓨터 단층 촬영(Computed Tomography, CT) 영상이 주로 사용된다. 종양 치료 효과를 평가하기 위한 기준으로 사용되는RECIST(Response Evaluation Criteria in Solid Tumors) 버전 1.1은 종양 크기 변화를 측정하여 폐암 환자의 치료 결과를 판단하는데 도움을 준다. 이 방법은 종양이 일반적으로 구형이라고 가정하며 종양의 1차원 최대 지름을 측정한다[2]. 그러나, 폐 종양이 구형이 아닌 불규칙한 모양을 가진 환자의 경우 이 방법은 한계가 있다. 따라서 이러한 환자의 치료 반응을 정확하게 평가하기 위해서는 종양 전체 부피를 측정하는 것이 필요하며, 이를 위해 흉부 CT 영상에서 폐암을 자동으로 분할하는 기술이 필요하다.
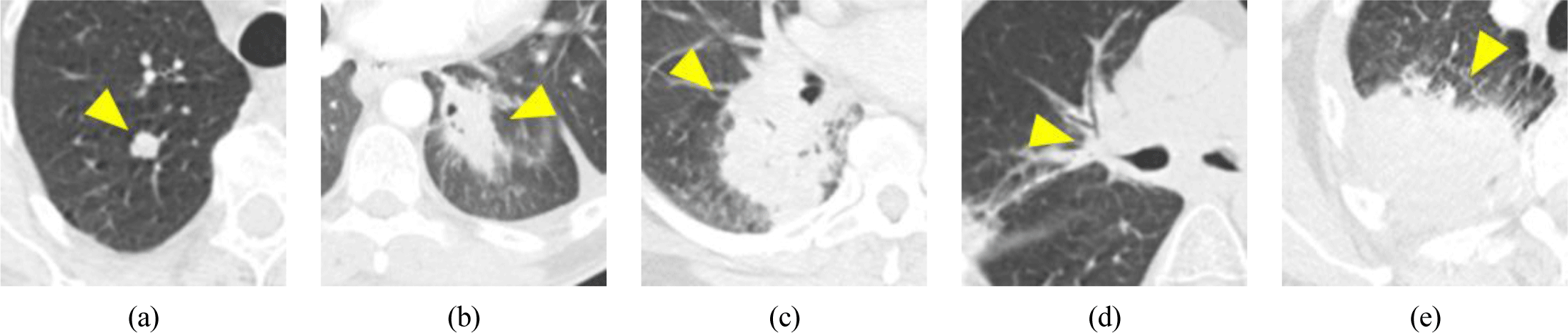
그림 1은 흉부 CT 영상에서 나타나는 폐암의 특징을 나타낸다. 폐암은 크기나 형태가 매우 다양하며 위치에 따라 폐실질(Lung parenchyma)에 명확하게 나타나기도 하지만 폐 흉벽(Chest wall), 흉강(Chest cavity), 종격동(Mediastinum), 폐혈관 등에 부착되어 있어 주변 구조물과의 경계를 정확하게 구분하기 어렵고, 이로 인해 분할을 자동화하기에 어려움이 있다.
흉부 CT 영상을 활용하여 폐암 분할에 대한 딥 컨볼루션 신경망 연구는 다음과 같다. Hossian[3]은 2차원 영상에 확장 컨볼루션(Dilated convolution)연산을 수행하여 특징 맵을 생성하고, 이들을 이어 붙여 3차원 볼륨으로 만들고 3차원 컨볼루션 연산을 수행하여 3차원 분할을 수행하는 하이브리드 모델을 제안하였다. 이 모델은 300명의 NSCLC-radiomics 데이터 중 260명을 훈련 데이터로, 40명을 테스트 데이터로 사용하여 65.7%의 다이스 유사계수 (Dice similarity coefficient, DSC) 성능을 보였다. Tuba[4]는 다양한 수용영역(Receptive field)에서 특징을 추출하기 위해 기존 UNet을 백본(Backbone)으로 하여 연속 확장 컨볼루션 (Consecutive dilated convolution)을 적용하는 방법을 제안하였으며, 이 모델은 335명의 NSCLC-radiomics 환자 데이터 중 62명을 테스트 데이터로 사용하여 53.34%의 DSC 성능을 보였다. Zhang[5] 등은 ResNet34 를 기반으로 디코더에서 멀티 스케일 특징 맵을 결합하는 형태로 변형된 ResNet 모델을 적용하였고, 이 모델은 300명의 NSCLC-radiomics 환자 데이터 중260명을 훈련 데이터로, 40명을 테스트 데이터로 사용하여 73%의 DSC 성능을 보였다. Lee[6]는 주변 구조물과의 관계를 학습하는 캡슐 네트워크를 사용하여 듀얼-윈도우 앙상블 네트워크를 제안하였으며, 자체 병원에서 얻은 260명의 폐암 환자 데이터 중 52명을 테스트 데이터로 사용하여 75.98%의 DSC성능을 보였다. Jeong[7]은 데이터 불균형 문제를 해결하기 위해 Dice와 Focal 손실 함수를 결합하여 U-Net을 기반으로 한 손실 함수를 제안하였으며, 자체 병원에서 얻은 80명의 폐암 환자 데이터를 사용하여 88.77%의 DSC 성능을 보였다.
본 논문에서는 흉부 CT 영상에서 다양한 크기의 폐암과 주변 구조물과의 경계가 불명확한 문제를 해결하기 위해 UNet3+[8] 네트워크 구조를 백본으로 활용하여, 전체 스케일 스킵 연결(Skip connection) 사용과 심층 감독(Deep supervision)을 통해 네트워크의 안전성을 향상시키고자 한다. 또한 폐암 영역에 더 집중할 수 있도록 하이브리드 병변 초점 손실 함수(Hybrid lesion focal loss: HLF loss) 를 제안한다.
2. 제안방법
흉부 CT 영상은 각 환자마다 다른 촬영 장비와 다양한 프로토콜을 사용하여 획득되므로 영상 간 차이가 발생할 수 있다. 이러한 차이를 최소화하기 위해 흉부 CT 영상에서 정규화(Normalization) 과정이 필요하다. CT 영상은 주로 각 기관을 볼 때 사용하는 다양한 밝기값 윈도우 셋팅을 가지고 있으며, 폐암 영역이나 주변 혈관, 주변 구조물을 잘 표현할 수 있는 폐 윈도우 셋팅을 사용한다. 폐 윈도우 셋팅은 윈도우 폭(Window width)을 1500HU(Hounsfield Unit), 윈도우 레벨(Window level)을 -600H로 설정하여, 영상의 픽셀 밝기값을 -1350HU~150HU 범위 내에서 0~255 밝기값으로 변환한다. 이후에 폐암의 중심 좌표를 기준으로 폐암을 포함하는 영역을 128x128 크기로 잘라 최종 입력 영상을 생성한다.
또한, 데이터 부족으로 인한 학습 시 과적합을 방지하기 위해 데이터 증강(Data augmentation) 기법을 적용한다. 이를 위해 -20도에서20도 사이의 임의 회전(Random rotation), -20픽셀에서 20픽셀 사이의 임의 이동(Random translation), 0.8배에서 1.2배 사이의 임의 스케일(Random scaling)을 적용한다. 학습 데이터에 대해 무작위로 3번의 데이터 증강을 적용하여 학습 데이터를 3배로 증가시킨다.
일반적으로 의료 영상 분할에 사용되는 UNet[9]은 특징을 추출하는 인코더(Encoder) 부분과 특징의 위치 정보를 파악하는 디코더(Decoder) 부분으로 구성되며, 대칭적인 U자 형태의 구조를 가진다. 이전 디코더 레이어에서 생성된 낮은 수준의 특징 맵과 스킵 연결을 통해 전달된 동일 레이어에서 나온 높은 수준의 특징 맵을 결합하여 디코더를 학습한다. UNet의 이러한 네트워크 구조는 적은 양의 학습 데이터로도 효과적인 학습이 가능하며, 빠른 학습 속도를 제공하는 장점이 있다. 그러나 스킵 연결을 통해 전달되는 정보는 동일한 수준의 인코더 상의 특징 정보 뿐이므로 폐암과 같은 다양한 크기의 종양에 대한 분할 정확도가 저하될 수 있다는 단점이 있다.
UNet의 이러한 한계점을 극복하기 위해 제안된 방법은 그림 2와 같이 UNet3+ 모델을 백본으로 사용하여 전체 스케일에 해당하는 특징 맵을 결합하는 스킵 연결을 수행한다. UNet3+는 각 디코더의 입력으로 이전 디코더에서 얻은 낮은 수준의 특징 맵과 상위 인코더에서 얻은 높은 수준의 특징 맵을 결합하여 디코더의 학습을 수행한다. 이 때 각 특징 맵의 크기과 채널 수를 동일하게 맞추기 위해 상위 인코더의 특징 맵은 맥스-풀링을 통해 다운 샘플링 작업과 컨볼루션을 수행하고, 하위 디코더의 특징 맵은 양선형 보간(Bilinear interpolation)을 통한 업 샘플링 작업과 컨볼루션을 수행한다. 또한, 깊은 레이어에서 나오는 특징 맵들을 활용하여 네트워크를 안정화하고 성능을 향상시키기 위해 심층 감독을 적용한다. 심층 감독은 마지막 디코더 레이어에서의 결과만으로 손실 함수를 계산하지 않고, 각 디코더 레이어에서의 결과를 모두 합산하여 손실함수를 계산한다. 이후 테스트 시에는 마지막 레이어에서 얻은 결과만을 사용하여 최종 결과를 생성한다.
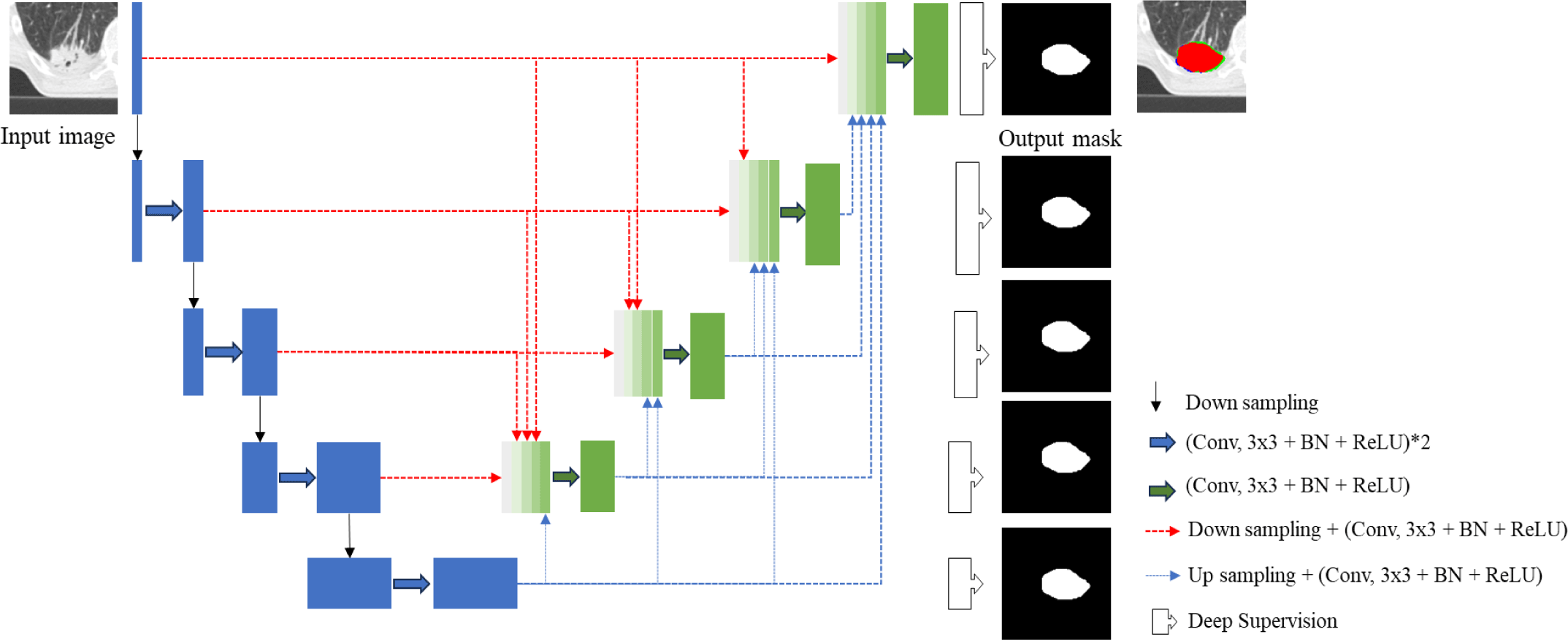
UNet3+는 각 디코더 레이어의 입력으로 상위 레이어의 인코더에서 얻은 높은 수준의 특징 맵과 이전 디코더 레이어에 서 얻은 낮은 수준의 특징 맵을 모두 고려함으로써 다양한 스케일의 특징 맵을 효과적으로 활용할 수 있다. 이러한 기능을 통해 다양한 크기를 가진 폐암의 특징을 더 잘 학습할 수 있어서 분할의 성능을 향상시킬 수 있다.
UNet3+는 다양한 크기의 폐암 정보를 고려할 수 있는 장점을 가지고 있지만, 폐암 영역은 전체 영상에서 매우 적은 픽셀을 차지하며, 주변 기관과 유사한 밝기값을 가지기 때문에 폐암의 경계가 불명확한 경우가 많다. 이를 해결하기 위해 하이브리드 병변 초점 손실 함수를 제안한다.
제안하는 손실함수는 픽셀 기반(Pixel-based), 영역 기반(Regional-based), 형태 기반(Shape-based)의 3가지 방식의 손실함수를 사용한다. 픽셀 기반의 손실함수는 각 픽셀 단위로 손실을 반영하고자 하는 목적을 가지며, 크로스 엔트로피 손실함수(Cross entropy loss, CE loss)를 변형한 초점 손실 함수 (Focal loss)를 사용한다. 초점 손실 함수는 모델이 추정한 확률이 낮은 픽셀에 집중하여 모델을 개선하고자 하는 방식으로 식 (1)과 같이 정의한다. 모델이 추정한 확률이 낮은 픽셀은 주로 폐암의 경계와 같이 분류하기 어려운 픽셀들을 나타내며, 이러한 픽셀들에 더 큰 가중치를 부여한다.
이 때, pi는 각 클래스에 대한 모델의 추정 확률을 의미하고, (1-pi)γ 는 변조인자(Modulating factor)로 확률 값이 클 경우 낮은 가중치를 부여하고 확률 값이 작을 경우 높은 가중치를 부여하여 분류하기 쉬운 픽셀과 어려운 픽셀에 다른 가중치를 부여하는 방식으로 적용되며, αi는 배경보다 분류하고자 하는 폐암 클래스에 더 큰 가중치를 부여하기 위해 사용된다. 본 연구에서는 폐암 클래스에 0.7, 배경 클래스에 0.3의 값을 할당하였으며, γ 값은 2로 설정한다.
영역 기반의 손실함수는 TP(True Positive), TN(True Negative), FP(False Positive), FN(False Negative)가 차지하는 영역에 대한 비율 정보를 기반으로 손실 함수를 계산하는 방식으로 DSC의 변형된 형태인 초점 트버스키 손실 함수(Focal tversky loss, FT loss)를 사용한다. 초점 트버스키 손실함수는 식 (2)와 같이 정의하며, 배경에 대한 TN 영역을 제외하고, 폐암 영역에 대하여 올바르게 분할한 TP 영역과 잘못 분할된 FP와 FN 영역을 고려하여 생성된 함수이다. 또한, 초점 손실함수와 같이 트버스키 손실 값이 작아질 때 손실 함수 값을 더 커질 수 있도록 하여 잘못된 영역이 많아질수록 가중치를 부여한다.
이 때, γ 값은 3/4 로 설정하며, δ 값은 0.3으로 설정하여 FP에 민감하도록 높은 가중치를 설정한다.
형태 기반의 손실 함수는 모델 분할 결과와 정답 마스크(Ground truth, GT) 간의 형태를 고려한 구조적 유사성 손실 함수(Structural similarity, SSIM)를 사용한다. 이는 불명확한 경계에서도 결과 마스크 간의 유사성으로 분할의 차이를 줄이도록 하는 방식으로 식 (4)와 같이 정의한다. 이 함수는 구조적으로 유사한 마스크를 생성할 수 있도록 하기 때문에 부정확한 폐암의 경계 영역에서도 유사한 결과를 만들 수 있도록 하는 장점이 있다.
이 때, p 와 g 는 분할 결과 마스크의 패치 영역과 정답 마스크의 패치 영역을 의미하고 μp,μg,σp,σg는 각각 패치 영역에서의 평균값과 분산을 의미하고, σpg는 교차 공분산을 의미한다.
3. 결과
실험에 사용한 데이터는 암 영상 아카이브에 공개된 공공 데이터셋으로 NSCLC-Radiomics 데이터셋으로 총 422명의 폐암 CT 영상으로 구성되어 있다. 422명의 데이터 중 39명의 선암(Lung Adenocarcinoma, LUAD) 및 115명의 편평상피세포암 (Lung Squamous Cell Carcinoma, LUSC) 데이터만을 선별하여 총 154명의 데이터를 사용하였고, 폐암의 직경은 1.38cm에서 14.63cm의 다양한 범위로 분포된다. 모든 데이터는 Siemens Healthineers사의 Biograph 40, SOMATOM Sensation 10, SOMATOM Sensation 16, SOMATOM Sensation Open 장비와 CMS imaging 사의 XiO 장비를 통해 촬영된 흉부 CT 영상을 사용하였다. 각 데이터의 영상 해상도는 512x512, 픽셀 크기는 0.97mm, 슬라이스 간격은 3mm이다. 학습과 검증을 위해 랜덤하게 선택하여 각각 111명과 13명의 환자 데이터를 사용하였고, 테스트를 위해 30명의 환자 데이터를 사용하였다.
제안 방법의 폐암 분할 성능을 분석하기 위해 정량적 성능 평가와 정성적 성능 평가를 수행하였고, 기본 UNet 과 UNet3+ 모델과의 비교를 통해 UNet3+ 모델을 백본으로 심층 감독을 수행하고 하이브리드-병변 초점 손실 함수를 사용한 제안 방법의 효과를 분석하였다. 정량적 평가에서는 DSC, 재현율(Recall) 및 정밀도(Precision)의 세가지의 평가지표를 사용하여 제안 방법의 분할 성능을 제시하였으며, 정성적 평가에서는 폐암 분할 결과 영상의 육안 평가를 수행하였다.
본 실험은 CUDA 10.1과 NVIDIA GeForce GTX 1080그래픽 카드를 탑재한 서버에서 python언어를 기반으로 수행되었다. 학습을 위한 하이퍼파라미터로는 배치(Batch) 크기를 8, 학습률(Learning rate)을 1e-5로 설정하고, 최대 에폭(Epoch) 수는 300으로 설정하였으며, 20 에폭 동안 검증 손실이 감소하지 않으면 조기 종료(Early stopping) 하도록 설정하였다.
Table 1은 전체 폐암에 대한 분할 성능 결과를 보여준다. 하이브리드-병변 초점 손실함수를 사용한 제안 방법이 UNet과 UNet3+를 적용한 결과에 비해 DSC 측면에서 각각 3.46%와 1.38% 향상되었음을 보인다. UNet3+를 적용한 결과가 제안 방법에 비해 재현율 측면에서 3.01% 높은 결과를 보이지만 정밀도 측면에서는 반대로 4.88% 낮은 결과를 보인다. 이는 UNet3+의 결과가 과대 분할된 결과를 나타내고, 제안 방법에서 정밀도가 더 높은 값을 보이며 과대 분할이 방지된 것을 확인할 수 있다.
Table 2는 폐암의 크기에 따른 성능 결과를 나타내며, 폐암의 TNM 병기에서의 T-단계와 동일하게 산정한 것으로 Group 1은 3cm보다 작은 폐암, Group 2는 3cm ~ 5cm 크기의 폐암, Group 3는 5cm 이상의 폐암으로 구분하였다. 크기에 따른 고려가 가장 적은 UNet의 경우 DSC 수치에서 모두 70% 이하의 낮은 성능을 보였으며, 특히 가장 작은 크기의 폐암인 Group1에서 가장 낮은 재현율을 보인다. 이는 작은 폐암의 경우 더 분할이 어렵다는 것을 확인할 수 있다. 다중 스케일이 고려된 UNet3+에서는 Group 3보다는 Group 1과 Group 2에서 더 큰 향상폭을 보이며, 크기에 상관없이 분할의 성능이 향상됨을 확인할 수 있고, 크기가 큰 Group 2와 Group 3에서는 가장 높은 재현율을 보이지만 정밀도는 낮아지거나 유사한 것을 확인 할 수 있다. 이는 다중 스케일의 고려와 심층 감독으로 인해 과대 분할이 발생한다는 것을 확인할 수 있다. 이를 해결하기 위해 하이브리드-병변 손실함수를 적용하면 재현율과 정밀도가 균형되게 향상되어 좀더 안정적인 분할 결과를 얻을 수 있다.
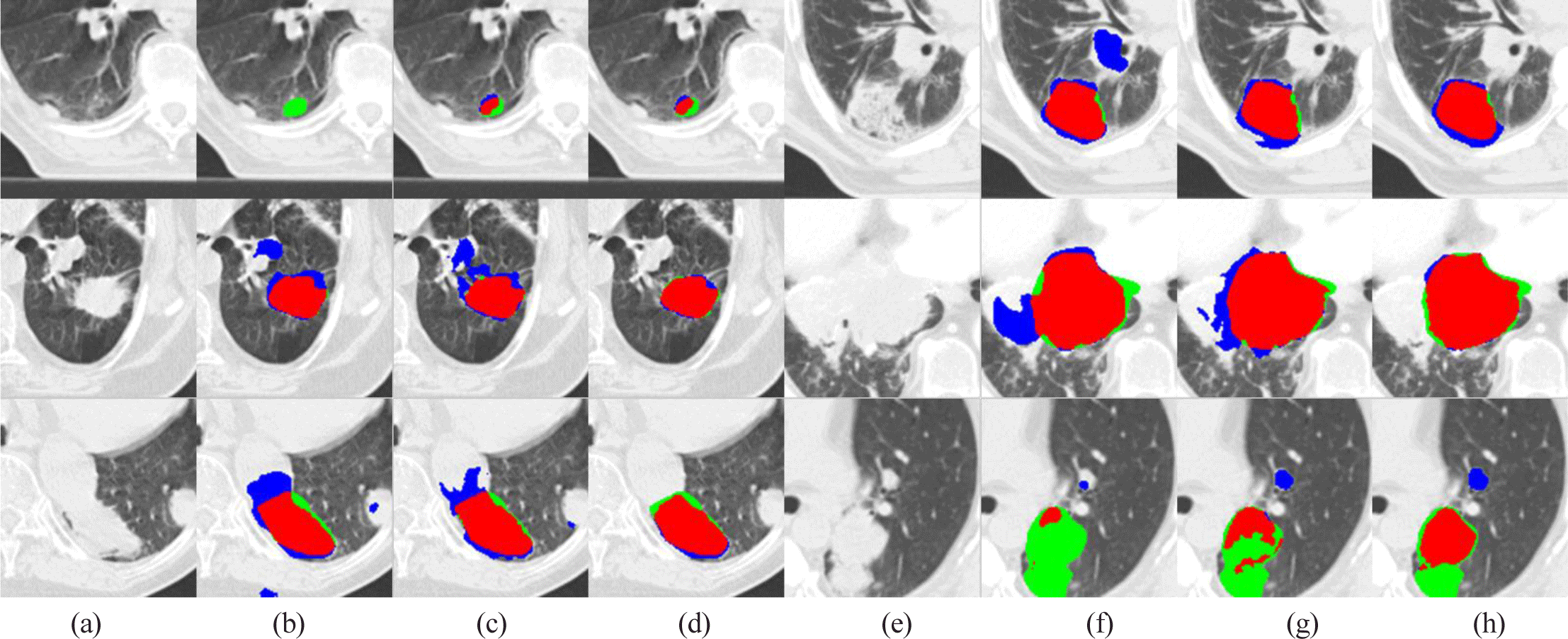
그림 3 은 흉부 CT 영상에서 폐암 분할 결과를 나타내며, UNet의 경우 작은 영역에서는 분할되지 않거나 배경 영역으로 오분할되는 경향이 많이 나타나는 것을 확인 할 수 있다. UNet3+의 경우 폐암의 분할 성능이 향상되었지만, 여전히 유사한 밝기값을 가진 주변 기관으로의 누수가 발생하는 경향이 있다. 반면 제안 방법은 주변 기관과의 밝기값 유사성으로 인한 누수를 크게 줄여 안정적인 분할 결과를 얻을 수 있다. 또한 UNet이나 UNet3+에서 폐암이 거의 분할되지 않는 경우에도 개선된 분할 결과를 확인할 수 있다.
4. 결론
본 논문에서는 흉부 CT 영상에서 다양한 크기와 유사한 밝기값을 가진 주변 구조물이 존재하는 폐암의 분할을 향상시키기 위한 분할 네트워크를 제안했다. 제안 네트워크는 UNet3+ 네트워크 구조를 백본으로 사용하며 다양한 스케일의 스킵 연결 및 심층 감독을 포함하고 하이브리드 병변 초점 손실함수를 제안했다. 다양한 스케일의 스킵 연결을 통해 다양한 특징 맵들의 정보를 결합하여 다양한 크기의 폐암 정보를 효과적으로 학습할 수 있도록 하였으며, 하이브리드 병변 초점 손실함수는 픽셀 및 영역 기반의 접근을 통해 폐암 영역에 집중할 수 있도록 손실함수를 설계하였고, 불명확한 경계를 고려하기 위해 폐암 마스크의 형태 정보를 고려한 손실함수를 사용했다. 실험 결과, 전체적인 분할 성능 및 다양한 크기 별 폐암 분할에서 가장 우수한 DSC 성능을 보였으며, 기존의 UNet3+에서 나타나던 FP를 줄일 수 있었다. 향후 연구 방향으로는 폐암의 공간 정보를 활용하는 다중-뷰 기반의 3차원 폐암 분할 네트워크로 확장하고, 폐암과 주변 구조물을 잘 구분할 수 있는 변환된 영상 사용을 통해 폐암 분할 성능을 개선하고자 한다.


