Article
위치 정보 인코딩 기반 ISP 신경망 성능 개선
Enhancing A Neural-Network-based ISP Model through Positional Encoding
DaeYeon Kim1
,
Woohyeok Kim1,
Sunghyun Cho1,*
Author Information & Copyright ▼
© Copyright 2024 Korea Computer Graphics Society. This is an Open-Access article distributed under the terms of the
Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/4.0/) which permits
unrestricted non-commercial use, distribution, and reproduction in any
medium, provided the original work is properly cited.
Received: Jun 15, 2024; Revised: Jul 02, 2024; Accepted: Jul 05, 2024
Published Online: Jul 25, 2024
요약
영상 신호 프로세서(Image Signal Processor, ISP)는 카메라 센서로부터 획득된 RAW 영상을 사람의 눈에 보기 좋은 sRGB 영상으로 변환한다. RAW 영상은 sRGB 영상에 비해 영상 처리에 도움이 되는 정보를 가지고 있지만 상대적으로 큰 용량으로 인해 주로 sRGB 영상만 저장되고 사용된다. 또한, 실제 카메라의 ISP 과정이 공개되어 있지 않아 그 역과정을 모사하는 것은 매우 어렵다. 이에 sRGB와 RAW 영상의 상호 변환을 위한 카메라 ISP 모델링 연구가 활발히 진행되고 있으며, 최근 기존의 단순한 ISP 신경망 구조를 고도화하고 실제 카메라 ISP의 동작과 유사하게 카메라 파라미터(노출 시간, 감도, 조리개 크기, 초점 거리)를 직접 반영하는 ParamISP[1] 모델이 제안되었다. 하지만 ParamISP[1]를 포함한 기존의 연구는 카메라 ISP를 모델링함에 있어 렌즈로 인해 발생하는 렌즈 쉐이딩(Lens Shading), 광학 수차(Optical Aberration), 렌즈 왜곡(Lens Distortion) 등을 고려하지 않아 복원 성능에 한계가 있다. 본 연구는 ISP 신경망이 렌즈로 인해 발생하는 열화를 보다 잘 다룰 수 있도록 위치 정보 인코딩(Positional Encoding)을 도입한다. 제안하는 위치 정보 인코딩 기법은 영상을 분할하여 패치(Patch) 단위로 학습하는 카메라 ISP 신경망에 적합하며 기존 모델에 비해 영상의 공간적 맥락을 반영할 수 있어 더욱 정교한 영상 복원을 가능하게 한다.
Abstract
The Image Signal Processor (ISP) converts RAW images captured by the camera sensor into user-preferred sRGB images. While RAW images contain more meaningful information for image processing than sRGB images, RAW images are rarely shared due to their large sizes. Moreover, the actual ISP process of a camera is not disclosed, making it difficult to model the inverse process. Consequently, research on learning the conversion between sRGB and RAW has been conducted. Recently, the ParamISP[1] model, which directly incorporates camera parameters (exposure time, sensitivity, aperture size, and focal length) to mimic the operations of a real camera ISP, has been proposed by advancing the simple network structures. However, existing studies, including ParamISP[1], have limitations in modeling the camera ISP as they do not consider the degradation caused by lens shading, optical aberration, and lens distortion, which limits the restoration performance. This study introduces Positional Encoding to enable the camera ISP neural network to better handle degradations caused by lens. The proposed positional encoding method is suitable for camera ISP neural networks that learn by dividing the image into patches. By reflecting the spatial context of the image, it allows for more precise image restoration compared to existing models.
Keywords: 영상 신호 프로세서; 위치 정보 인코딩; RAW-to-sRGB 변환; sRGB-to-RAW 변환
Keywords: Image Signal Processor; Positional Encoding; RAW-to-sRGB Conversion; sRGB-to-RAW Conversion
1. 서론
영상 신호 프로세서(Image Signal Processor, ISP)는 카메라 센서에 포착된 원본 RAW영상을 잡음 제거, 색상 보정, 결함 픽셀 보정, 화이트 밸런스 등의 과정을 거쳐 최종적으로 사용자가 보는 sRGB 영상으로 변환한다. RAW 영상은 카메라로 입사되는 빛의 강도와 색상 등의 정보가 거의 손실 없이 담겨 있어 카메라 ISP의 비선형 연산을 거친sRGB 영상에 비해 잡음 제거[4, 5, 6], HDR복원[7, 8] 등 다양한 영상 처리 작업에 유용하게 활용될 수 있다. 그러나 RAW영상은 sRGB영상에 비해 많은 용량을 차지하여 일반적으로 저장되지 않는다. 또한, 실제 ISP 는 카메라 마다 상이하며 공개되지 않아 그 역과정을 모사하는 것이 매우 어렵다.
이에 sRGB와 RAW 영상의 상호 변환을 위한 카메라 ISP 모델링 연구가 활발히 진행되고 있다[9, 10, 11, 12, 13]. 동일한 장면(Scene)에 대한 RAW와 sRGB 영상쌍을 특정 카메라로부터 획득할 수 있으며 이를 활용해 해당 카메라를 모사하는 정방향(RAW-to-sRGB) 및 역방향(sRGB-to-RAW) 카메라 ISP 신경망을 학습할 수 있다. 최근 기존의 단순한 신경망 구조를 고도화하고 실제 카메라 ISP의 동작과 유사하게 카메라 파라미터(노출 시간, 감도, 조리개 크기, 초점 거리)를 직접 반영하는 ParamISP[1] 모델이 제안되었으며 높은 복원 성능을 달성했다.
하지만 이러한 노력에도 불구하고 ParamISP를 포함한 기존의 연구는 카메라 ISP를 모델링함에 있어 렌즈로 인해 발생하는 위치 기반 열화를 고려하지 않아 복원 성능에 제한이 있다. 렌즈로 인해 발생하는 열화에는 영상의 외곽으로 갈수록 어두워지는 ‘렌즈 쉐이딩(Lens Shading)’, 빛이 한점으로 모이지 않아 영상이 일그러지는 ‘광학 수차(Optical Aberration)’, 영상의 외곽으로 갈수록 늘어지거나 볼록하게 표현되는 ‘렌즈 왜곡(Lens Distortion)’ 등이 있다.
최근 위치 정보 인코딩을 영상 잡음 제거(Image Denoising), 초해상화(Super Resolution), 영상 인페인팅(Image Inpainting) 등에 적용하는 연구가 등장하고 있다 [13, 14]. 본 연구는 카메라 ISP 신경망에 위치 정보 인코딩(Positional Encoding)을 도입하여 복원 성능을 향상시키는 것을 목표로 한다. 대부분의 영상 복원 신경망은 큰 해상도의 영상을 분할하여 패치(Patch) 단위로 학습한다. 본 연구는 패치 단위로 학습하는 ISP 신경망에 위치 정보 인코딩을 적용하여 렌즈로 인해 발생하는 열화와 큰 관련이 있는 위치 정보를 ISP 신경망에 제공한다. 위치 정보 인코딩은 절대좌표와 상대좌표, 6개의 Sin 함수와 Cos 함수를 적용한 절대좌표로 총 42개의 추가적인 입력 특징을 생성한다. 이러한 위치 정보는 ISP 신경망이 영상의 공간적 관계를 더 잘 이해할 수 있도록 도움으로써 복원 품질을 향상시키며 더욱 정밀하고 자연스러운 RAW-to-sRGB 및 sRGB-to-RAW 변환을 가능하게 한다.
2. ParamISP
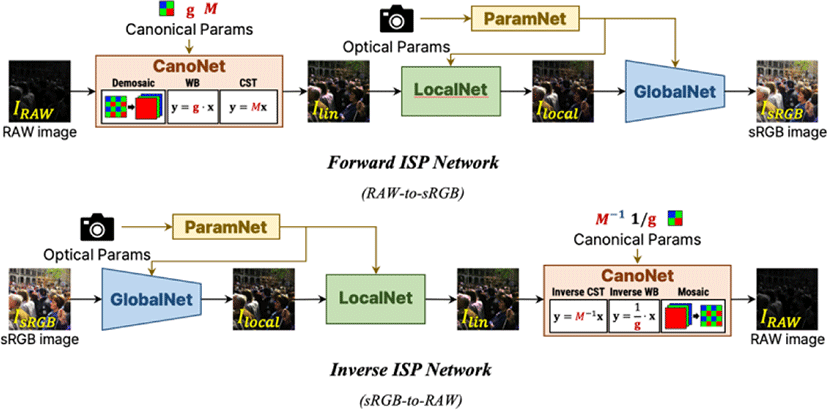
본 연구는 카메라 ISP 신경망 중 가장 좋은 성능을 보이는 ParamISP[1] 모델을 기준으로 위치 정보 인코딩의 효과를 보인다. ParamISP[1]는 동일한 구조의 정방향(RAW-to-sRGB)과 역방향 (sRGB-to-RAW) ISP신경망으로 구성되어 있으며 각각의 ISP 신경망은 CanoNet, LocalNet, GlobalNet, ParamNet 으로 구성된다.
CanoNet은RAW 영상을 입력으로 받아 디모자이킹(Demosaic ing), 화이트 밸런스(White Balance), 색공간 변환(Color Space Transform)을 차례로 수행한다. LocalNet은 잡음 제거(Denoising), 로컬 톤 매핑(Local Tone Mapping) 등 지역적 연산을 수행하고 GlobalNet은 연속적인 이차변환과 감마보정을 수행하여 영상의 전반적인 색조 및 색상을 변환한다. ParamNet은 카메라 파라미터(노출시간, 감도, 조리개 크기, 초점 거리)를 입력으로 받아 LocalNet과 GlobalNet의 동작에 영향을 끼친다.
2.1 입력 특징(Input Features)
ParamISP[1]의 LocalNet과 GlobalNet은ISP 신경망의 영상 복원 품질을 향상시키기 위해 입력 영상과 함께 입력 영상으로부터 생성한 다양한 입력 특징을 사용한다. 입력 특징은 입력 영상의 RGB 채널마다 2개의 기울기 맵(Gradient Map), 28개의 소프트 히스토그램 맵(Soft Histogram Map), 1개의 과다 노출 영역 마스크(Over-exposure Mask)로 이루어져 있으며 총 93개이다. 본 연구는 이어서 설명할 위치 정보 인코딩 특징을 입력 특징과 함께 ISP 신경망에 반영한다.
3. 위치 정보 인코딩을 활용한 ParamISP 개선
본 연구는 ISP 신경망의 영상 복원 성능 향상을 위해 위치 정보 인코딩(Positional Encoding)을 도입한다. NeRF[2]에서 선보인 위치 정보 인코딩은 위치 정보가 포함된 입력을 고주파수 정보로 변환함으로써 신경망의 학습에 도움을 주었다. 이러한 사례를 참고하여 렌즈로 인해 발생하는 위치 기반 열화를 다루기 위해 위치 정보 인코딩을 추가적인 입력 특징으로 활용한다. 이는 ISP신경망이 영상을 패치(Patch) 단위로 분할하여 학습하는 과정에서 실제 카메라 ISP와 같이 렌즈로 인한 위치 기반 열화를 잘 다루도록 돕는 역할을 한다. 위치 정보 인코딩은 패치의 각 픽셀마다 적용되며 ParamISP[1] 에서 LocalNet과 GlobalNet의 입력 특징에 추가된다.
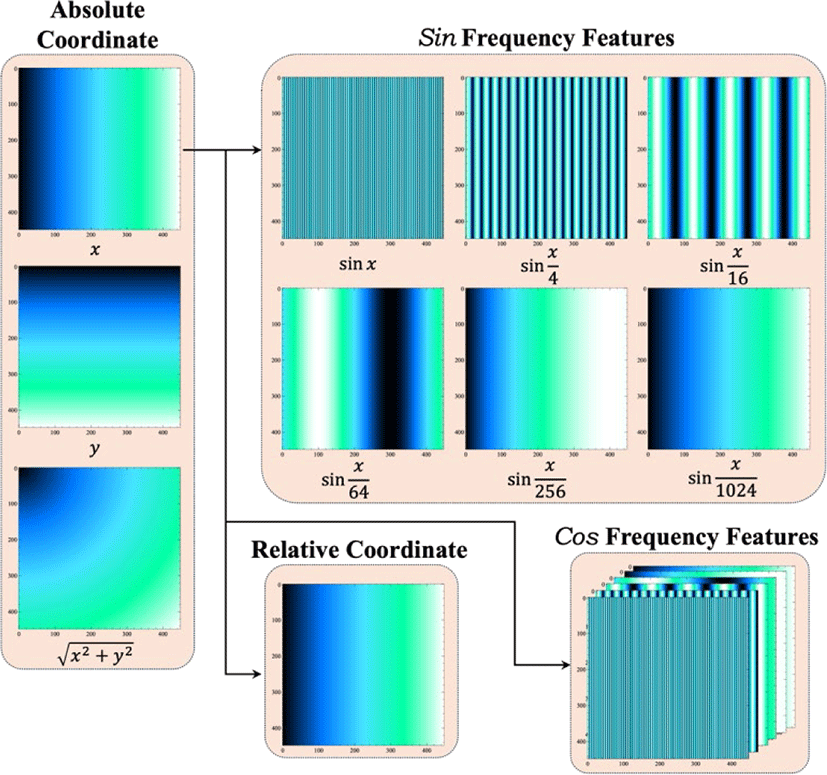
위치 정보는 절대좌표와 상대좌표로 구성된다. Figure 3과 같이 절대 좌표는 원본 영상의 왼쪽 위를 원점으로 설정하여 가로축과 세로축을 각각 픽셀의 x좌표, y좌표로 표현하여 영상 속 패치 내 픽셀의 정확한 위치를 나타낸다. 절대 좌표를 이용하여 각 픽셀의 x좌표, y좌표, 를 포함한 3개의 입력특징을 추가한다.
상대좌표는 해당 패치의 왼쪽 위를 원점으로 설정하고 패치 내 픽셀의 위치를 [0,1]로 정규화하여 해당 패치에서의 픽셀 간 상대적 위치를 나타낸다. 이는 ISP 신경망으로 하여금 패치 내부의 구조와 변형을 더 정확하게 학습할 수 있도록 한다.
또한, 각 픽셀의 절대좌표 (x, y, )를 기반으로 생성된 주파수 특징을 활용한다. 주파수 특징은 다음과 같은 6개의 sin 주파수 특징과 6개의 Cos 주파수 특징으로 구성된다.
-
6개의 Sin 주파수 특징
-
6개의 Cos 주파수 특징
여기서 c 는 픽셀의 절대 좌표 x, y, 이다.
따라서 총 입력 특징의 수는 기존의 96개에서 42개가 늘어난 138개이며 아래의 Table1과 같다.
Table 1.
Overall input features including positional encoding
| Type of Features |
Original ParamISP |
ParamISP w/Positional Encoding |
| Original |
96 |
96 |
| Absolute Coordinate |
0 |
3 |
| Relative Coordinate |
0 |
3 |
| Frequency |
0 |
36 |
| Total |
96 |
138 |
Download Excel Table
4. 실험 결과 및 분석
4.1 데이터 세트 및 실험 환경
본 연구에서는 RAISE[3] 의 NIKON D90과 D40데이터셋을 사용하였다. 모델 학습 시 초기 학습률(Learning Rate)을 0.0002로 설정하고 1000주기(Epoch)동안 학습시켰으며, 옵티마이저(Optimizer) 로 AdamW를 사용하고 10번의 주기마다 0.8의 비율로 학습률이 감소되도록 하였다. 또한, 특정 카메라 데이터셋에 대해서 주기마다 크기가 448 × 448인 1024개의 영상 패치를 무작위 추출하여 학습에 활용하였으며 NVIDA Tesla V100 GPU를 사용하였다.
Table 2.
Dataset composition
| Camera Model |
D90 |
D40 |
| Training |
1700 |
26 |
| Validation |
100 |
- |
| Testing |
400 |
50 |
Download Excel Table
본 연구의 ISP 신경망을 학습시키기 위해 정방향과 역방향의 손실함수로 각각 Lfor과 Linv를 사용하였으며 아래와 같다.
IsRGB는 원본 sRGB영상, ÎsRGB는 복원된 sRGB영상, IRAW는 원본 RAW영상, ÎRAW는 복원된 RAW영상이다.
4.2 검증 실험(Ablation Study)
위치 정보 인코딩(Positional Encoding)이 ISP 신경망의 성능 향상에 미치는 영향을 검증하기 위해 ParamISP[1]을 기준으로 절대좌표, 상대좌표, 주파수를 활용한 입력특징을 점진적으로 추가하면서 모델의 성능을 비교하였다. Table 3는 각각의 경우에 따른 성능이며 모두 D40 카메라 데이터셋으로 역방향 ISP 신경망을 학습 및 평가한 결과이다.
Table 3.
Comparison based on positional features of the D40 inverse ISP neural network
| Type of Features |
PSNR |
| Absolute |
Relative |
Frequency |
|
|
|
|
45.501 |
| ✓ |
|
|
46.462 |
| ✓ |
✓ |
|
46.617 |
| ✓ |
✓ |
✓ |
46.716 |
Download Excel Table
Table 3에서 첫 번째 행은 위치 정보 인코딩이 적용되지 않은 기준 ParamISP[1] 모델의 성능이다. 입력 특징으로 절대 좌표를 추가하면(2번째 행) 원본 영상을 기준으로 특정 패치 속 픽셀 간의 관계를 학습할 수 있어 성능이 약 0.96dB 향상된다. 또한, 상대 좌표 특징을 추가하면(3번째 행) ISP 신경망이 해당 패치 속 픽셀 간의 관계를 학습하여 약 0.16dB의 성능 향상을 보인다. 마지막으로 절대 좌표를 이용한 주파수 특징을 추가하면 (4번째 행) 주파수 변환을 통해 강화된 위치 정보를 반영할 수 있어 성능이 약 0.1dB 향상된다.
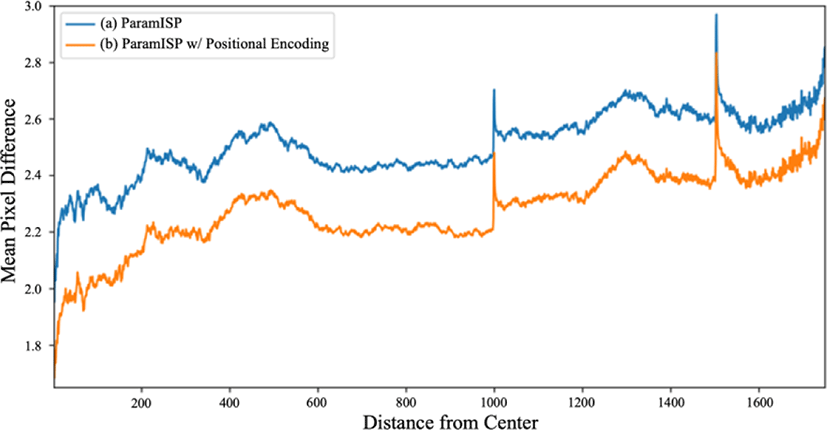
Figure 4는 위치 정보 인코딩을 적용하지 않은 ISP 신경망(a)과 적용한 ISP신경망(b)의 복원 영상에서 원본 영상과의 픽셀 값 차이를 나타낸 것이다. 이는 영상 중심으로부터 거리별로 측정되었다. 위치 정보 인코딩을 적용한 ISP 신경망이 영상 중심으로부터 거리에 상관없이 전반적으로 강인한 복원 성능을 보임을 확인할 수 있다.
Figure 5는 위치 정보 인코딩을 적용하지 않은 ISP 신경망 (b)과 적용한 ISP신경망(c)의 영상 복원 성능을 정성적으로 비교한다. 위치 정보 인코딩 적용 여부에 따른 영상의 밝기 차이를 유심히 살펴보면 위치 정보 인코딩을 적용한 ISP 신경망이 실제 D40 카메라의 ISP와 유사하게 잘 개선하는 것을 확인할 수 있다.
4.3 정방향 및 역방향 복원(sRGB & RAW Recon.)
여기서는 정방향(RAW-to-sRGB) 및 역방향(sRGB-to-RAW) ISP 신경망의 정량적/정성적 비교 결과를 보인다.
Table 4에서 위치 정보 인코딩을 적용한 정방향 ISP신경망은 D90카메라에서는 근소한 차이를 보였지만 D40 카메라에서는 PSNR이 약 0.31dB 향상되어 유의미한 차이를 보인다. Table 5에서 역방향 ISP 신경망에 위치 정보 인코딩을 적용한 결과 PSNR기준 D90, D40 카메라에서 각각 약 0.12dB, 1.21dB의 성능 향상을 보여준다. 정방향과 역방향 모두에서 위치 정보 인코딩이 적용된 ISP 신경망이 더 좋은 성능을 보이지만 정방향보다 역방향에서의 성능 향상 폭이 더 큰 것을 확인할 수 있다. 이는 상대적으로 많은 비트 수(큰 용량)의RAW 영상을 복원하는 것이 sRGB 영상을 복원하는 과정에 비해 어려운 문제일 수 있고 추가적인 위치 정보가 더욱 도움이 될 수 있기 때문인 것으로 추측된다.
Table 4.
Quantitative results of the forward ISP neural network
| Method |
RAW → sRGB |
| D90 |
D40 |
| PSNR |
SSIM |
PSNR |
SSIM |
| ParamISP |
30.583 |
0.969 |
39.461 |
0.985 |
| ParamISP w/positional encoding |
30.586 |
0.965 |
39.772 |
0.986 |
Download Excel Table
Table 5.
Quantitative results of the inverse ISP neural network
| Method |
sRGB → RAW |
| D90 |
D40 |
| PSNR |
SSIM |
PSNR |
SSIM |
| ParamISP |
36.479 |
0.974 |
45.501 |
0.986 |
| ParamISP w/positional encoding |
36.591 |
0.976 |
46.716 |
0.987 |
Download Excel Table
Figure 6과 7은 위치 정보 인코딩을 적용하지 않은 ISP 신경망(2번째 열)과 적용한 ISP 신경망(3번째 열)의 시각적 결과를 Error Map 을 통해 정성적으로 비교한다. 여기서 Error Map은 원본 영상과 복원된 영상의 픽셀 값 차이를 0과 1 사이로 정규화 한 결과이다. Error의 분포를 보면 위치 정보 인코딩을 도입한 모델이 영상 전반에 걸쳐 고른 복원 성능을 보이는 것을 확인할 수 있다.
5. 결론(Conclusion)
본 연구는 카메라 ISP 신경망의 복원 성능을 향상시키기 위해 위치 정보 인코딩(Positional Encoding)을 적용한다. 이를 위해 영상을 패치(Patch) 단위로 학습하는 ISP신경망에 픽셀의 위치 정보를 제공하여 특정 영상 속 패치 및 픽셀 간의 공간적 관계를 고려할 수 있도록 한다. 렌즈로 인해 발생하는 위치 기반의 열화와 관련이 있는 위치 정보 인코딩이 ISP 신경망의 복원 성능 향상에 효과적임을 복수의 카메라를 활용해 정량적/ 정성적으로 보인다. 향후 연구는 다양한 추가 입력 특징들에 대한 체계적인 분석을 통해 다양한 촬영 조건에서도 강인한 영상 복원 성능을 보이는 ISP 신경망 구현을 목표로 한다.
감사의 글
이 논문은 정부(과학기술정보통신부)의 재원으로 한국연구 재단(2023R1A2C200494611)의 지원 및 정보통신기획평가원 (No.2019-0-01906, 인공지능대학원지원(포항공과대학교))의 지원을 받아 수행된 연구임.
References
Woohyeok Kim, Geonu Kim, Junyong Lee, Seungyong Lee, Seung-Hwan Baek, Sunghyun Cho. ParamISP: Learned Forward and Inverse ISPs using Camera Parameters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024.

Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., & Ng, R. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In Proceedings of the European Conference on Computer Vision (ECCV).

Duc-Tien Dang-Nguyen, Cecilia Pasquini, Valentina Conotter, and Giulia Boato. RAISE: A raw images dataset for digital image forensics. In Proceedings of the 6th ACM multimedia systems conference (MMSys), 2015. 2, 5, 6
Abdelrahman Abdelhamed, Stephen Lin, and Michael S Brown. A high-quality denoising dataset for smartphone cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
Ben Mildenhall, Jonathan T Barron, Jiawen Chen, Dillon Sharlet, Ren Ng, and Robert Carroll. Burst denoising with kernel prediction networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
Yu-Lun Liu, Wei-Sheng Lai, Yu-Sheng Chen, Yi-Lung Kao, Ming-Hsuan Yang, Yung-Yu Chuang, and Jia-Bin Huang. Single-image hdr reconstruction by learning to reverse the camera pipeline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, and Jonathan T Barron. Unprocessing images for learned raw denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
Marcos V. Conde, Steven McDonagh, Matteo Maggioni, Ales Leonardis, and Eduardo Pe ́rez-Pellitero. Model-based image signal processors via learnable dictionaries. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 36(1):481–489, 2022.
Yazhou Xing, Zian Qian, and Qifeng Chen. Invertible image signal processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Cycleisp: Real image restoration via improved data synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
Nimrod Shabtay, Eli Schwartz, and Raja Giryes. PIP: Positional Encoding Image Prior.
Qiaole Dong, Chenjie Cao, and Yanwei Fu. Incremental Transformer Structure Enhanced Image Inpainting with Masking Positional Encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
<저 자 소 개>
김 대 연

김 우 혁

조 성 현

-
2005년 8월 포항공과대학교 컴퓨터공학과 학사
-
2012년 2월 포항공과대학교 컴퓨터공학과 박사
-
2006년 8월 ~ 2007년 2월 Microsoft Research Asia 인턴
-
2010년 7월 ~ 2010년 11월 Adobe Research 인턴
-
2012년 3월 ~ 2014년 3월 Adobe Research 연구원
-
2014년 4월 ~ 2017년 4월 삼성전자 책임연구원
-
2017년 4월 ~ 2019년 8월 대구경북과학기술원 조교수
-
2019년 8월 ~ 현재 포항공과대학교 조교수