





1. 서론
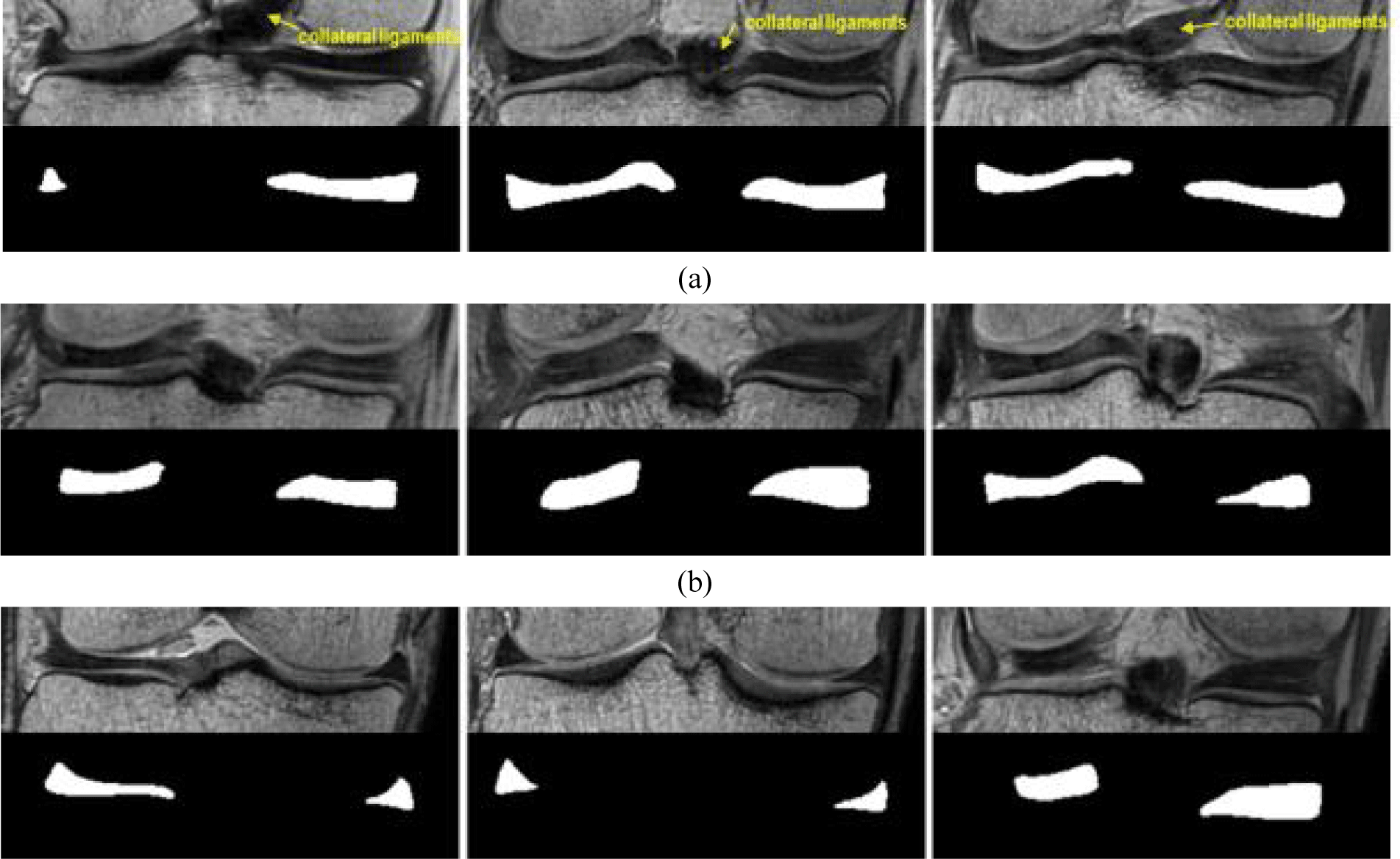
반월상 연골은 무릎 안쪽에 위치한 내측 반월상 연골과 무릎 바깥쪽에 위치한 외측 반월상 연골로 구성된 얇은 반달 모양의 구조물로, 무릎의 하중을 분산시키고 경골과 대퇴골 사이의 마찰을 줄이는 역할을 한다[1]. 무릎 질환으로 인해 반월상 연골이 마모되거나 파열된 경우, 이를 치료하기 위해 반월상 연골 이식편 이식 수술이 수행된다. 이식편의 크기와 형태가 환자의 본래 반월상 연골과 유사할수록 수술 후 기능 회복에 큰 영향을 미치므로, 일반적으로 환자 반대쪽 무릎을 미러링하여 가장 적합한 크기와 형태의 이식편을 제작한다[2]. 따라서 이식편을 정확하게 생성하기 위해서는 반월상 연골의 길이, 너비, 높이 등의 구조적 정보를 정확히 파악하는 분할 과정이 필수적이다. 그러나 그림 1과 같이 무릎 MR 영상에서 반월상 연골은 주변 구조물인 십자인대와 밝기값이 유사하고, 내부 밝기값이 불균일하여 오분할이 발생하기 쉽다. 또한, 반월상 연골은 두께가 얇고, 한 환자의 영상 내에서도 전방과 후방 슬라이스에서 형태가 다양하게 나타나므로 분할에 어려움이 있다.
무릎 MR 영상에서 반월상 연골 분할에 대한 연구는 일반적으로 지도학습을 사용하여 수행된다. Byra 등[3]은 작은 크기를 가지는 반월상 연골을 더 잘 분할하기 위해 중요한 영역에 집중할 수 있도록 하는 Attention U-Net을 제안하였으며, 데이터가 제한적인 환경에서도 높은 성능을 유지할 수 있도록 전이 학습을 추가로 활용하였다. Ölmez 등[4]은 두 개의 다른 무릎 MR 시퀀스 영상에서 반월상 연골의 대략적인 위치를 파악하기 위해 R-CNN을 통해 반월상 연골을 위치화 하여 분할 한 뒤, 이진화 및 형태학적 연산(morphological operation)을 적용해 최종적으로 반월상 연골을 분할하였다. Li 등[5]은 다양한 크기의 반월상 연골을 고려하기 위해 다양한 스케일을 추출하는 Residual Network-Feature Pyramid Network(ResNet-FPN)을 백본으로 하는 3D-mask-RCNN을 제안하였다. Luo 등[6]은 반월상 연골이 가지는 모양 및 크기의 가변성 문제를 보완하기 위해 다양한 스케일을 고려하는 스킵 연결을 적용한 Res2Net과 Swin Transformer를 융합한 모델을 제안하였다. 이와 같은 지도학습을 통한 반월상 연골 분할은 레이블 데이터가 부족한 경우 성능 저하가 발생할 수 있으므로 충분한 레이블 데이터를 확보하는 것이 중요하다. 그러나 의료 영상에서 고품질의 레이블 데이터를 확보하기 위해서는 많은 시간과 비용이 소요되어 레이블 데이터 수집에 한계가 있다[7-11]. 이러한 레이블 데이터 부족 문제를 완화하기 위해 소량의 레이블이 있는 데이터와 대량의 레이블이 없는 데이터를 함께 활용하여 효과적으로 훈련하는 준지도학습(semi-supervised learning) 방법이 제안된다. 준지도학습은 훈련 시 대량의 레이블이 없는 데이터를 활용함으로써 데이터의 전반적인 분포와 특징을 파악하고, 모델이 더 풍부한 정보를 학습할 수 있도록 해 네트워크의 일반화 성능을 향상시킨다[12].
따라서 본 논문에서는 무릎 MR 영상에서 다양한 형태와 두께를 가지는 반월상 연골에 대한 분할 성능 개선을 목표로, 레이블 데이터가 부족한 환경에서도 안정적인 분할 성능을 보이기 위해서 레이블이 없는 데이터를 함께 활용하는 준지도학습 모델을 제안한다. 제안된 모델은 잘못 예측할 가능성이 높은 영역을 나타내는 모호성 맵(ambiguity map)을 활용해 학생 모델과 교사 모델 간의 예측 일관성을 강화한다. 또한, 다양한 형태와 얇은 구조로 인해 분할 성능이 저하되는 반월상 연골을 고려한 분할 난이도 가중치(segmentation difficulty weight)와 무릎 MR 영상에서 배경에 비해 적은 영역을 차지하는 반월상 연골로 인해 발생하는 클래스 불균형 문제를 해결하기 위한 두께 가중치(thickness-sensitive weight)를 적용한 평균-교사 네트워크를 설계하였다. 마지막으로 레이블이 있는 데이터와 레이블이 없는 데이터의 개수를 조정하며 실험을 수행해, 준지도학습에서 레이블이 있는 데이터와 레이블이 없는 데이터의 비율이 성능에 미치는 영향을 분석한다.
2. 제안 방법
반월상 연골의 얇은 두께로 인해 전체 무릎 MR 영상에서 반월상 연골을 분할 할 시, 배경 영역과 반월상 연골 영역 간의 크기 차이로 인한 클래스 불균형이 발생하여 과소분할 문제가 나타난다. 따라서 반월상 연골의 지역적 문맥 정보에 집중하여 분할하기 위해, 반월상 연골의 해부학적 정보를 반영하여 ROI(Region Of Interest, ROI)를 설정하였다[13]. 전후방(front, back) 범위는 대퇴골과 경골이 동시에 나타나는 첫 번째 단면을 기준으로 정하고, 좌우(left, right) 범위는 대퇴골이 처음 나타나는 위치를 기준으로 설정한다. 또한, 상하(top, bottom) 범위는 대퇴골과 경골이 맞닿는 중심선을 기준으로 반월상 연골이 포함될 수 있도록 조정하여 최종 ROI를 결정한다. 이후, 해당 ROI를 기준으로 영상을 잘라 291x80 크기로 조정한다.
무릎 MR 영상에서 반월상 연골과 주변 구조물 간의 밝기값이 유사한 경우, 주변 구조물을 반월상 연골로 판단하여 오분할이 발생할 수 있다. 따라서 영상의 밝기값을 조정하여 반월상 연골과 주변 구조물이 잘 구별될 수 있도록 식 (1)과 같이 Z-Score 정규화를 통해 밝기값 정규화를 수행한다[14].
이 때, z는 정규화된 밝기값이고 x는 원본영상의 밝기값이고 μ은 밝기값의 평균이고 σ은 밝기값의 표준편차이다.
본 제안 방법은 그림 2와 같이 평균-교사 모델[15]로 구성된 네트워크이다. 레이블이 있는 데이터와 레이블이 없는 데이터를 함께 평균-교사 모델의 입력 영상으로 사용하고, 학생 모델의 예측값에서 오류가 발생할 가능성이 높은 영역을 나타내는 모호성 맵과 분할 성능과 반월상 연골의 픽셀 개수에 따라 계산되는 가중치를 고려하여 모델을 학습시켜 반월상 연골을 분할한다.
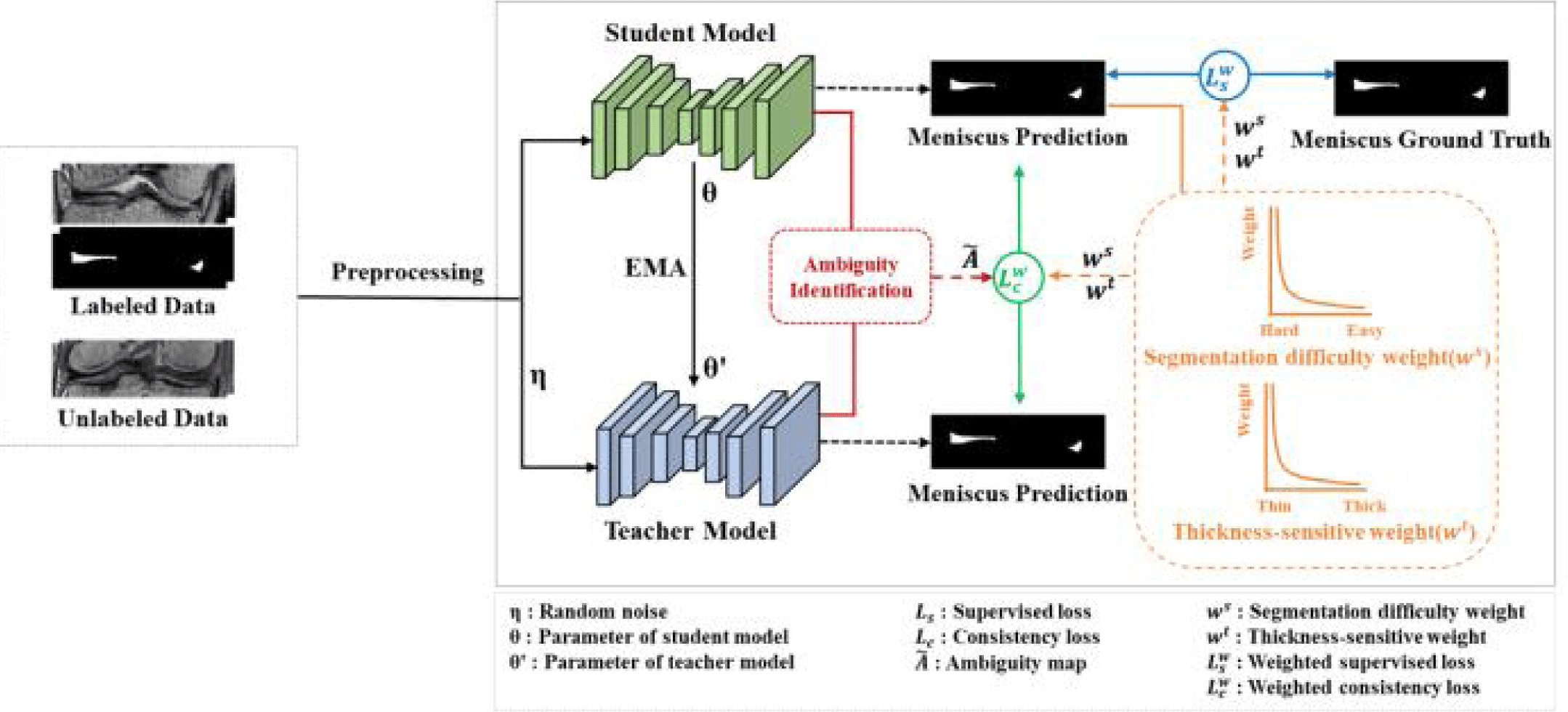
평균-교사 모델은 학생 모델과 교사 모델로 구성되며 레이블이 있는 데이터와 레이블이 없는 데이터를 함께 사용하여 준지도학습을 수행한다. 학생 모델의 파라미터는 손실함수를 계산하여 갱신되며, 교사 모델의 파라미터는 식 (2)와 같이 학생 모델의 파라미터와 이전 단계의 교사 모델 파라미터 간의 지수이동평균(Exponential Moving Average, EMA) 방식으로 갱신된다. 이러한 EMA 업데이트 방식은 학습 과정에서 발생하는 변동을 줄여 보다 일관된 예측을 제공할 수 있도록 하며, 학생 모델은 이러한 교사 모델의 안정적인 예측을 사용해 학습을 진행한다.
이 때, θt는 교사 모델의 파라미터이고 θt-1는 이전 단계의 교사 모델 파라미터이고 θs는 학생 모델의 파라미터이고 α는 이동평균을 조절하는 하이퍼파라미터 값이고 0.99로 산정하였다.
학생과 교사 모델 모두 백본 네크워크로 2D U-Net을 사용한다. 2D U-Net[16]은 U자 구조를 가지며, 5개의 레이어로 이루어진 인코더(encoder)와 디코더(decoder)로 구성되어 있다. 인코더에서는 3x3 컨볼루션 연산, 배치 정규화와 ReLU 활성화 함수를 적용하고, 2x2 맥스풀링과 드롭아웃을 통해 특징맵을 생성한다. 디코더에서는 2x2 업샘플링을 수행하고, 동일 레이어의 인코더 특징맵을 스킵 연결한 뒤 3x3 컨볼루션 연산, 배치 정규화, ReLU 활성화를 반복 적용한다. 디코더의 마지막 레이어에서는 시그모이드 활성화 함수를 사용하는 1x1 컨볼루션을 적용하여 예측 확률맵을 생성한다. 네트워크의 일반화 성능 향상을 위해 인코더에서 드롭아웃을 수행되며, 교사 모델의 입력 영상에 랜덤 노이즈를 추가하여 추가적인 섭동(perturbation)을 가한다.
제안하는 가중치 전략을 통해 모델의 일반화 성능을 강화하고, 학습 시 반월상 연골의 다양한 형태와 두께를 반영하여 분할 성능을 개선하고자 한다.
딥러닝에서 신뢰할 수 있는 영역이란 예측이 안정적이고 엔트로피(entropy) 값이 낮아 불확실성이 적은 영역을 나타내고, 모호한 영역은 예측이 불안정하고 엔트로피 값이 높아 불확실성이 높은 영역을 말한다. 모델이 신뢰할 수 있는 영역보다 오류가 발생하기 쉬운 모호한 영역에 집중하여 학습하면 더 많은 정보적 단서를 얻을 수 있어 모델의 성능 향상에 더 효과적일 수 있다[17]. 먼저 식 (3)과 같이 학생 모델의 예측값 ps로부터 엔트로피 En을 계산하고, 이후 식 (4)와 같이 계산된 엔트로피 값이 임계값 H를 초과하는 영역(En > H)을 모호성 맵 A ̃ 으로 정의한다. 학습 과정에서 이 모호성 맵을 활용하여 학생 모델과 교사 모델 간의 예측 일관성을 강화함으로써, 네트워크의 일반화 성능을 향상 시킬 수 있다.
이 때, ∥(⋅)는 지시 함수이고, H는 0.6으로 설정한다[17].
반월상 연골의 형태가 다양하여 분할 성능이 낮게 나타나는 문제를 해결하기 위해 분할 난이도 가중치 ws를 적용하여 모델이 쉬운 사례보다 분할 성능이 좋지 않은 어려운 사례에 집중하도록 한다. 분할 난이도 가중치는 식 (5)와 같이 이전 반복과 현재 반복 사이의 다이스 점수 변화가 크고 다이스 점수가 낮은 어려운 사례에 더 높은 가중치를 할당한다. 이 방법은 어려운 사례에 더 많은 주의를 기울이고 쉬운 사례에 더 낮은 가중치를 할당한다.
이 때, λt는 t번째 반복 단계(iteration)에서의 다이스 점수(dice score)이고, α는 1/2로 설정한다.
배경에 비해 비교적 작은 영역을 차지하는 얇은 구조의 반월상 연골은 클래스 불균형으로 인해 분할하기 어렵다. 이를 해결하기 위해 두께 가중치 wt를 적용하여 얇은 구조의 반월상 연골의 영향을 높여 클래스 불균형을 완화시킨다. 식 (6)과 같이 학생 모델의 결과를 사용하고 가중치는 배경과 반월상 연골의 픽셀 수를 기반으로 계산되며, 반월상 연골이 차지하는 픽셀이 적을 때 더 높은 가중치를 할당한다.
이 때, Nb와 Nm 는 각각 배경 및 반월상 연골 픽셀 수를 나타내고, ϵ 은 0.1로 설정된 평활화 계수이며, β는 1/5로 설정한다.
손실함수는 학습 과정에서 모델 수렴에 직접적인 영향을 미치므로 분할 대상의 특성을 잘 반영하는 손실함수를 사용하여 모델 파라미터를 최적화해야 한다.
지도 손실함수(supervised loss, Ls)는 레이블이 있는 데이터에서 학생 모델이 출력한 예측값과 실제 정답 레이블 간의 차이를 계산하여 모델이 실제 정답에 더 가까운 예측을 생성할 수 있도록 모델을 학습시킨다. 지도 손실함수는 식 (7)과 같이 이항 교차 엔트로피(binary cross entropy)와 다이스 손실(dice loss)의 합으로 계산된다. 일관성 손실함수(consistency loss, Lc)는 레이블이 있는 데이터와 없는 데이터 모두에서 학생 모델과 교사 모델이 출력한 예측값 간의 차이를 계산해 두 모델 간의 예측 일관성을 유지하도록 모델을 학습시킨다. 일관성 손실함수는 식 (8)과 같이 평균 제곱 오차(Mean-squared error)로 계산되며, 실제 정답 레이블이 필요하지 않아 레이블이 없는 데이터에 대한 학습이 가능해진다.
지도 손실함수와 일관성 손실함수 계산 시, 반월상 연골의 다양한 형태와 두께에 초점을 맞출 수 있도록 분할 난이도 가중치 ws와 두께 가중치 wt를 각 손실함수에 곱하여 식 (9)와 (10)과 같이 가중 지도 손실함수(weighted supervised loss, )와 가중 일관성 손실함수(weighted consistency loss, )를 계산한다. 이때 모델 간의 예측 일관성을 강화하기 위해 모호성 맵 Ã을 일관성 손실함수에 추가적으로 곱하여 계산한다.
결과적으로, 최종 손실함수는 식 (11)과 같이 가중 지도 손실함수와 가중 일관성 손실함수를 함께 사용하여 레이블이 있는 데이터와 없는 데이터를 학습에 활용한다.
이 때, CE(•), DICE(•) 및 MSE(•)는 각각 이항 교차 엔트로피, 다이스 손실 및 평균 제곱 오차이다. yi는 i번째 데이터의 정답 레이블이고 ŷi은 i번째 데이터에 대한 학생 모델을 통해 출력된 예측값이고 ỹi는 i번째 데이터에 대한 교사 모델을 통해 출력된 예측값이다.
3. 실험 및 결과
제안 방법의 실험을 위해 무릎 관절 퇴화로 인한 재건 수술을 받은 환자의 반대편 정상 무릎 MR 영상 268개를 사용하였으며, 해당 연구는 서울 삼성서울병원 기관윤리심의위원회의(IRB 승인 번호: 2010-08-116, 2013-07-097) 승인을 받았다. 이 영상은 Achieva 3.0T Philips Medical System 장비를 통해 촬영된 3D PD VISTA MR 영상으로, 해상도는 512x512이며 슬라이스 장수는 230~250장, 슬라이스 두께는 0.5mm, 슬라이스 간격은 0.3125mm이다.
GeForce RTX 3090 그래픽 카드가 장착된 서버에서 파이썬 기반의 딥러닝 라이브러리인 Pytorch 1.10.1 버전을 사용하여 실험을 수행하였다. 네트워크 학습 시 에폭은 400, 학습률은 0.001, 배치 크기는 16으로 설정하였으며 최적화를 위해 아담 옵티마이저를 사용하였다. 또한 학생과 교사 모델의 각 레이어에 [0.005, 0.1, 0.2, 0.3, 0.5]의 드롭아웃을 적용하였다. 실험은 홀드아웃(hold-out) 검증 방식을 사용하였으며, 훈련 데이터 248개와 테스트 데이터 20개로 나누고, 훈련데이터에서 레이블이 있는 데이터와 레이블이 없는 데이터의 비율을 조정하면서 실험을 진행했다.
본 제안 방법의 성능을 평가하기 위해 정량적 평가와 정성적 평가를 수행하였으며 정량적 평가에는 F1-score, 재현율, 정밀도를 성능지표로 하여 제안 방법과 비교 방법 간의 분할 성능을 평가하였다. 무릎 MR 영상에서 반월상 연골 영역은 배경 영역에 비해 상대적으로 작은 영역을 차지하여 반월상 연골과 배경의 비율이 불균형하므로 각 영역에 대한 성능을 균등하게 고려하기 위해 반월상 연골과 배경의 정확도를 따로 계산한 후 평균을 취하는 균형 정확도(balanced accuracy)도 평가하였다. 본 제안 방법의 평가를 위해 2D nnU-Net[18]을 사용한 지도학습 방법과 평균-교사 모델(Mean Teacher, MT)에 다양한 가중치 조합을 적용한 제안 방법들을 비교하였다. 또한, 전체 훈련데이터에 대해 레이블이 있는 데이터와 없는 데이터의 개수를 조정하여 네트워크 훈련에 사용되는 데이터 수에 따른 성능을 분석하였다.
표 1은 레이블이 있는 데이터와 없는 데이터의 개수에 따른 지도학습 및 준지도학습 방법의 반월상 연골 분할 성능지표를 나타낸다. 지도학습 방법의 경우, 레이블이 있는 데이터 83개를 사용한 방법과 비교했을 때, 22개를 사용한 방법에서는 F1-score, 재현율, 정밀도 값이 전반적으로 감소하는 경향을 보였다. 준지도학습을 기반으로 하는 기본 MT 모델은 레이블이 있는 데이터 22개와 레이블이 없는 데이터 63개를 함께 활용하여, 적은 레이블 데이터만으로 학습된 2D nnU-Net 보다 높은 F1-score와 재현율을 보였다. 이는 레이블이 없는 데이터가 추가적인 정보를 제공하여 모델의 예측 성능을 향상시켰기 때문이다. 또한, 모호성 맵을 MT 모델에 적용한 방법(MT+AMB)은 모델 간의 일관성을 강화하여 일반화 성능을 높였으며, 기본 MT 방법대비 0.58%p 증가한 90.75%의 재현율을 보였다. 그러나 모호한 영역에 집중하여 분할 하도록 하는 모호성 맵을 적용함으로써 모델이 모호하거나 경계가 불확실한 영역까지 과도하게 예측해 과대분할이 발생하여 정밀도는 하락하였다. 분할 난이도 가중치를 추가적으로 적용한 방법(MT+AMB+ws)은 형태가 다양한 반월상 연골에서 성능 저하가 발생하는 문제를 보완하고 과대분할을 개선하여, MT+AMB에 비해 정밀도를 10.73%p 향상시켰다. 두께 가중치를 적용한 방법(MT+AMB+wt)은 클래스 불균형 문제를 보완하여 과소분할을 개선하였으며, 그 결과 재현율 91.52%, F1-score 89.72%, 균형 정확도 95.56%를 보이며 전반적인 분할 성능이 MT+AMB 보다 향상되었다. 분할 난이도 가중치와 두께 가중치를 함께 적용한 방법(MT+AMB+ws+wt)은 가장 적은 양의 레이블이 있는 데이터를 사용한 방법들 중에서 재현율 93.28%, F1-score 90.02%, 균형 정확도 96.42%로 가장 높은 성능을 달성하였다. 예측이 어려운 영역과 얇은 구조를 더 적극적으로 반영함으로써 가장 높은 재현율을 보였지만 동시에 예측 범위가 확장되면서 정밀도가 상대적으로 하락하는 결과가 나타났으나, 제안된 가중치 전략이 서로 보완적으로 작용하면서 재현율-정밀도 간의 트레이드 오프가 효과적으로 조절되어 가장 좋은 F1-score 결과를 보였다. 또한, 레이블 데이터를 증가시켜 학습한 nnUNet에 비해 재현율, 균형 정확도가 각각 0.8%p, 0.35%p 향상되어 레이블이 제한된 데이터 환경에서도 효과적인 분할 성능을 보임을 확인하였다.
| Methods | Network | Ratio(%) | Metrics(%) | ||||
|---|---|---|---|---|---|---|---|
| Labeled | Unlabeled | Balanced accuracy | F1-score | Recall | Precision | ||
| Supervised learning | 2D nnU-Net[18] | 22 | - | 94.42±2.0 | 89.40±1.6 | 89.16±4.2 | 90.09±4.8 |
| 83 | - | 96.07±1.7 | 90.95±1.9 | 92.48±3.7 | 89.86±5.2 | ||
| Semi supervised learning | MT[15] | 22 | 63 | 94.92±2.0 | 89.90±1.9 | 90.17±4.2 | 90.06±5.1 |
| MT+AMB | 94.92±1.6 | 83.27±3.9 | 90.75±3.4 | 77.47±7.6 | |||
| MT+AMB+ws | 95.09±1.7 | 89.18±1.9 | 90.59±3.7 | 88.20±5.2 | |||
| MT+AMB+wt | 95.56±1.8 | 89.72±1.8 | 91.52±3.8 | 88.39±5.1 | |||
| MT+AMB+ws+wt | 96.42±1.6 | 90.02±2.1 | 93.28±3.5 | 87.39±5.6 | |||
| MT+AMB+ws+wt | 22 | 226 | 96.87±1.6 | 88.81±2.6 | 94.32±3.4 | 84.35±6.3 | |
| MT+AMB+ws+wt | 83 | 165 | 97.02±1.5 | 91.11±2.3 | 94.45±3.2 | 88.39±5.8 | |
레이블이 있는 데이터 22개와 레이블이 없는 데이터 226개를 사용한 제안 모델은 레이블이 없는 데이터를 더 많이 활용하여 학생 모델과 교사 모델 간의 일관성을 강화하였다. 그 결과, 재현율이 1.04%p 향상되었으며, 83개의 레이블이 있는 데이터를 사용하는 nnU-Net보다도 1.84%p 높은 재현율을 보였다. 그러나 레이블이 없는 데이터의 양이 지나치게 많아지면서 일부 잘못된 예측이 학습에 반영되면서 상대적으로 과대분할 문제가 발생해 정밀도가 다소 하락하였다. 반면, 레이블이 있는 데이터 83개를 사용한 제안 모델은 충분한 레이블 데이터로부터 모델이 직접적인 피드백을 받으며 안정적으로 학습할 수 있었다. 이를 통해 과소분할과 과대분할 문제가 모두 개선되었으며, 가장 높은 F1-score와 재현율을 달성하였다.
그림 3은 레이블이 있는 데이터 개수 변화에 따른 지도학습 및 준지도학습 방법의 반월상 연골 분할의 정성적 결과이다. 레이블이 있는 데이터 22개를 사용하는 nnU-Net은 적은 양의 레이블 데이터로 인해 과소분할이 발생하였고, 더 많은 레이블이 있는 데이터를 사용한 nnU-Net에서는 분할 성능이 개선되는 경향을 보였다. 반면에 MT는 레이블이 없는 데이터를 통해 더 다양한 표현을 고려하여 과소분할이 줄었고, 제안된 방법들을 하나씩 적용하면서 얇고 다양한 형태를 가지는 반월상 연골에 대한 전반적인 분할 성능이 향상되는 결과를 보였다.
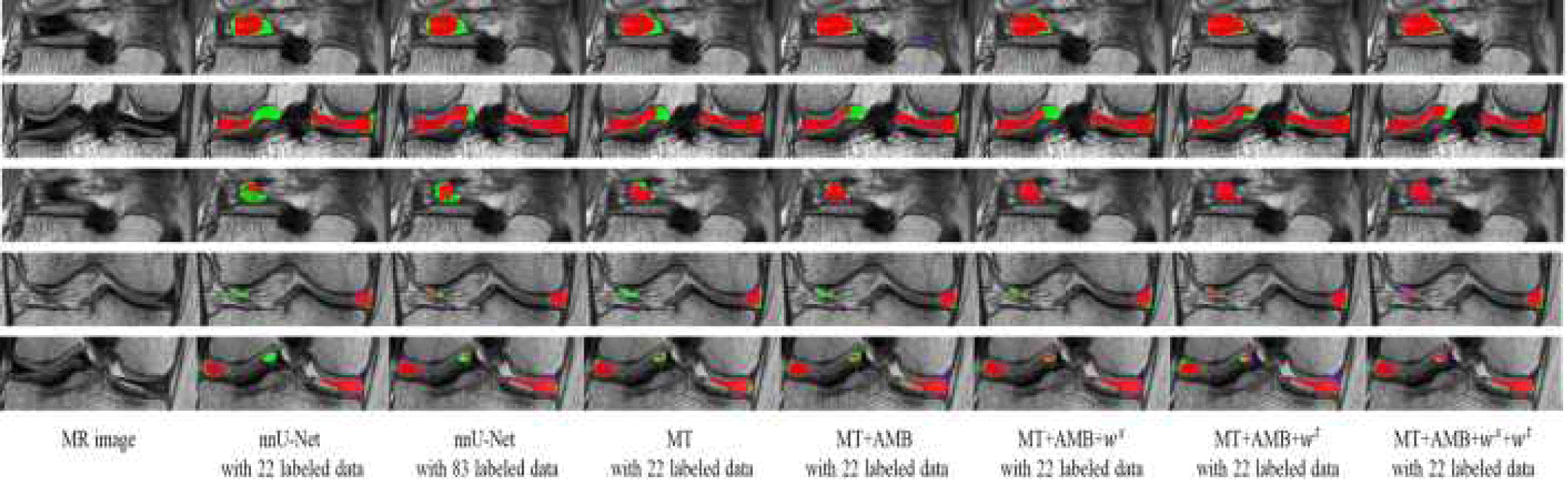
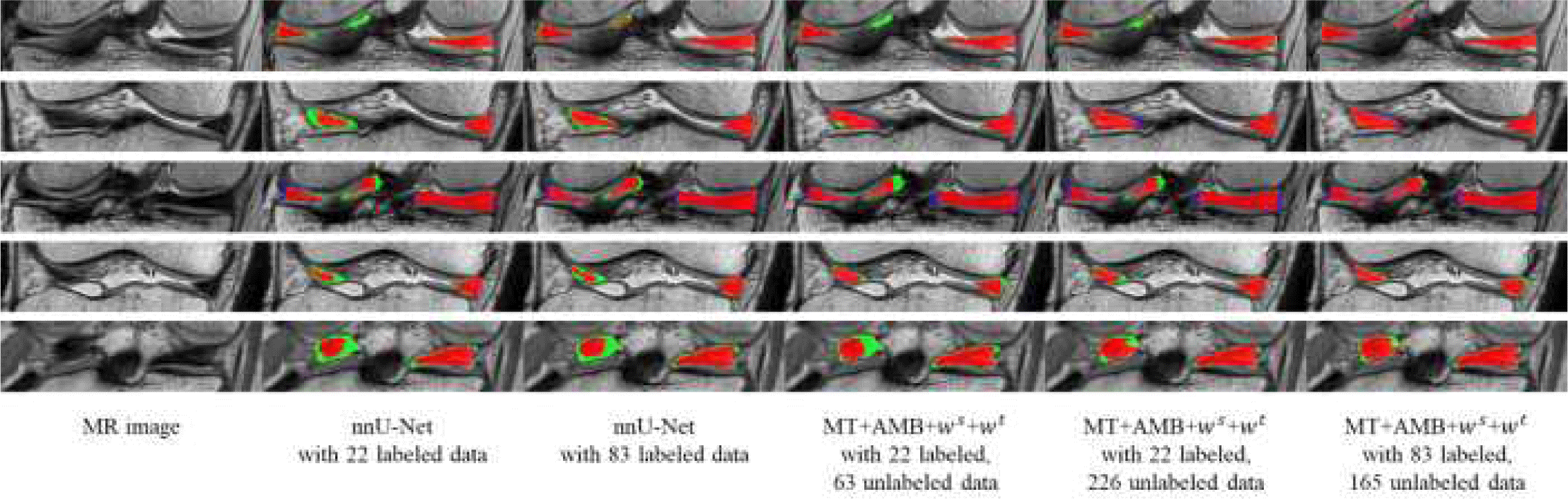
그림 4는 레이블이 있는 데이터와 없는 데이터의 개수 변화에 따른 지도학습 방법과 제안 방법의 반월상 연골 분할의 정성적 결과이다. 레이블이 있는 데이터 22개와 레이블이 없는 데이터 63개를 사용하는 제안 방법은 레이블이 없는 데이터를 추가적으로 고려함으로써 레이블이 있는 데이터만 사용하는 nnU-Net에 비해 과소분할이 개선되었다. 또한, 레이블이 없는 데이터를 226개로 늘려서 훈련한 제안 방법은 과소분할이 개선되었으나 반월상 연골 주변 조직으로 과대분할이 발생했다. 83개로 레이블 데이터를 증가시킨 제안 방법의 경우, 레이블 데이터로부터 정확한 정보를 학습할 수 있어 가장 개선된 분할 결과를 보였다.
4. 결론
본 논문에서는 적은 레이블 데이터 환경에서도 다양한 형태와 얇은 두께를 가지는 반월상 연골을 안정적으로 분할 할 수 있는 준지도학습 모델을 제안하였다. 제안된 방법은 모호성 맵과 분할 성능 및 반월상 연골의 두께를 고려한 손실함수를 적용하여 반월상 연골을 효과적으로 분할하였다. 특히, 잘못 예측할 가능성이 높은 영역을 나타내는 모호성 맵을 활용하여 학생 모델과 교사 모델 간의 일관성을 강화하고, 모델의 정규화를 향상시켰다. 또한, 학습 시 분할이 어려운 사례에 집중하도록 유도하는 분할 난이도 가중치를 적용하여, 다양한 형태로 인해 발생하는 분할 성능 저하 문제를 보완하였으며, 얇은 반월상 연골의 영향력을 증대시키는 두께 가중치를 적용함으로써 클래스 불균형 문제를 완화하였다. 이러한 가중치 전략들은 얇고 형태가 다양한 반월상 연골의 해부학적 특성을 효과적으로 반영함으로써 보다 정밀하고 효율적인 학습을 가능하게 하였다. 추가적으로, 레이블이 있는 데이터와 레이블이 없는 데이터의 양이 모델 학습에 미치는 영향을 분석한 결과, 적은 레이블 데이터 환경에서 레이블이 없는 데이터를 증가시키면 추가적인 정보가 제공됨으로써 모델의 예측 능력이 향상되고, 과소분할 문제가 개선될 수 있음을 알 수 있다. 그러나 레이블 데이터에 비해 지나치게 많은 양의 레이블이 없는 데이터가 제공될 경우, 일부 잘못된 예측이 학습 과정에 반영되면서 정밀도가 하락할 수 있음을 확인하였다. 반면, 레이블 데이터의 양이 증가하면 모델이 보다 정확한 정보를 학습할 수 있어 과소분할과 과대분할이 모두 개선되며, 결과적으로 재현율과 정밀도가 향상됨을 알 수 있다.
본 연구는 단일 장비 및 시퀀스 영상을 사용하여 실험을 수행하였으나, 향후 연구에서는 다양한 제조사의 MRI 장비 및 여러 시퀀스에서 획득한 데이터를 추가적으로 확보하여 제안 모델의 도메인 일반화 성능을 검증하고자 한다. 또한, 제안 모델에서 발생하는 과대분할 문제를 완화하기 위해, 후처리 방법이나 의사 레이블 필터링 방법을 고려하여 레이블이 없는 데이터를 더욱 효과적으로 사용함으로써 오분할을 억제하고 전체적인 학습 안정성과 정밀도를 높이는 방향으로 연구를 확장하고자 한다.


