





1 Introduction
Hand gesture recognition (HGR) has emerged as a pivotal technology for intuitive human-computer interactions (HCI), enabling natural and seamless user experiences across various application domains, including augmented reality (AR), virtual reality (VR), mixed reality (MR), automotive interfaces, and smart home environments. By interpreting human gestures, systems become more responsive and immersive, significantly improving usability and accessibility. Recent advancements in deep learning have significantly advanced the field of human-computer interaction (HCI), particularly through vision-based systems that enable more natural, intuitive interfaces. Convolutional neural networks (CNNs) remain a strong baseline for this task due to their proven ability to extract local spatial hierarchies. Among these, DenseNet-121 stands out for its dense connectivity
pattern, which facilitates feature reuse, mitigates vanishing gradients, and achieves parameter efficiency qualities that are particularly advantageous in recognizing fine-grained gesture differences.
Traditional input devices like keyboards and mice are increasingly being supplemented by gesture-based controls, allowing users to interact with digital environments using body movements. As noted by Sachdeva (2023) [1], the evolution of HCI is marked by a shift from basic graphical interfaces to intelligent systems capable of interpreting gestures, voice, and other non-verbal inputs, driving ongoing innovation in seamless human machine communication.
The proliferation of HGR technologies closely aligns with developments in computer graphics, particularly in rendering realistic, interactive, and responsive environments. Accurate gesture recognition directly enhances graphical user interfaces by facilitating real-time, gesture-driven interactions, thus expanding the horizons of immersive experiences in AR, VR, and MR systems. Advanced HGR can significantly improve user engagement, interaction fidelity, and overall graphical immersion by accurately capturing and interpreting fine-grained gestures in dynamic scenarios. Recent work by Padmakala (2024) [2] further reinforces this by demonstrating how hyperparameter-optimized deep convolutional networks can dramatically improve recognition performance on gesture-rich datasets like HaGRID, highlighting the growing importance of tailored architectures in high-fidelity interaction systems.
A. S. M. Miah (2023) [3] proposed a multi-culture sign language recognition framework using graph-based and deep learning models, emphasizing the importance of robust spatial-temporal feature representation. Their findings reinforce the need for flexible and scalable HGR models applicable across varied linguistic and cultural contexts.
Despite recent progress, substantial challenges persist. Variability in human gestures due to individual differences, environmental conditions, occlusions, and diverse lighting scenarios complicates accurate gesture recognition. Moreover, achieving real-time performance alongside high recognition accuracy remains challenging, particularly on resource-constrained platforms typical in mobile and wearable devices (Kapitanov et al., 2024) [4]. Thus, there is an ongoing need for systematic evaluation and optimization of robust and efficient HGR models.
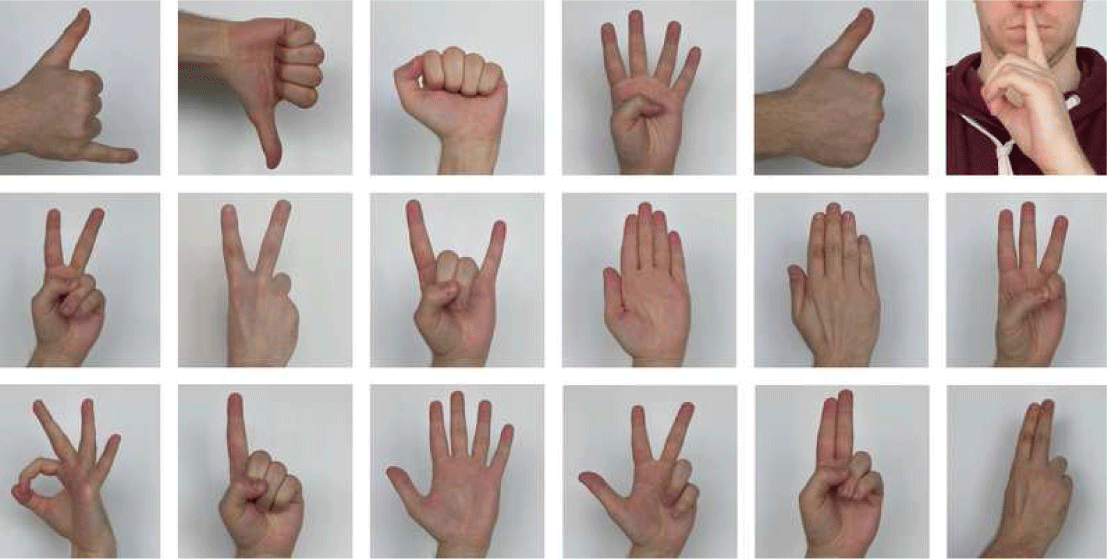
To address these challenges, large-scale, diverse, and annotated datasets are crucial. The HaGRID v2 512px dataset used in this study contains over 1 million images spanning 34 gesture classes, covering a wide range of scenarios and subject variability. Collected from more than 65,000 unique subjects and annotated at high resolution, it is among the most comprehensive publicly available datasets for static hand gesture classification. Table 1 illustrates the distribution of gesture classes in the HaGRID v2 512px dataset, highlighting both class diversity and the imbalance in sample counts. Figure 1 shows the sample gesture images from the HaGRID v2 dataset, representing a diverse range of static hand poses used for interaction in HCI applications. These include single-hand and two-hand gestures, as well as culturally specific and device-control gestures. Leveraging this dataset, researchers can more reliably benchmark advanced neural architectures, exploring deep learning techniques such as convolutional neural networks (CNNs) and Vision Transformers (ViT).
A key technical contribution of this work lies in its detailed interpretability analysis, which goes beyond standard accuracy reporting. By examining confusion matrices in depth, we identify and interpret gesture-level misclassifications, especially between semantically and visually similar gestures (e.g., peace vs peace_inverted, three2 vs three3). This analysis reveals model-specific strengths in fine-grained gesture discrimination, where DenseNet-121 showed better differentiation in certain closely related gestures despite having significantly fewer parameters than ViT-B/16.
In addition, we employed a custom training pipeline that includes learning rate scheduling and class weight balancing, which contributed to stable convergence and improved recognition performance for underrepresented gesture classes. These implementation choices enhanced both sensitivity and specificity, particularly in the presence of class imbalance a common challenge in real-world gesture datasets.
In this study, we present a comparative analysis of two deep learning models for hand gesture recognition: DenseNet-121 (trained from scratch) and ViT-B/16 (fine-tuned from pre-trained weights). Using the HaGRID v2 512px dataset, we evaluate their accuracy and efficiency for real time gesture based interaction in graphics intensive applications. Our findings support the development of gesture-driven interfaces in computer graphics and HCI, offering practical insights for future systems that require both visual and interaction realism.
2. Related Work
Hand gesture recognition (HGR) plays a critical role in advancing natural user interfaces within human-computer interaction (HCI), smart environments, and immersive systems such as augmented and virtual reality. With the increasing need for intuitive and contactless interaction methods, researchers have extensively explored deep learning approaches to improve recognition accuracy, real-time responsiveness, and robustness across diverse environments.
Sharma et al. (2021) [5] proposed a vision-based hand gesture recognition system utilizing deep learning for the interpretation of sign language. Their approach leverages a deep convolutional neural network to extract discriminative spatial features from hand images, enabling effective recognition of complex static sign gestures. The study highlights the capability of CNNs to address variability in hand pose and lighting conditions, supporting robust sign language translation in diverse environments.
Building CNN-based architectures for practical deployment, Sahoo et al. (2022) [6] presented a real-time hand gesture recognition framework using a fine-tuned convolutional neural network. Their method emphasizes rapid and accurate gesture classification, optimized for low-latency scenarios essential in real-time HCI applications. The experimental results confirm that, with suitable fine-tuning and efficient pipeline design, CNNs can deliver high recognition rates without significant computational overhead.
In recent years, transformer-based models have begun to reshape the landscape of gesture and sign language recognition. Hu et al. (2021) [7] introduced SignBERT, a pre-trained transformer model specifically designed to capture hand-model-aware representations for sign language recognition. By focusing on both spatial and temporal cues from video sequences, SignBERT demonstrates superior performance in learning fine-grained gesture dynamics, offering a pathway to improved generalization across users and sign variations.
Montazerin et al. (2023) [8] further advanced transformer-based HGR by proposing a novel model that integrates instantaneous and fused neural decomposition of high-density electromyography (EMG) signals. Their Compact Transformer-based Hand Gesture Recognition (CT-HGR) framework efficiently captures both temporal and spatial dependencies in muscle activity data, outperforming conventional CNNs and classical machine learning methods, particularly for complex and subtle hand motions.
Smith et al. (2023) [9] employed a Deep Convolutional Neural Network (CNN) combined with a novel sterile data augmentation technique, using an FMCW mmWave radar dataset consisting of real and synthetic ("sterile") hand gesture data, achieving an accuracy of 95.4% on static hand gesture classification tasks.
Bristy Chanda(2024) [10] approached a combining semantic segmentation using the U-Net architecture and a score-level fusion of fine-tuned convolutional neural networks (ResNet50 and VGG16) was employed for static hand gesture recognition. The model was evaluated on the National University of Singapore (NUS) hand posture dataset II, which comprises 2000 images equally distributed among 10 gesture classes. Experimental results demonstrated that the proposed method achieved superior performance, reaching an accuracy of 99.92%, outperforming alternative CNN architectures such as VGG16 (99.75%), VGG19 (99.00%), ResNet50 (98.70%), and Inception V3 (96.75%).
Raju et al. (2025) [11] developed a CNN-based real-time static hand gesture recognition system trained on a publicly available static hand gesture image dataset (such as the ASL alphabet dataset), attaining an accuracy of 96.1% and demonstrating effective real-time processing capability at approximately 30 frames per second.
Our work contributes to the ongoing discussion in the field by benchmarking compact deep learning models that maintain reasonable accuracy while being suitable for deployment in resource-limited environments, such as mobile AR systems or embedded smart home controllers.
3. Proposed Method
Hand gesture recognition relies on selecting efficient deep learning architectures. This study compares DenseNet-121 and Vision Transformer (ViT-B/16) for multi-class gesture classification using uniformly preprocessed images resized to 224×224.
Figure 2 shows the architecture used for gesture recognition based on DenseNet-121, a densely connected convolutional neural network. DenseNet mitigates vanishing gradients and promotes better feature reuse by connecting each layer to every other layer in a feed-forward manner. Within a dense block, feature maps from all preceding layers are concatenated, enabling deeper supervision and richer representations.
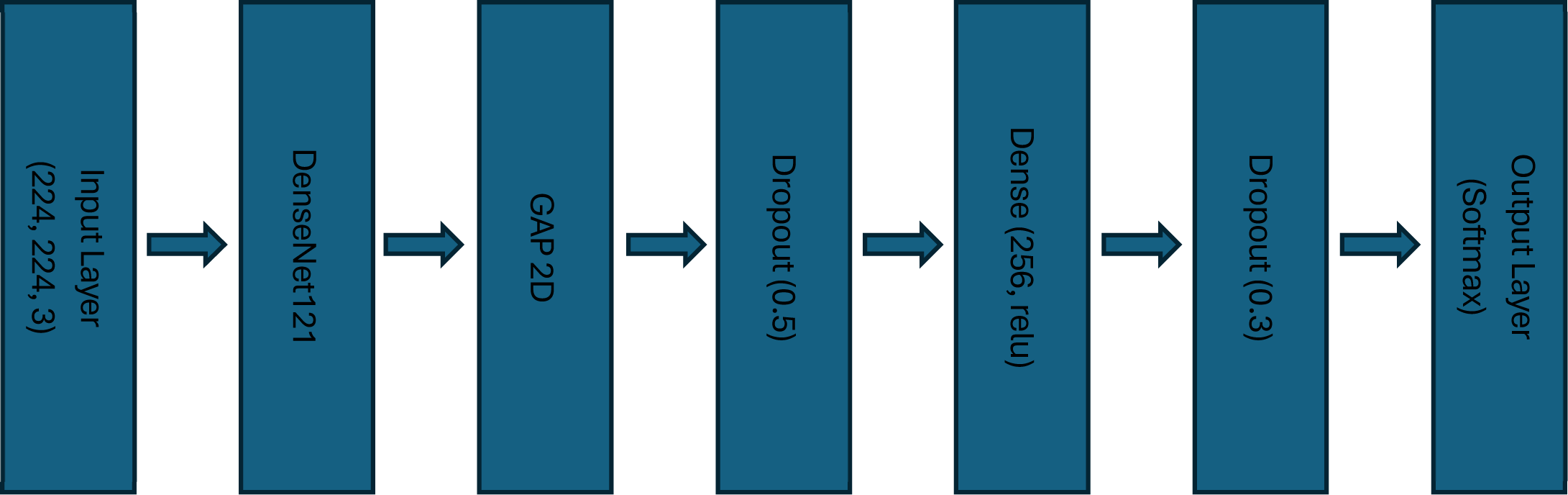
The network begins with a convolutional layer of size 224×224×3, followed by the DenseNet-121 backbone, where feature extraction is performed. The resulting tensor is passed through a Global Average Pooling (GAP) layer to reduce the spatial dimensions. This is followed by a Dropout layer (rate=0.5) to reduce overfitting, then a Dense layer with 256 ReLU-activated neurons, and another Dropout layer (rate=0.3). Finally, the output is mapped to gesture classes using a Dense softmax layer that outputs class probabilities, mathematically described as:
where xl is the output of the l-th layer, [x0,x1,…,xl-1)] denotes the concatenation of feature maps from layers 0 to l-1, and Hl (.) represents a composite function of batch normalization, ReLU activation, and convolution.
The output feature tensor after the final dense block is globally average pooled, resulting in a feature vector z Rd. A fully connected layer projects z onto a C dimensional output, where C is the number of gesture classes. The softmax activation computes the class probabilities:
where wi,bi are the weights and bias for class i.
The model is trained using the categorical cross-entropy loss:
where yi is the true label (one-hot encoded) and pi is the predicted probability for class i.
Optimization is performed with the Adam optimizer, and class weights are used to address imbalance in gesture categories.
Figure 3 depicts the ViT-B/16-based gesture recognition architecture. ViT replaces convolutional layers with self-attention mechanisms, allowing the model to capture both local and global dependencies across the input image.
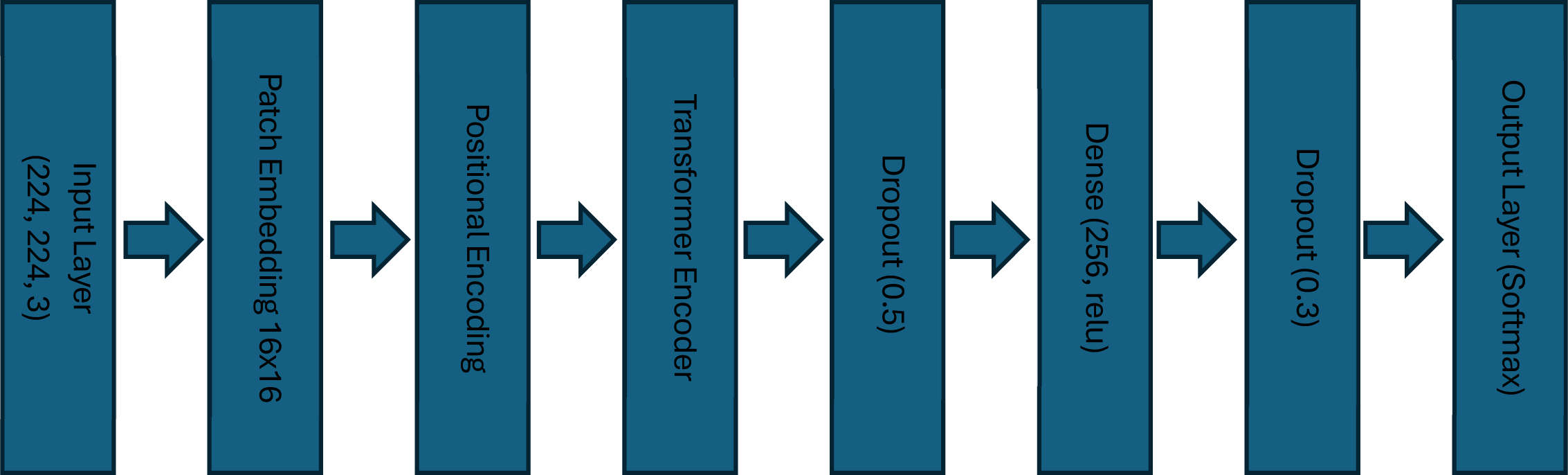
The 224×224×3 input image is split into non-overlapping 16×16 patches, flattened into embeddings with a prepended class token and positional encodings. These are processed through Transformer Encoder blocks containing MHSA and MLP layers with layer normalization and residual connections. The class token output is then passed through a Dense layer (256, ReLU), a Dropout (0.3), and a final softmax layer for classification.
These patch embeddings are combined with a class token and positional encodings to form the input sequence:
where xclass is a class token, represents the ithimage patch, E is the embedding matrix, and Epos is the positional encoding.
The sequence is processed through multiple transformer encoder blocks, each comprising a multi-head self-attention (MHSA) module and a multilayer perceptron (MLP), with residual connections and layer normalization:
where MHSA denotes multi head self attention, LN denotes layer normalization, and MLP is a two-layer feed forward network.
After the final encoder layer, the output corresponding to the class token is passed through a classification head consisting of a dense layer with ReLU and dropout followed by a softmax layer to produce a probability distribution over the C gesture classes:
where is the class token output of the final transformer layer, and wi,biare the weights and bias associated with class i.
The model is trained using the categorical cross-entropy loss,
where yi is the ground-truth label. Training is performed using the Adam optimizer with early stopping and learning rate scheduling. Identical data augmentation, preprocessing, and evaluation protocols are used for both the DenseNet-121 and ViT-B/16 models to ensure a fair and direct comparison.
The ViT-B/16 model leverages self-attention to capture long-range spatial dependencies, making it effective for distinguishing gestures with similar local features but different global structures. By comparing it with DenseNet-121’s localized feature extraction, the study highlights the trade-offs and strengths of both architectures in static gesture recognition.
4. Training and Validation Process
To ensure a fair comparison, both DenseNet-121 and ViT-B/16 were trained under identical conditions on the HaGRID v2 512px dataset, split into 70% training and 30% testing, with 10% of the training data reserved for validation. Stratified sampling preserved class distributions. All images were resized to 224×224 and normalized to [0,1]. Identical augmentations horizontal flips, brightness adjustments, and zooming were applied to improve generalization.
Both models were trained using the Adam optimizer (learning rate 1×10 −4, batch size 32) with categorical cross-entropy loss, early stopping (patience=2), and learning rate reduction (factor = 0.5). Class imbalance was addressed through weighted losses. Experiments were conducted on an Intel Core i9 CPU with 64GB RAM and an NVIDIA RTX 4090 Graphics Card (24GB). DenseNet-121 trained from scratch for 5 epochs (≈5 hours), while ViT-B/16 was fine-tuned for 6 epochs (≈6.5 hours) from ImageNet-21k weights, with all transformer layers unfrozen to adapt fully to the gesture data. Both models employed dropout (0.5 and 0.3) to minimize overfitting. DenseNet-121 and ViT-B/16 have about 8 million and 86 million parameters, respectively, with complexities of roughly 2.8 and 17.5 GFLOPS for 224×224 inputs (Dosovitskiy et al., 2021) [12] [13].
Figures 4 and 5 show training and validation loss and accuracy curves.
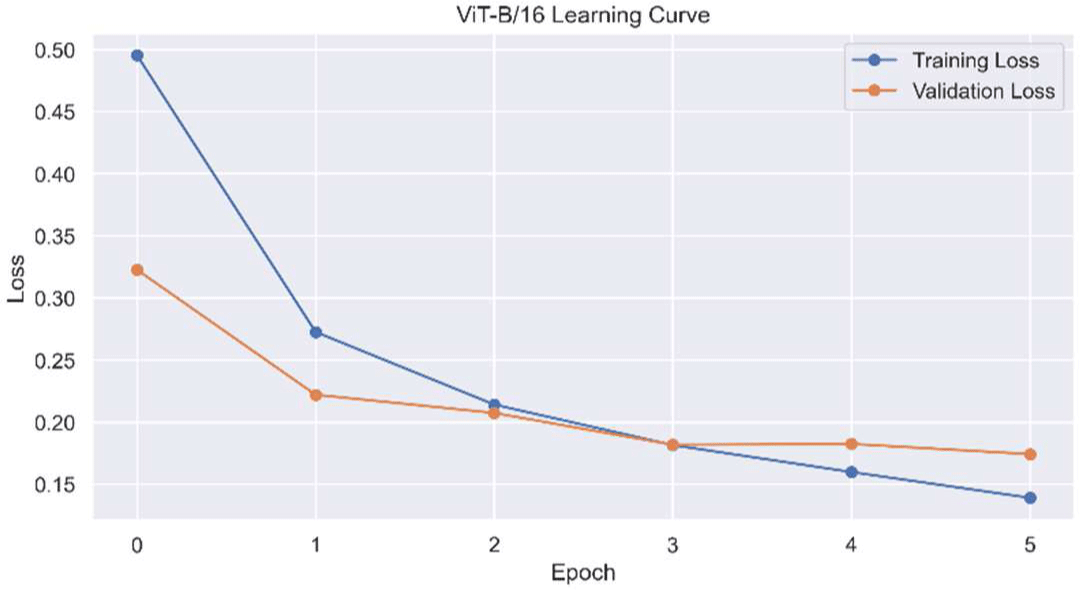
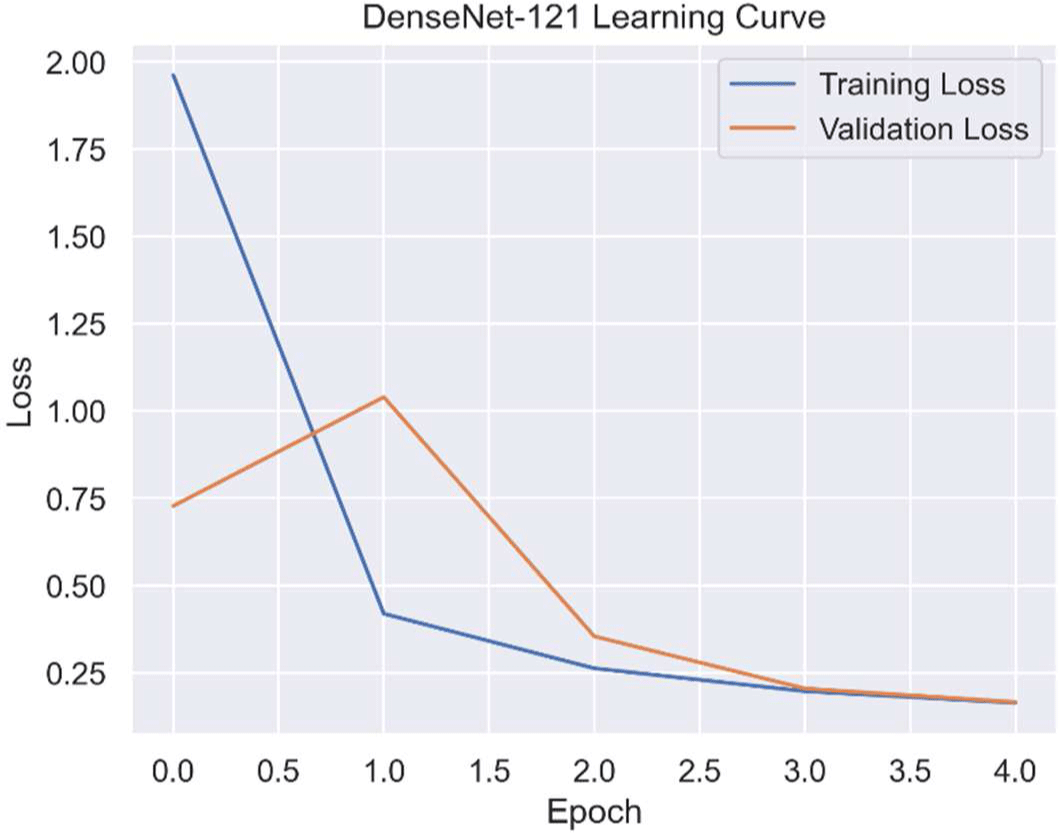
DenseNet-121 converged rapidly, stabilizing by epoch three, while ViT-B/16 improved more gradually, reaching slightly better validation performance with minimal overfitting. These trends confirm effective convergence and generalization under the shared setup.
5. Experiments and Results
The trained DenseNet-121 and Vision Transformer (ViT-B/16) models were evaluated on the test set from HaGRID v2 512px dataset under identical experimental conditions. Comprehensive performance metrics including classification accuracy, sensitivity, specificity, and confusion patterns were analyzed to assess their comparative effectiveness for gesture recognition.
The Vision Transformer achieved a final test accuracy of 95.45% and validation accuracy of 94.71% after 6 epochs. In contrast, DenseNet-121 achieved a test accuracy of 95.32% and a higher validation accuracy of 94.98% after 5 epochs. While the overall performance of both models is comparable, ViT-B/16 exhibited slightly higher test accuracy, while DenseNet generalized slightly better on the validation set.
To better understand class-wise behavior, we computed sensitivity (recall) and specificity for each class. The Vision Transformer achieved a macro-average sensitivity of 0.945 and specificity of 0.998, whereas DenseNet-121 slightly outperformed with a macro-average sensitivity of 0.950 and the same specificity of 0.998. This suggests that while ViT-B/16 attained higher overall classification accuracy, DenseNet-121 was slightly more consistent in detecting true positives across all gesture classes.
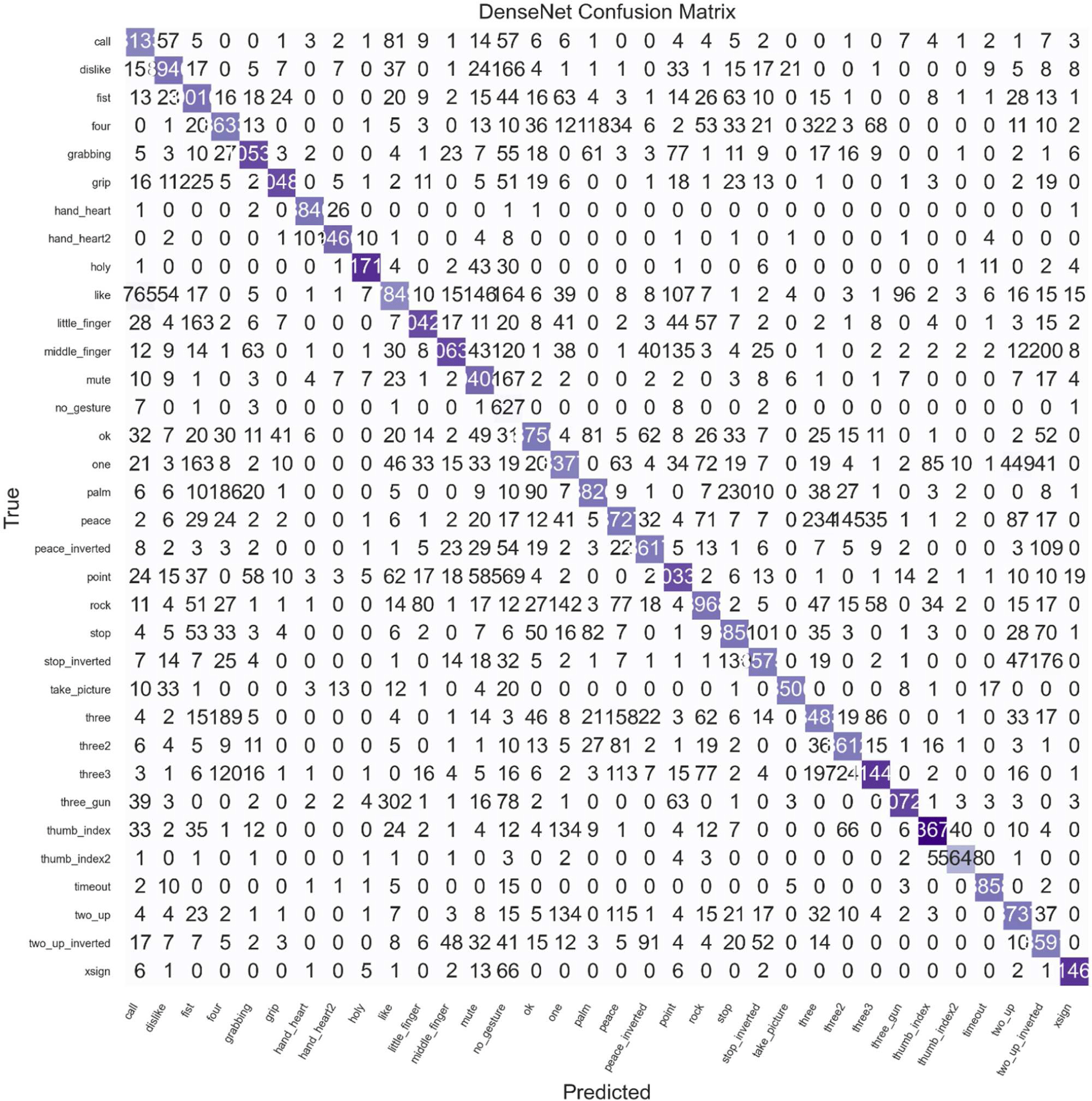
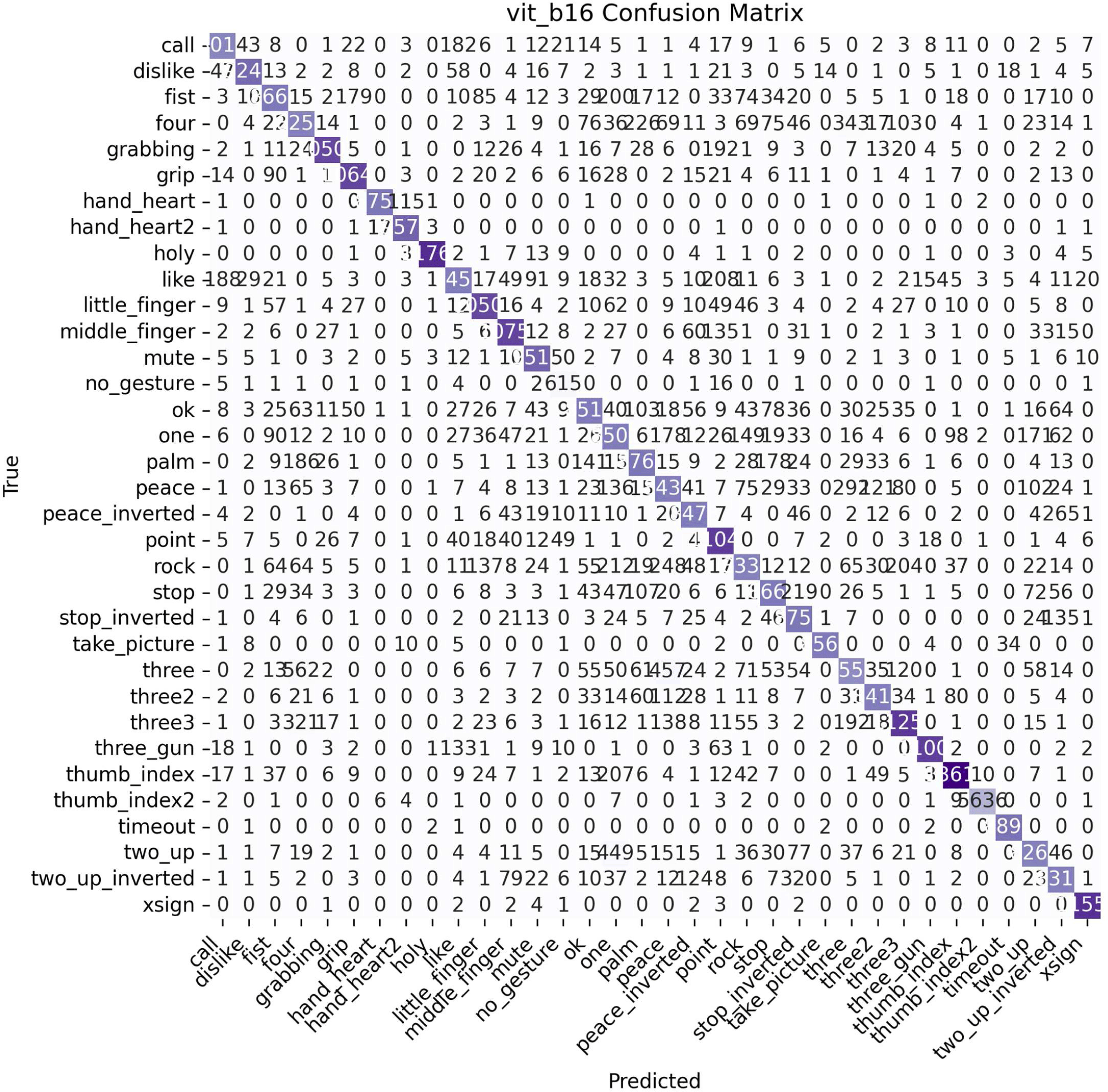
Figures 6 and 7 present the confusion matrices for DenseNet-121 and ViT-B/16. To improve interpretability, we highlight that most misclassifications occur between visually or semantically similar gestures. For instance, both models showed some confusion between peace and peace_inverted, as well as between three2 and three3, likely due to their similar hand configurations. However, the DenseNet model demonstrated slightly lower confusion between these gesture pairs compared to ViT-B/16, indicating better fine-grained discrimination despite ViT-B/16’s marginally higher overall classification accuracy. Additionally, both models exhibit strong diagonal dominance across classes, signifying high per-class accuracy. This aligns with their reported high sensitivity (≥0.945) and specificity (~0.998), as true positives are concentrated along the diagonal and false positives are minimal across columns. The clear separation of class predictions in the confusion matrices supports the models’ robustness in distinguishing gestures, with few ambiguous misclassifications overall.
6. Conclusion
In this study, we presented a comparative evaluation of two state-of-the-art deep learning architectures DenseNet-121 and Vision Transformer (ViT-B/16) for static hand gesture recognition using the large-scale HaGRID v2 dataset. Both models were trained under identical conditions, ensuring a fair assessment of their classification performance, generalization ability, and robustness across 34 gesture categories.
Our results demonstrated that the Vision Transformer achieved a slightly higher test accuracy of 95.45%, while DenseNet-121 maintained a better macro sensitivity of 0.950. Despite the performance similarity, the two models showed complementary strengths: ViT-B/16 exhibited superior capability in capturing global visual dependencies, while DenseNet-121 provided more balanced recognition across all gesture classes and required fewer computational resources.
The learning curves and confusion matrices validated the effectiveness of both models in minimizing overfitting and achieving stable convergence. Importantly, our evaluation highlights that high-performing hand gesture recognition can be achieved not only through advanced attention-based models but also through compact, efficiently structured CNNs like DenseNet when properly tuned and regularized.
In addition to reporting high accuracy, future work will incorporate statistical validation methods such as paired t-tests to evaluate whether performance differences between models are statistically significant. This would provide a more rigorous comparison and strengthen the credibility of the results beyond simple performance metrics.
This work contributes to the growing body of research at the intersection of gesture recognition and human-computer interaction, providing insights into model selection for real-time, vision-based interface systems. Future work may explore the integration of temporal modeling for dynamic gestures, multi-modal fusion with depth or skeletal data, and deployment optimization on mobile or embedded platforms.

