





1. 서론
최근 인공지능(AI) 기술은 비약적인 발전을 거듭하며 다양한 산업 분야에 도입되고 있다. 특히 GPT(Generative Pre-trained Transformer)기반으로 개발된 ChatGPT의 등장은 AI 기술의 발전에 있어 중요한 변화를 이끌어 내고 있다. ChatGPT는 대규모 사전 학습을 통해 자연어를 처리할 수 있는 능력을 갖춘 모델로, 대화형 AI형태로 서비스를 제공한다[1]. 초기에는 텍스트 생성 및 이해에 그쳤으나, 이미지 분석과 생성, 그리고 동영상 생성까지 기술적 범위를 확장하고 있으며 이에 따른 다양한 AI 서비스가 등장하고 있다. 이러한 흐름 속에서 AI는 자료 요약, 데이터 분석, 프로그래밍 등 다양한 작업의 효율성을 높이며, 생활, 의료, 산업 등 여러 분야에 적용하기 위한 연구가 진행중이다[2][3]. 교육 분야에서도 AI 기술의 도입은 이루어지고 있지만, 현재까지의 대부분의 활용 사례는 학습 방향을 잡아주거나 진로를 컨설팅 하는 역할에 머무르고 있다. 즉, 학습자의 학습 그 자체를 돕는 도구로서 AI를 직접적으로 활용하는 시도는 상대적으로 부족하다[4].
수동으로 제작되는 학습용 물리 콘텐츠의 경우, 기존에는 사용자가 문제의 조건을 직접 해석하고, 파라미터를 수동으로 입력하여 시뮬레이터를 생성하고 실행해야 하는 번거로움이 있었다. 이 과정에서 사용자가 문제를 제대로 이해하지 못하면 시뮬레이터의 설정이나 결과 해석에 오류가 발생할 수 있어 학습 효율 저하가 될 우려가 있다. 본 연구는 이러한 한계를 극복하기 위해 GPT API를 활용한 학습용 물리 시뮬레이터 자동 생성 시스템을 제안한다. 제안된 시스템은 직선운동 문제 사례에 한정한 물리 문제의 이미지를 GPT API를 통해 분석하고, 문제 이해를 바탕으로 시뮬레이터 생성에 필요한 핵심 파라미터를 자동으로 생성한다. 생성된 파라메터는 미리 제작된 3D 모델링 데이터에 자동으로 적용되며 이를 통해 사용자는 별도의 파라미터 설정 없이도 즉각적으로 실시간 3D 학습용 콘텐츠를 구동 할 수 있다. 더 나아가 학습자가 문제를 해석하는 초기 단계에서의 오류를 방지하고 학습 효율성을 높일 것으로 기대된다. 완성된 시뮬레이터는 실시간 3D 콘텐츠 형태이며 이러한 형태는 문제에 설정된 수치를 변화시켜 가면 학습 이해도를 높이는 등의 목적으로 활용될 수 있다.
2. 선행 연구
생성형 인공지능은 등장 이후 교육 분야 전반에서 빠르게 적용되고 있다. 수업 준비, 학습 활동, 평가에 이르기까지 교사와 학습자의 역할을 보조하거나 확장할 수 있는 결과물을 생성해 주기 때문이다.
교육 현장에서 ChatGPT를 활용하는 주요 방식 중 하나는 수업 설계의 보조 도구로 활용하는 것이다. 기존에는 교사가 일일이 구상하던 수업 내용이나 문제 제작 과정이 생성형 AI를 통해 자동화 및 고도화되면서 업무 부담을 줄일 수 있다. 예컨대, 중등 영어 교사들을 대상으로 한 연수에서는 ChatGPT가 수능형 문항의 지문 생성, 어휘 난이도 조절, 보기에 대한 구조화 등에서 효과적으로 활용되었으며, 참가자들 대부분이 문항 개발의 질적, 양적 향상에 긍정적인 반응을 보였다는 연구결과가 있다[5].
교사 대상의 교육에서도 수업지도안 작성을 위한 협업 과정에 ChatGPT를 도입한 사례가 존재한다. AI가 단순한 도우미를 넘어 협력적 피드백을 제공하는 일종의 동료 교사 역할을 수행했다. 특히 협업 수준이 높을수록 수업 내용의 구조나 논리 흐름이 더욱 정교화되는 경향이 뚜렷하게 나타났으며, 이는 교사의 교육 설계 능력을 향상시킬 수 있다는 연구가 진행되었다[6].
수업 실행 단계에서의 활용을 위한 학생의 학습 몰입도와 맞춤형 피드백 제공을 가능하게 하는 AI 기반 학습 플랫폼에 대한 연구도 진행되었다. 초등학생 대상 영어 수업에 ChatGPT API를 기반으로 개발된 웹 애플리케이션을 도입한 사례에서는, 학생 개개인의 수준에 맞춘 실시간 피드백과 콘텐츠 제공이 이루어졌으며, 결과적으로 학습자 반응성과 교사 만족도 모두에서 긍정적 효과가 확인되었다[7].
고등 과학 교과에서는 ChatGPT의 문제 해결 능력과 그 한계를 검증하려는 연구들이 이루어지고 있다. 대학 수준의 일반물리학 문제를 제시했을 때, 최신 인공지능 모델들은 높은 정답률을 기록하며 개념 이해와 수치 계산에서 우수한 성과를 보였다. 그러나 설명 과정이나 응답 구조에서 여전히 확률적 오류가 나타나기도 하였으며, 이는 AI가 제공하는 해답이 언제나 완전하거나 교육적으로 적합하진 않다는 점을 시사한다[8][9].
학생 평가에 ChatGPT를 적용한 시도도 이루어졌다. 특히 과학 교과의 서술형 문항 채점 과정에 활용되었을 때, AI가 제시한 기준과 모범답안은 일정 수준에서 적절성을 보였지만, 교사 채점 결과와의 일관성은 복잡한 문항일수록 낮아지는 경향을 보였다. 이는 채점 보조 도구로는 활용이 가능하나, 독립적인 평가 판단을 맡기기엔 아직 이르다는 연구가 이루어졌다[10].
AI 기반으로 생성된 학습 도구의 수용 가능성은 기술수용모델(TAM)을 통해 분석되기도 했다. 인지된 유용성, 사용 용이성, 그리고 학습 중 몰입 경험은 ChatGPT에 대한 긍정적 태도와 실제 활용 의도에 유의미한 영향을 미치는 요소로 확인되었으며, 이는 교사나 학습자가 단순히 기술을 이해하는 수준을 넘어 심리적 신뢰감과 효용성을 경험할 때 비로소 기술 채택이 일어남을 의미한다[11].
생성형 AI는 수업 설계 지원 도구와 학습 보조 매체로 양분되어 다양한 교과에 적용되고 있다. 국내에서는 초중등 중심, 국외에서는 대학 중심으로 연구가 진행되고 있으며, AI 활용의 인지 수준 역시 단순 정보 검색에서 창의적 사고 유도까지 폭넓게 확장되고 있다. 하지만 교사의 지도 없이 AI에만 의존할 경우, 학습자의 고차사고 발달이 제한될 수 있다는 점도 지속적으로 제기되고 있다[12].
현장의 실제 목소리를 반영한 실천적 접근도 존재한다. 교사, 학생, 학부모를 대상으로 생성형 AI에 대한 인식을 조사한 결과, 대부분이 이 기술이 미래 교육의 유연성 향상과 정보 활용 역량 강화에 기여할 것으로 기대하고 있으며, 특히 교사의 수업 준비 및 학생의 자기주도학습 도구로서의 유용성이 강조되었다[4].
이처럼 교육 현장에서 생성형 AI가 빠르게 도입되고 있는 흐름은, 단순한 기술 도입을 넘어 우리 사회 전반에 생성형 AI 가 미치는 영향력이 크게 증가하고 있음을 보여준다. AI 기술은 교육 분야만이 아니라 산업, 미디어, 일상생활 등 다양한 분야에 걸쳐 인간의 역할과 판단, 그리고 가치 평가의 기준에 영향을 미치며 기존의 틀을 변화시키고 있다. 따라서 교육 분야에서의 AI 활용 논의는 단지 기술의 효율성이나 활용 가능성에 국한되지 않고, 교육의 철학적 방향, 공정성, 학습자의 권리와 같은 근본적인 가치와 함께 논의되어야 한다[13].
앞서 살펴본 바와 같이 다양한 선행연구들은 생성형 인공지능, 특히 ChatGPT가 수업 설계, 학습 활동, 평가 보조 등 교육의 여러 영역에서 일정 수준 이상의 효용성을 지니고 있음을 보여준다. 다만 대부분의 연구가 언어 기반의 콘텐츠 생성이나 문항 설계, 혹은 피드백 제공에 초점을 맞추고 있으며, 비언어적이고 추상적인 개념이 포함된 과학, 수학 등의 영역에서 ChatGPT가 어떻게 학습자의 개념 이해를 도울 수 있는지에 대한 실질적 접근은 아직 미흡한 실정이다. 특히 물리학과 같은 교과에서는 공식, 변수, 조건의 조합에 따라 문제 이해가 크게 달라지며, 학습자의 사고 과정 역시 시각적이고 절차적인 시뮬레이션을 필요로 하는 경우가 많다. 이러한 특성에도 불구하고, 현재까지의 생성형 AI 활용 연구는 물리학 문제를 보다 쉽게 구조화하거나, 문제 풀이 과정을 시각적으로 안내하는 데 직접적으로 적용된 사례가 거의 없는 실정이다.
본 연구는 ChatGPT를 활용하여 사용자가 입력한 물리학 문제로부터 핵심 파라미터를 추출하고, 이를 기반으로 상호작용 가능한 3D 시뮬레이터에 연동되는 구조화된 데이터를 자동 생성하여 콘텐츠를 만들어 주는 시스템을 제안한다. 이 콘텐츠를 통해 학습자가 문제 상황을 시각적으로 이해하고, 직관적 사고를 통해 문제 해결 전략을 구성할 수 있도록 도움을 줄 수 있다. 이러한 접근은 단순한 콘텐츠 생성에 그치지 않고, 언어 기반 AI와 시뮬레이션 기반 학습 도구의 융합을 통해 생성형 AI의 활용 영역을 새로운 방식으로 확장하는 시도로서, 물리 교육에 있어 ChatGPT의 실질적 활용 가능성을 한층 더 구체화하는 데 기여할 수 있을 것이다.
3. 시뮬레이션 생성 구조
본 연구에서 구현한 시뮬레이션 생성 시스템은 언리얼 엔진 5.3을 기반으로 제작되었으며, 전체 흐름은 Figure 3와 같다. 시뮬레이션 생성 과정은 다음과 같은 단계로 이루어진다. 먼저 GPT API Thread의 유효성을 검증한 후, 문제 이미지를 분석하고 문제 설명 텍스트를 추출한다. 추출된 텍스트는 Assistant에 메시지로 추가되고, Assistant는 이를 기반으로 시뮬레이션 파라미터를 생성한다.
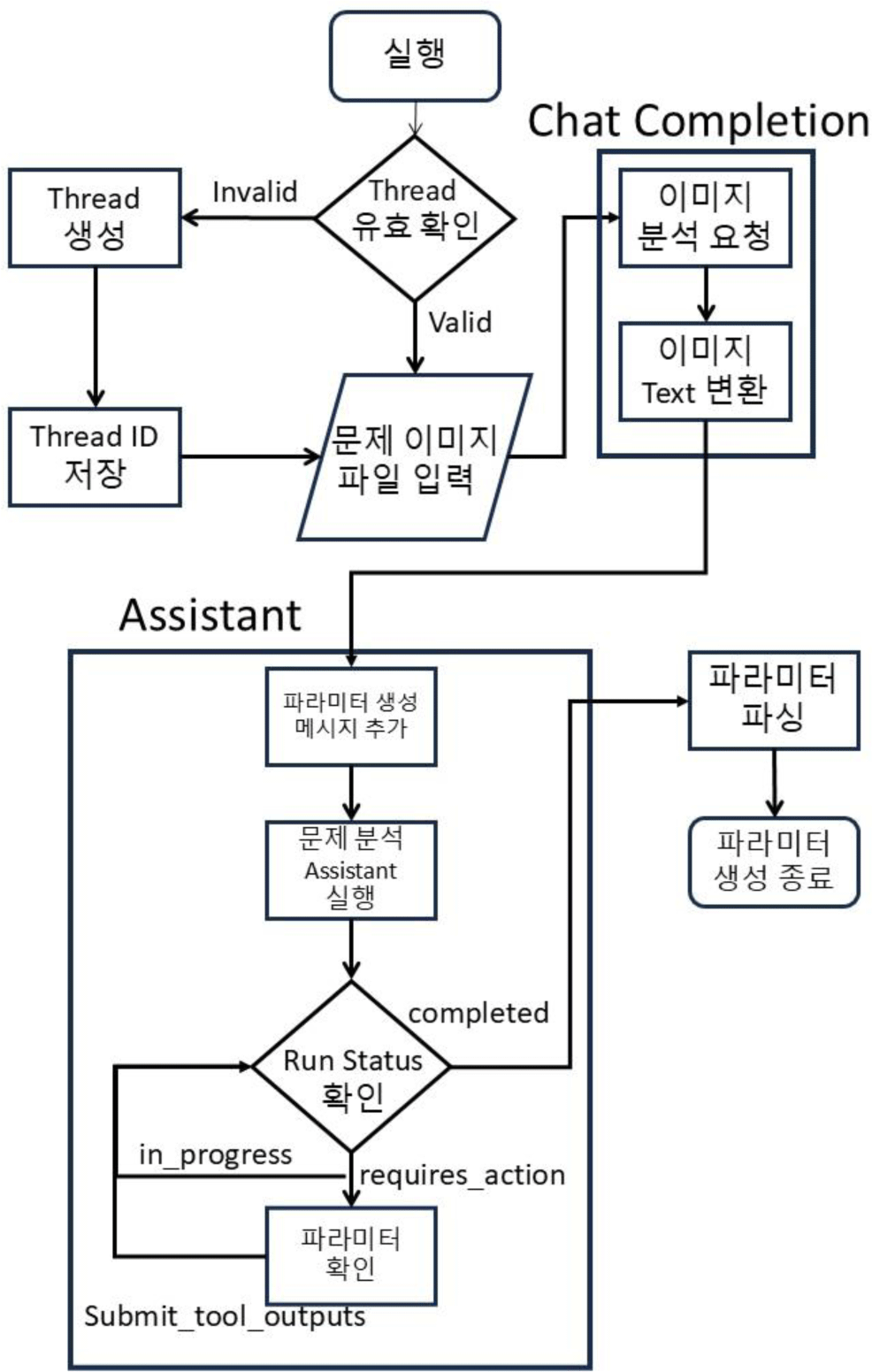
Assistant 기능은 대화 상태를 유지하기 위해 Thread를 기반으로 동작한다. 시뮬레이션 파라미터 생성의 첫 단계는 이 Thread의 유효성을 검증하는 것이다. 유효성 검증은 GET 방식으로http://api.openai.com/v1/threads/THREAD_ID에 요청을 보내 응답 코드가 200이면 Thread가 유효하며, 404이면 새로운 Thread를 생성해야 한다. 새 Thread 생성은 POST 방식으로 http://api.openai.com/v1/threads에 요청을 보내며, 응답에서 반환된 Thread ID를 후속 단계에서 사용한다.
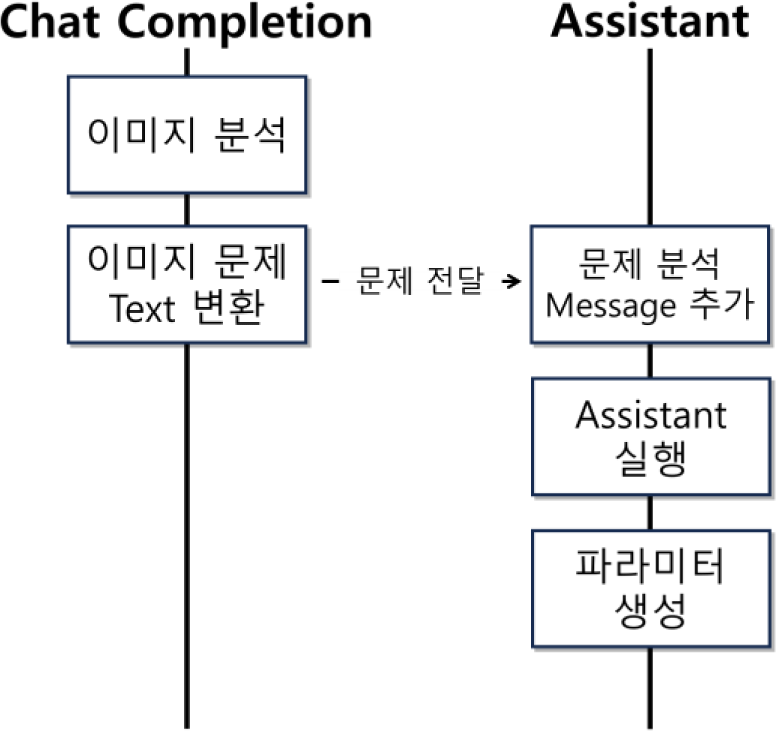
유효한 Thread가 준비되면, GPT API의 Chat Completion 기능을 통해 문제 이미지를 분석하고 문제 설명 텍스트를 추출한다. 요청은 Post 방식으로 http://api.openai.com/v1/chat/completion에 요청을 전송해야 하며, 이미지 파일을 포함한 메시지를 전달한다. 이미지는 첨부될 때 사용자 메시지의 content 필드에 텍스트와 이미지가 혼합된 형태의 JSON 객체 배열로 작성된다. 이미지 객체는 type과 image_url로 구성되며 각각 스트링 필드와 오브젝트 필드이다. type은 “image_url”이다. image_url 필드는 data:<mime>;base64,<image>형태의 Data URL이다. image 부분에 Base64로 인코딩한 이미지 데이터를 넣고 확장자에 따라 “image/<mime>”을 mime부분에 넣는다. 만들어진 객체를 메시지의 content 필드에 삽입하여 응답 생성을 요청한다. 요청 처리 완료 후, 사전에 바인딩된 콜백 함수가 호출되고 문제 텍스트가 응답으로 반환된다. 반환된 텍스트는 이후 Assistant에 전달되어 시뮬레이션 파라미터 생성의 입력으로 사용된다.
Figure 2는 Assistant 기반 시뮬레이션 파라미터 생성 흐름을 구체적으로 보여준다. Chat Completion과 달리 Assistant는 단일 요청으로 응답을 생성하지 않고, 메시지 추가, 실행, 응답 생성 등 다단계 요청과 응답 과정을 거친다.
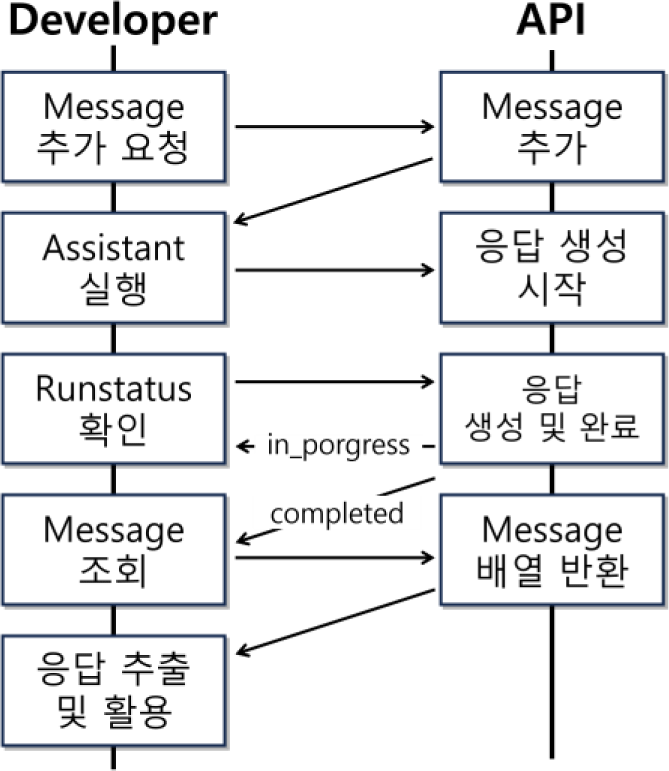
먼저, 문제 텍스트를 POST 방식으로 http://api.openai.com/v1/threads/THREAD_ID/messages에 요청해 추가한다. 이때 메시지의 role은 user로 설정하고 content에 문제 설명 텍스트를 입력한다. file_ids는 참조할 업로드 된 파일 ID를 지정할 수 있으나, 본 연구에서는 Chat Completion에서 이미지 분석을 처리했고 Fine-tuning의 경우 이미지 처리의 기능은 지원되지 않기 때문에 생략한다.
메시지 추가 후, Assistant 실행을 위해 Post 방식으로 http://api.openai.com/v1/threads/THREAD_ID/runs에 요청을 보내고 응답에서 run_id를 받는다. Assistant는 메시지 리스트 내 모든 메시지를 참고하여 응답을 생성한다. 이후 http://api.openai.com/v1/threads/THREAD_ID/runs/RUN_ID에 Get 방식으로 요청하여 생성 상태를 확인한다. 본 연구에서는 completed, in_progress, requires_action 세 가지 상태를 처리하도록 구현하였다.
Table 1 은 사용하는 각 Run status의 설명이다. 그중 requires_action상태는 앞서 설명한 Function 기능이 호출된 상태로 이 때 구조화된 파라미터가 반환되며, 이어서 응답을 생성하기 위해서 요청이 필요하다. http://api.openai.com/v1/threads/THREAD_ID/runs/RUN_ID/submit_tool_outputs 에POST 방식으로 tool_call_id(requires_action 응답에 포함)와 output을 전달하면 GPT가 Function 호출 결과를 반영해 응답을 생성한다. 이 단계에서 실질적으로 시뮬레이션 생성에 필요한 파라미터가 도출되어 역할이 끝나며 output엔 Success 문자열을 포함시켜 작업이 끝났음을 알리고, 이후 run 상태가 completed로 전환되면 전체 시뮬레이션 생성 과정이 종료된다. 전 과정은 비동기 처리를 통해 사용자 경험을 유지하면서 진행된다.
| 상태 | 설명 |
|---|---|
| completed | 답변의 생성이 완전히 끝난 상태. |
| in_progress | 답변이 생성 중인 상태 |
| requires_action | 호출되어 사용자의 응답을 기다리는 상태 |
4. ChatGPT API
ChatGPT API는 자연어 처리, 이미지 분석, 텍스트 생성 등 다양한 작업을 손쉽게 수행할 수 있도록 제공되는 인터페이스이다.[4] 본 연구에서는 언리얼 엔진 내부에서 HTTP 요청을 통해 GPT API와 연동하였으며, 생성 방식은 Chat Completion과 Assistant 방식 두 가지를 병행하여 활용하였다.
Chat Completion 방식은 매 요청마다 독립적인 메시지 리스트를 서버에 전달하여 응답을 생성하는 구조이다. 사용자는 시스템 메시지(프롬프트)와 사용자 메시지를 리스트로 구성하고, 이 리스트를 context로 하여 서버에 요청한다. 서버는 이전 대화 기록을 저장하지 않고 매번 새로운 context만을 참고하여 응답을 생성한다. 따라서 일관된 분석을 위해 매 요청 시 시스템 메시지를 함께 포함시켜야 한다.
본 연구에서는 문제 이미지 분석 단계에서 Chat Completion 방식을 채택하였다. 이유는 Assistant와 달리, 이전 메시지의 영향을 받지 않기 때문에 이미지 기반 문제 분석의 정확성을 유지할 수 있기 때문이다. 실제 실험에서도 Assistant를 사용한 경우 Thread에 쌓인 이전 메시지로 인해 분석 결과가 정확하지 않는 문제가 발생했다. 반면, Chat Completion은 독립된 요청 구조 덕분에 문제 텍스트 추출의 정확성이 높게 유지되었다.
Assistant 방식은 서버 측에서 context을 유지하는 Thread 기반 대화 관리 기능을 제공한다. Thread는 메시지를 저장하는 컨테이너이며, 여러 메시지를 묶어 하나의 context를 형성한다. 각 메시지는 role, content로 구성되며, 필요하다면 추가로 파일을 업로드하여 file_ids를 추가할 수 있다. Assistant는 Runs 요청을 받으면 Thread 내 context를 기반으로 응답을 생성하여 Thread에 메시지를 추가하고 사용자는 추가된 메시지를 확인하여 답변을 확인할 수 있다. 이로 인해 사용자와의 상호작용이 지속적이고 일관된 상태로 이어질 수 있으며, 복잡한 문제 처리 및 다단계 요청 처리에 적합하다.
본 연구에서는 Assistant를 물리 문제 분석 후 시뮬레이터 생성 파라미터를 추출하는 역할에 활용하였다. Figure 3에서처럼 이미지 분석 단계를 거쳐 추출된 문제 텍스트를 Assistant의 Thread에 입력 메시지로 전달하여 실행하면, Assistant는 해당 문제를 분석하고 시뮬레이터 생성에 필요한 파라미터(예: 속도, 가속도, 위치 등)를 자동으로 도출한다. 이러한 파라미터는 시뮬레이터 생성 함수에 직접 전달해 객체들을 생성할 수 있다.
Function 기능은 파라미터 생성에 필요한 핵심 기능으로 Assistant가 단순한 텍스트 응답을 넘어, 호출한 기능(Function)을 통해 구조화된 데이터를 반환하거나 외부 처리 흐름을 연결할 수 있도록 한다. 이를 통해 문제 분석 단계에서 추출된 파라미터를 명확히 구조화하고, 시뮬레이터 생성 엔진과의 연계가 용이하도록 할 수 있다.
Function 기능의 기본 개념은, 사용자가 GPT에 "이 문제의 조건을 분석하고 필요한 파라미터를 반환해라"라는 요청을 했을 때, GPT가 단순히 텍스트 설명을 생성하는 대신, 주어진 함수의 정의(스키마)에 맞게 호출 제안을 응답으로 생성한다. 사용자는 Assistant 생성 때 Function 호출을 위해 함수의 정의를 Assistant에 등록하며, 이 정의에는 호출할 함수 이름, 입력 파라미터 형식 등이 포함된다. GPT는 context와 함수의 정의를 바탕으로 해당 함수의 호출 제안을 생성하고, 사용자는 이 제안을 바탕으로 실제 함수를 호출하거나 외부 API를 이용하는 등 결과를 처리할 수 있다. GPT 자체가 함수 호출을 실행하거나 결과를 반환하지는 않지만, 구조화된 데이터 출력을 위한 중간 역할을 수행한다. 이 기능을 사용하지 않았을 경우 데이터 전 후에 부연 설명이 추가되거나 정확한 값이 필요한 부분에 변수로 대체하는 등의 문제가 있으나 구조화된 데이터 출력으로 이 문제를 완벽하게 보완하여 시뮬레이터 생성의 핵심 기능의 역할을 수행한다.
Figure 4는 Function으로 반환된 응답의 JSON 구조를 보여준다. 반환된 JSON을 이용해 사용할 수 있는 형태의 데이터로 가공하여 시뮬레이터 객체 생성에 사용한다.

GPT 및 기타 대규모 언어 모델(LLM)의 성능은 주로 대규모 범용 데이터셋에 기반한 사전 학습(Pre-training)을 통해 확보된다. 그러나 이러한 범용 모델은 특정 도메인이나 문제 유형에 대한 최적화가 부족할 수 있으며, 특정 작업(예: 특정 유형의 문제 파라미터 추출)에서 정확성과 일관성을 높이기 위해 추가적인 학습 단계가 필요하다. 이때 적용되는 것이 바로 Fine-tuning(미세조정)이다.
Fine-tuning은 사전 학습된 LLM에 대해 특정 목적의 데이터셋을 추가 학습시켜, 모델의 파라미터를 미세하게 조정하는 과정이다. 이 과정을 통해 모델은 특정 도메인, 특정 데이터 형식, 특정 문체, 특정 문제 유형 등 특정한 작업에 더욱 최적화된 성능을 발휘할 수 있게 된다. Fine-tuning은 전통적인 학습 방식과 달리 기존 사전 학습된 모델의 학습 파라미터를 그대로 유지한 채, 새로운 데이터셋을 기반으로 추가 학습을 수행하여 모델의 응답 스타일과 정보 처리 방식을 조정한다.
본 연구에서는 GPT-4o 기반으로 Fine-tuning을 적용한 버전과, 적용하지 않은 버전을 비교하였다. Fine-tuning을 적용한 버전은 2가지로 데이터 셋을 각각 10개 학습한 모델과 20개 학습한 모델이다. 학습에 사용된 물리 문제는 실제 학생들을 상대로 유통되는 문제집의 문제 중 선형 운동에 관련된 문제를 선택하여 사용했으며[14], 해당 물리 문제에서 파라미터를 추출할 때, 특정 문제와 그에 맞는 반환해야 할 Function의 파라미터를 학습 데이터로 제공하여 GPT의 문제 분석과 파라미터 추출 성능을 최적화하였다. 이를 통해 파라미터 추출의 일관성과 정답률을 높이고자 하였다.
5. Fine-tuning 결과 비교
Fine-tuning의 성능을 비교하기 위해 세 가지 모델을 대상으로 실험을 수행하였다.
| 명칭 | 설명 |
|---|---|
| GTP-4o | Fine-tuning모델의 기본 모델 |
| FT10 | GTP-4o 기반으로 데이터 셋 10개를 학습시킨 Fine-tuning 모델 |
| FT20 | GTP-4o 기반으로 데이터 셋 20개를 학습시킨 Fine-tuning 모델 |
실험에 사용된 문제의 조건은 다음과 같다. “자동차 A와 B는 동일한 위치에서 출발하여 등가속도 운동을 하며, 자동차 A의 초기 속도는 2m/s이다. 운동을 시작한 후 t초가 되는 시점에 두 차량은 각각 30m, 18m의 위치에 도달한다. 두 자동차의 가속도는 크기와 방향이 동일하다.”[15]
이 문제는 시간(t)과 가속도(a)가 주어지지 않은 상태에서, 주어진 조건만으로 이를 정확히 추론해야 하는 것이 핵심이다. 조건에 따르면 이 문제의 가속도는 1m/s2, 총 시뮬레이션 시간은 6초이다. 실험 방법은 해당 조건이 포함된 문제 이미지를 입력으로 제공하고, 모델이 생성한 자동차의 파라미터(초기 속도, 가속도 등)를 기반으로 시뮬레이션을 수행한다. 이후, 시뮬레이션 결과에서 6초 후 자동차 A와 B가 각각 30m, 18m 위치에 도달하는지를 기준으로 정답 여부를 판별한다.
각 모델은 하나의 Thread 내에서 동일한 조건으로 10번의 응답을 생성하였다. Table 3은 Thread별 정확도이다.
| Trial Number | GPT-4o Model | FT Model 10 sets | FT Model 20 sets |
|---|---|---|---|
| 1 | 70% | 70% | 100% |
| 2 | 10% | 0% | 70% |
| 3 | 60% | 0% | 100% |
FT10 모델은 기본 모델보다 정확도가 오히려 낮게 나타나는 경우가 있었으나, 응답의 오답 유형이 일관되고 제한적이라는 특성이 있었다. 반면, GPT-4o 기본 모델은 상대적으로 높은 정확도를 보이는 경우도 있었으나, 오답의 편차가 크고 다양한 유형의 오류를 포함하고 있어 응답의 일관성이 낮았다.
FT20 모델의 경우, 정확도에서 두 모델 모두를 상회하였고, 대부분의 응답에서 정답 또는 출발 위치 설정 오류에 따른 경미한 오차만 나타났다. 특히 가속도 및 초기 속도는 정확히 분석한 결과였다. 이로써 Fine-tuning 성능은 학습 데이터의 양에 따라 유의미하게 향상됨이 검증되었다.
Table 4, Table 5, Table 6는 각 모델이 생성한 시뮬레이션 결과를 세부적으로 비교한 것이다. A가 30, B가 18에 도달한 경우를 정답으로 판단하였다. 응답이 짙은 색으로 강조된 경우는 정답이다.
FT10 모델은 전체적으로 정답률이 낮았지만, 모든 Thread에서 유사한 오답 패턴을 반복했다는 점에서 응답의 예측 가능성 및 안정성은 향상된 것으로 볼 수 있다. 반면, GPT-4o는 Thread마다 응답 편차가 심했으며, 동일한 조건에서도 일관되지 않은 결과를 도출하였다.
FT20 모델은 대부분 정확한 값을 반환하였으며, 일부 Thread에서 B의 출발 위치가 잘못 지정된 경우(예: 초기 위치 250m + 시뮬레이션 거리 18m )를 제외하면, 정답률 및 수치 정확도 모두 우수한 성능을 보였다.
GPT 모델은 Thread 내의 여러 메시지를 참고하여 응답을 생성하는 특성이 있어, 이전 응답의 영향을 받을 가능성이 있다. 이를 배제하기 위해 각 모델에 대해 Thread당 단 1회만 응답하도록 설정한 단일 시행 실험을 수행하였다. 결과는 Table 7에 요약되어 있다.
GPT-4o 모델은 단일 시행에서 정확도가 현저히 낮아졌고 오답 편차가 컸으며, 일관성도 확인되지 않았다. 반면 FT10 모델은 응답이 대부분 오답이었음에도 동일한 형태의 수치를 반복적으로 반환하여 앞선 실험과 동일한 일관성 있는 패턴을 보였다.
FT20 모델은 대부분의 경우에서 정답에 근접하거나 정확한 응답을 도출하여, 데이터셋의 규모가 Fine-tuning 성능에 결정적인 영향을 미친다는 점을 실험적으로 입증하였다.
6. 결과 및 향후 연구
본 연구에서는 GPT API의 다양한 기능을 활용하여, 물리 문제 이미지로부터 시뮬레이션 파라미터를 자동 추출하고, 언리얼 엔진 기반 시뮬레이션에 적용하여 자동 생성하는 시스템을 제안하였다. 기존 방식처럼 사용자가 문제 조건을 수동으로 입력하지 않아도, GPT의 자연어 이해 및 Function 기능을 통해 구조화된 데이터를 얻을 수 있도록 하였다.
특히, Chat Completion과 Assistant를 병행하여 문제 분석과 파라미터 생성의 정확성을 확보하였으며, Function 기능을 통해 시뮬레이터 구성에 필요한 데이터를 명확하고 일관되게 반환하도록 설계하였다. 또한, Fine-tuning을 통해 문제 유형에 특화된 학습을 수행하였으며, 데이터셋의 양이 성능에 미치는 영향을 실험을 통해 검증하였다. 20개 데이터셋으로 Fine-tuning한 모델은 정답률과 응답의 정밀도 면에서 가장 우수한 성능을 보여 그 효과를 실증하였다.
Figure 5는 2025학년도 수능특강 과학탐구영역 물리학1 문제집 25p 7번 문제로 실제 연구과정에서 사용된 문제이다[15].
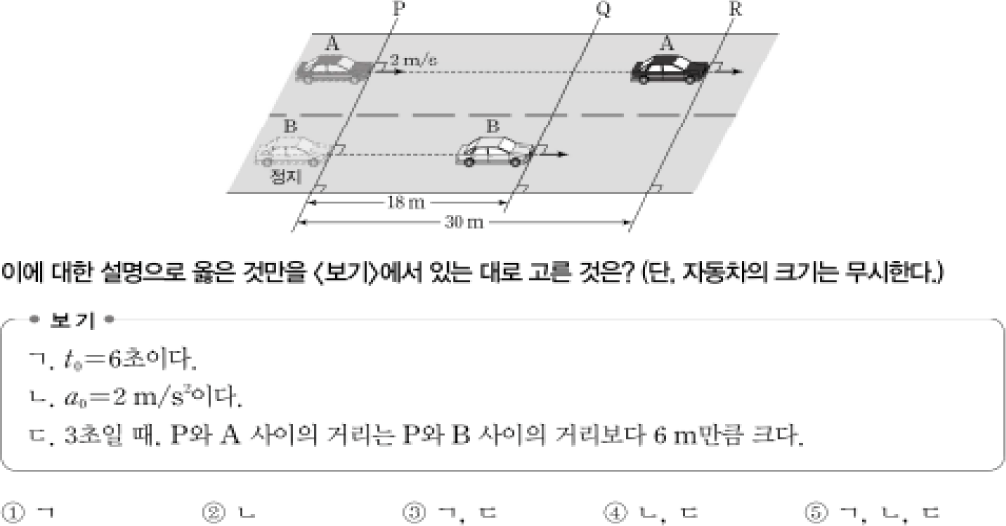
Figure 5의 문제 이미지를 그대로 입력하여 생성을 시도했고 Figure 6와 같이 자동차가 생성되었다.
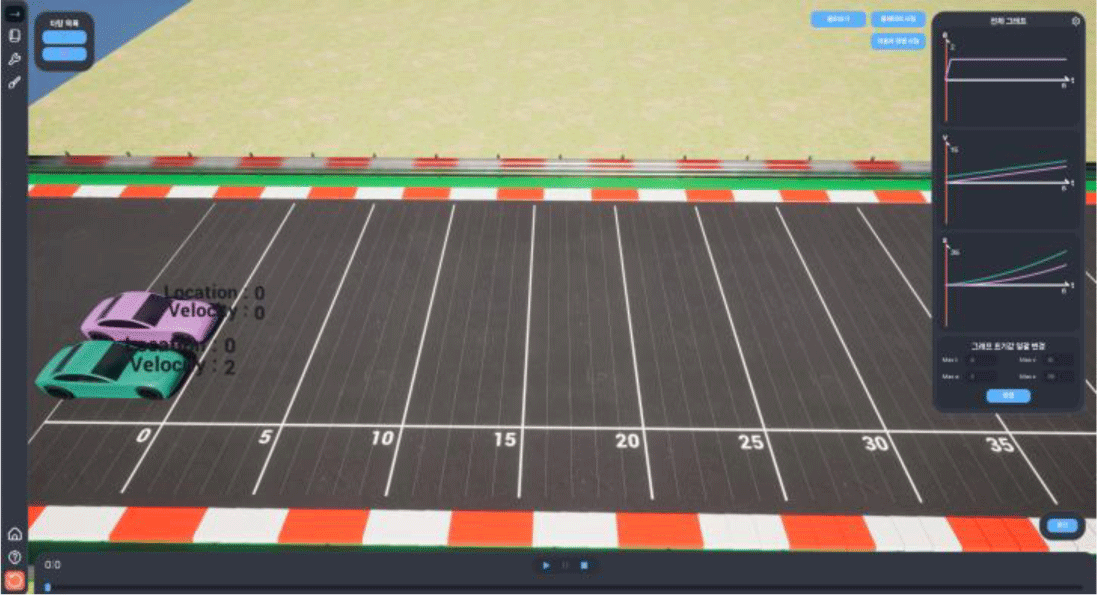
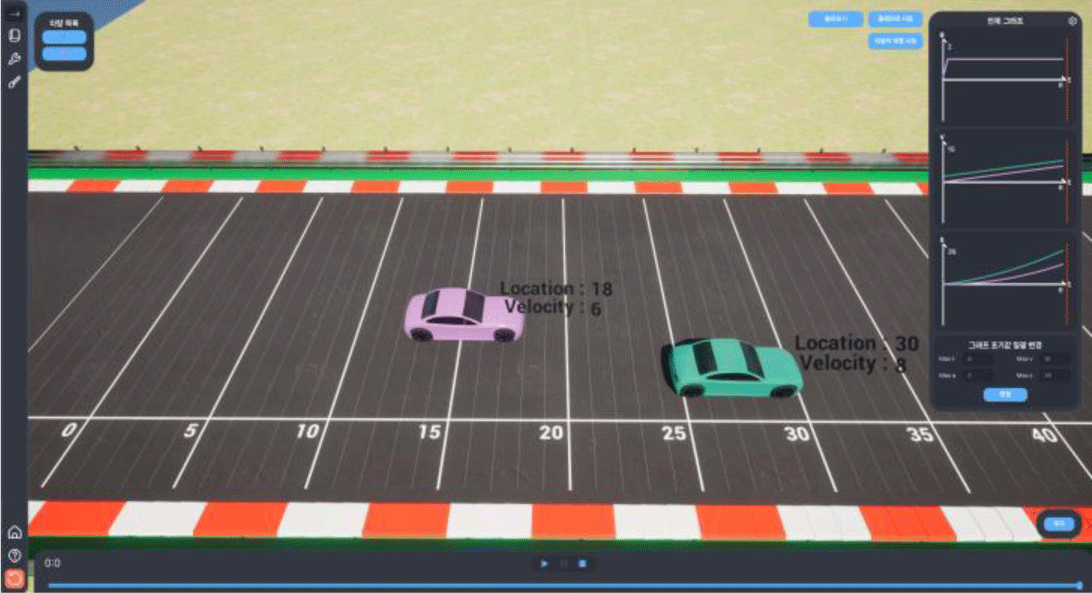
시뮬레이션을 실행하여 얻어진 결과가 Figure 7로 총 6초간 주행하여 A, B 각각 30m, 18m에 위치했다. 이 결과는 문제의 조건에 정확히 맞아 떨어지며 해당 결과를 통해 Figure 5의 (ㄱ)이 참임을 알 수 있다.
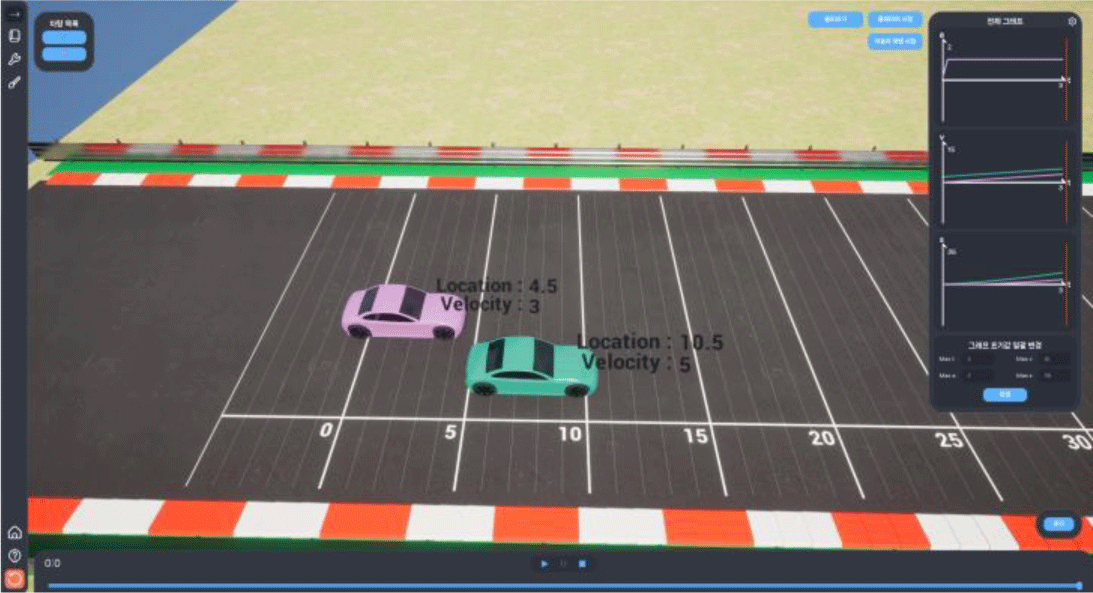
실제로 시간을 3초로 설정하고 시뮬레이션 한 결과 각각 10.5m, 4.5m에 위치했고, 이는 Figure 5의 (ㄷ)의 조건이 참임을 알 수 있으며 그래프에서 가속도는 2m/s2에 도달하지 못한 것을 확인할 수 있다. 따라서 (ㄴ)은 거짓이므로 3번 (ㄱ),(ㄷ)이 정답임을 시뮬레이션을 통해 유도할 수 있다. 이 결과를 통해 AI가 생성한 시뮬레이터 파라미터를 통해 문제를 풀 수 있음을 확인했다. 제시된 내용은 대표적인 케이스이며 해당 문제와 비슷한 유형의 다른 문제의 경우 https://whaletek.net 을 통해 결과 확인이 가능하다.
이러한 결과는 ChatGPT API를 활용한 자동 시뮬레이션 생성 시스템이 학습용 도구로서 충분한 실용성을 가질 수 있음을 보여준다. 다만 연구된 물리 문제는 직선운동에 국한된 콘텐츠 생성에 적용되었다는 한계가 있다. 향후 연구에서는 다양한 문제 유형과 물리 영역(예: 역학, 전자기, 파동, 전자회로 등)의 파라미터를 생성하는 Fine-tuning 데이터셋을 구성하고, 각 문제의 유형을 판단하여 해당 유형을 담당하는 AI로 분석을 넘기는 AI끼리의 상호작용 시스템으로 발전시킬 예정이다.
다만, Fine-tuning에 사용될 수 있는 문제의 수가 다른 분야에 비해 상대적으로 작아 정답률을 높이는데 한계가 있다. 이는 성공적으로 생성된 문제의 파라메터 수치를 다변화하여 다시 학습시키는 형태 등의 개선방향이 필요할 것으로 보인다. 또한 정답률을 분석하기 위한 수치를 표 형태로 구성하였는데, 이는 직관적인 판단을 어렵게 하는 단점이 있다. 이는 그래프 등을 활용하여 추세를 직관적으로 표현, fine-tuning결과를 쉽게 분석할 수 있게 하는 등의 개선이 필요하다.


