1 Introduction
인간 동작 예측은 다양한 응용 분야에서 핵심적인 요소로 작용해 왔다. 기존의 동작 예측 연구는 크게 두 가지 주요 범주로 분류 할 수 있다. 가장 널리 연구된 분야는 로봇이나 차량이 안전하게 행동할 수 있도록 인간의 움직임을 예측하는 응용이다. 이러한 응용은 자율주행 및 인간-로봇 상호작용에 관한 관심이 높아지 면서 본격적으로 주목을 받기 시작하였다. 예를 들어, 도로를 건 너려는 보행자의 움직임을 예측함으로써 차량이 미리 속도를 줄 이거나 멈출 수 있게 된다 [1]. 유사하게, 로봇공학 분야에서는 인간과 밀접하게 협업하는 로봇이 주변에서 안전하게 움직이기 위해 동작 예측이 요구된다. 이러한 안전 중심 응용에서는 일상 적이고 일반적인 동작을 견고하게 예측하는 것이 핵심이다 [2]. 두 번째 범주는 스포츠 훈련, 보조 로보틱스, VR 엔터테인먼트, 위험 감시 등에서처럼 역동적이거나 특수한 동작을 정확히 예측 해야 하는 응용이다. 이러한 분야에서는 좁은 동작 범위 내에서 역동적이고 개별적인 동작 패턴을 정밀하게 예측하는 능력이 요 구된다. 예컨대 스포츠 훈련에서는 선수의 자세나 움직임을 예측 함으로써 부상 위험을 줄이고 수행 능력을 향상할 수 있다 [3]. 보조 로보틱스 분야에서는 사용자의 움직임을 실시간으로 예측 함으로써 로봇이 적절한 저항이나 지지력을 제공할 수 있어, 운동 기능 향상과 재활 효과를 높일 수 있다 [4]. VR 엔터테인먼트에 서는 적은 수의 센서로부터 사용자의 의도된 동작을 예측함으로 써, 반응성 있고 현실적인 아바타 행동을 생성할 수 있다. 위험 감 시 분야에서는 비정상적이거나 위험한 행동을 사전에 예측하여 즉각적인 개입을 가능하게 한다. 이러한 응용의 공통점은 일반적 이고 일상적인 활동보다는, 제한된 수의 고속이거나 특수한 동작 패턴을 정밀하게 예측해야 한다는 점이다.
현재까지의 대부분의 연구는 첫 번째 범주, 즉 다양한 일상 동작을 예측하는 응용을 중심으로 설계되었으며, AMASS, Human3.6M, CMU 동작 캡처 데이터셋 등 대규모 데이터셋을 기 반으로 평가되어 왔다 [5, 6]. 이들 데이터 셋은 보통 제한된 공 간에서 수집된 짧은 길이의 동작들로 구성되어 있어, 스포츠나 엔터테인먼트 환경에서 요구되는 고속 동작 예측에는 부적합하 다. 현재 공개된 데이터셋 중에서 이러한 동적 움직임을 가장 잘 포착한 것은 LaFAN 데이터셋으로, 게임 개발을 목적으로 제작되 었으며, 전문 배우가 넓은 공간에서 수행한 고속 동작이 포함되 어 있다. LaFAN은 AMASS나 Human3.6M과는 근본적으로 다른 동작 프로파일을 제공하며, 빠르고 표현력 있는 고에너지 동작이 요구되는 시나리오에서 모델 성능을 평가하기에 특히 적합하다. 그러나 이 데이터셋은 동작 예측 모델에게 독특한 도전 과제를 제시한다. 특히 의미론적으로 유사한 동작 간에도 수치적인 거리 차이가 매우 크다는 특성이 있다. 예를 들어, 느린 걷기 동작과 서 있는 동작 간의 수치적 거리는 매우 작지만, 서로 다른 속도로 수행된두 개의 빠른 달리기 동작 간의 거리는 훨씬 크다. 이러한 차이는 모델이 동일 동작 유형 내의 변화를 일반화하기 어렵게 만들며, 결과적으로 모델은 유사한 동적 동작 간을 보간하지 못 하고, 오히려 학습 중에 본 특정 동작 패턴에 과적합 (overfit)되는 경향을 보인다. 이에 따라 예측 결과는 일관 성과 안정성이 떨 어지는 문제가 발생한다. 예를 들어, 표현력을 강조한 확산 기반 (diffusion-based) 예측 모델의 경우, 개별 프레임은 자연스럽게 보일 수 있지만, 전체 예측 동작 시퀀스는 시간적으로 일관성이 떨어지고각 프레임이 급격하게 변하는 문제가 있다. 이러한 현상 은 과적합의 결과이거나, 맥락 (context) 또는 동작 정체성 (identity)을 보존하지 못한 것으로 해석될 수 있다. 일관된 맥락 보존형 동작 생성을 목표로 하는 두 번째 응용 범주에서는 이러한 가변 성은 단점으로 작용한다. 반대로, 시간적 유사성을 잘 반영하는 연구들은 장기 예측 시 예측이 평균 동작으로 수렴하는 문제가 빈번하게 나타난다. 이러한 도전 과제는 보조 로보틱스나 가상 아바타와 같은 실제 응용에서 동작 예측 모델의 실용성을 크게 저하시킨다.
본 연구는 이러한 한계를 극복하고 더 정확하며 시간적으로 일관된 인간 동작 예측을 달성하기 위해 세 가지 핵심 기술적 혁 신을 제안하였다:
Transformer 기반 U-Net을 활용한 LDM: Transformer와 Latent Diffusion Model의 결합은 최근 동작 예측 과제에서 점점 더 주목받고 있다. 우리의 하이브리드 모델은 다양한 아키텍처의 강 점을 통합하여 활용한다: U-Net의 계층적 특징 추출 (hierarchical feature extraction), Transformer의 장거리 의존성 모델링 (long-range dependency modeling), 그리고 잘 설계된 임베딩 공간에서 작동할 때 특히 뛰어난 성능을 보이는 확산 기반 접근법 (diffusion approach)의 장점을 결합하였다.
월드 모델을 이용한 강화학습: 우리는 기존에 보유한 프레임 데 이터를 활용하여 Neural ODE를 학습시켰으며, 이를 통해 데이터 공간상에서 월드 모델을 구축하였다. 이렇게 생성된 가상의 특징 환경 (feature environment)은 데이터셋만을 기반으로 구성된 시 뮬레이션 환경으로, 강화학습에 활용되었다. Neural ODE를 통해 외부 시뮬레이터 없이도 원본 데이터셋만으로 일관되고 그럴듯 한 가상 환경을 구축하여 강화학습을 진행하였다 [7, 8].
Dual Sampling: 우리는 기존의 diffusion 모델에서 p-sampling 을 통해서 동작을 예측하지만 이는 상한은 존재하지만 하한은 존재하지 않는 문제가 있다.이를 해결하기 위해서 p-sampling의 하한을 위한 pd-sampling을 생성하여서 노이즈의 최적화 연구를 진행하였다 [9].
2 Related Work
이 장에서는 본 연구와 관련된 세 가지 핵심 분야를 중심으로 기 존 연구들을 소개한다.
Latent Diffusion Model (LDM)은 입력 특징 공간이 아닌 학습 된 잠재 공간 (latent space)에서 확산 과정을 수행함으로써, 생성 능력을 유지하면서도 차원수를 효과적으로 감소시킨다 [10, 11]. LDM는 높은 품질과 효율성 덕분에 조건부 생성 (conditional generation)에서 널리 사용되고 있다. 기존 Diffusion Model의 생성을 향상시키기 위해 다양한 아이디어가 제안되었으며, 예를 들어, 변분 오토인코더 (Variational AutoEncoder, VAE)를 활용한 잠재 공간의 압축 [12], 점진적인 노이즈 제거 과정을 포함한 확산 과 정 [13], GAN 프레임워크와의 통합 [14] 등이 있다.
LDM는 텍스트-이미지 생성 [15], 비디오 복원 [16] 등 다양한 작업에 성공적으로 적용되어 왔으며,
최근에는 인간 동작 예측 [17] 및 동작 계획 (motion planning) [18, 19] 분야에서도 활용되며, 좌표 공간이 아닌 잠재 공간 내에서 더 현실적이고 다양한 동작 생성을 가능하게 하고 있다. 본 연구와 가장 유사한 선행 연구는 BeLFusion을 통해서 LDM을 사용하게 되었다. 이 연구는 LDM을 동작 예측에 도입하며, 자세 표현과 동작 역학을 분리한 행동 기반 잠재 공간에서 확산 과정을 수행하였다 [17].
기존의 방법들이 좌표 수준에서의 다양성에 초점을 맞춘 것과 달리, BeLFusion은 본 연구와 마찬가지로 잠재 임베딩을 활용하 여 행동 수준의 일관성을 유지하는 데 중점을 두고있다.우리의 연구도 Belfusion에서 사용하는 LDM의 매커니즘을 사용하여서 동작을 예측하였다.
강화학습은 동적인 환경에서의 순차적 의사결정 과정을 모델링 하는 강력한 프레임워크로 부상하였다. 특히, 로보틱스 및 물리 기반 캐릭터 제어 분야에서 복잡하고 고차원의 공간 내에서 안 정적이고 목표 지향적인 동작을 학습하는 데 있어 강화학습은 탁월한 성과를 보여주고 있다 [20, 21].
동작 예측 분야에서 강화학습은 사전에 정의된 동작 궤적을 넘 어서 일반화 가능한 적응형 정책 (adaptable policies)을 학습할 수 있도록 한다. 이는 과거에서 미래 동작으로의 직접적인 매핑에 의존하는 전통적인 지도학습 방식과 달리, 환경과의 상호작용을 통해 행동을 최적화함으로써 복잡하고 불확실한 상황에서 더 뛰 어난 일반화 성능을 제공한다 [22, 23].
또한 일부 연구에서는 LSTM이나 GRU와 같은 순환 신경망 (RNN)을 활용하여시간적 이력을 압축된 잠재 상태로 인코딩하 여 월드 모델을 구현하는 방식으로 문제를 정식화하였다 [24, 25]. 하지만 이러한 방법들은 동작 예측 (task prediction)에 있어 큰 난제 중 하나는 부분 관측성 문제 (partial observability)를 포 함하고 있다. 센서 데이터는 흔히 잡음이 많거나 희소한 특성을 가지며, 움직임 이면의 실제 의도를 명확하게 파악하는 것은 본 질적으로 불가능하다. 이러한 이유로 전체 상태 정보를 정확하게 관측하는 데 어려움이 따른다.
본 연구에서는 부분 관측성 문제를 해결하기 위해 Neural ODE 를 도입하여, 현실 세계의 복잡한 동역학을 효과적으로 근사하 였다. Neural ODE는 연속적인 시간 변화를 모델링하는 능력이 뛰어나, 관측이 불완전한 환경에서도 상태의 추정과 예측 성능을 향상시키는 데 크게 기여한다.
이렇게 학습된 Neural ODE를 기반으로 현실 세계의 복잡한 환경을 모사하는 월드 모델 (world model)을 구축하였다. 월드 모 델 내부에서 에이전트는 직접 계획하거나 학습할 수 있는 환경을 제공받게 되며, 이를 통해 데이터 효율성을 크게 향상시킬 수 있 었다. 그리고 이렇게 학습된 월드 모델을 통해서 우리는 부분관 측만조건인 POMDP (Partial Observe Markov Decision Process) 를 통해서 강화학습을 진행하여서 부분관측 문제를 해결하고 노 이즈 견고성을 강화하였다.
Diffusion 모델은 최근 생성 모델 분야에서 우수한 성능을 입증 하며 활발하게 연구되고 있다. 특히, 확률 밀도 기반의 Sampling 방법인 p-sampling은 노이즈를 점진적으로 제거하여 현실적인 데이터를 생성하는 데 널리 사용되어 왔다. 그러나 이러한 방법 은 노이즈 수준에 상한 (upper bound)만 존재하고 하한 (lower bound)이 설정되지 않아, 노이즈가 작아지는 경우에 대한 견고 성을 보장하지 않아서, Sampling 과정의 안정성과 견고성 (robustness)이 떨어지는 단점이 있다 [26] . 이러한 문제를 해결하 기 위해 최근의 연구들에서는 기존의 p-sampling 방식에 대응하 는 dual sampling을 도입하여 노이즈에 대한 하한을 설정함으로 써 모델의 견고성을 높이려는 접근법이 제안되고 있다 . 확률적 Sampling (DDPM)과 결정론적 Sampling (DDIM)의 dual 구조를 활용하여, 노이즈의 최소 수준을 수학적으로 보장함으로써 노이 즈가 과도하게 감소하는 현상을 방지하는 방법을 제안하였다. 또 한, Diffusion Model의 확률 미분 방정식 (SDE) 프레임워크를 기 반으로 리스크 민감도 (risk-sensitivity)를 최적화하여, 노이즈의 최소값과 최대값을 함께 고려함으로써 Sampling 과정의 안정성 을 향상시키고자 하였다 [27].본 연구 역시 이러한 흐름을 따라 p-sampling과 dual sampling 인 pd-sampling을 결합하여 Sampling 과정에서 노이즈 수준에 대한 하한과 상한을 동시에 제어함으로 써 보다 안정적이고 견고한 생성 성능을 달성하고자 한다.
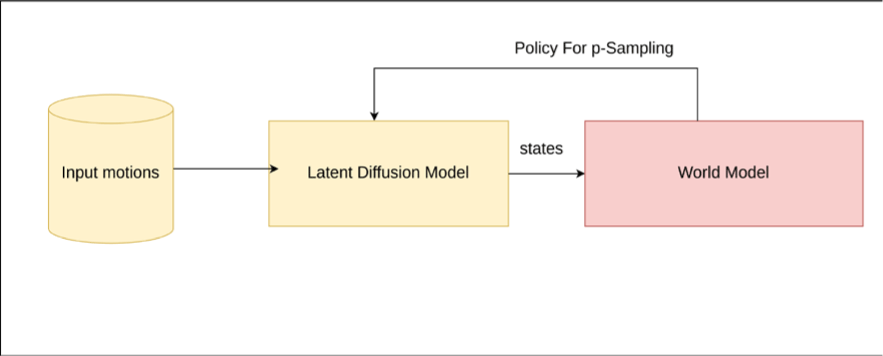
3 Overview
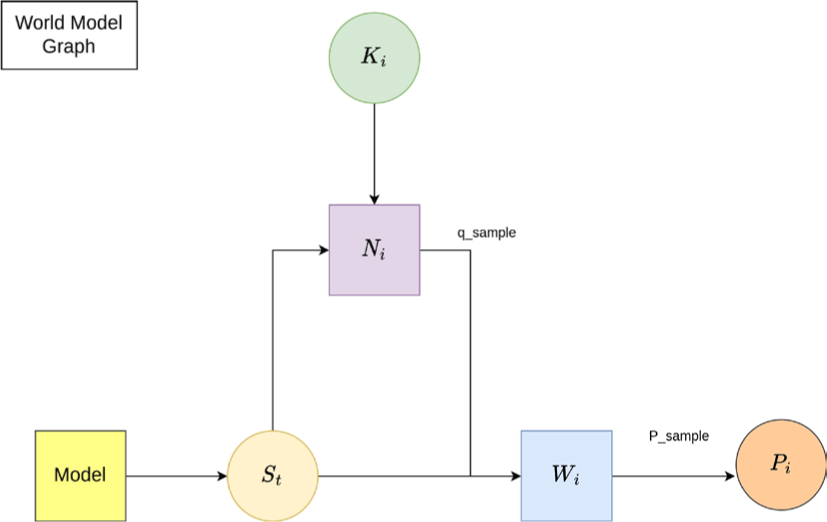
Figure 1에 나타난 바와 같이, 본 시스템은 두 가지 모듈과 한가지 최적화 과정으로 구성된다:
LDM은 과거 10프레임을 입력으로 받아, 미래 10프레임 이후의 단일 동작을 예측한다. 즉, 1프레임부터 10프레임까지의 미래 동 작들을 예측하기 위해서는, 과거 20프레임을 슬라이딩 윈도우 방 식으로 입력으로 사용하여 각 미래 프레임에 대해 총 10번 반복 하여 예측을 수행한다.
월드 모델은 LDM으로부터 예측된 10개의 동작을 입력으로 받아 이를 개선한다. 이를 손실 함수 기반의 학습을 통해 LDM 예 측에 대한 노이즈 견고성을 향상시킨다.구체적으로, 월드 모델은 LDM으로부터 예측된 프레임들과 q-Sampling된 노이즈를 환경 상태로 간주하고, 강화학습을 통해 장기적이고 일관된 예측을위 한 정책을 최적화한다.
마지막으로 전체적인 모델은 아니지만 노이즈 최적화를 위한 Dual sampling을 실행해 노이즈에 대한 경계를 잡아 주었다.다음 절에서는 각 모듈에 구조와 동작원리를 순차적으로 설명한다.
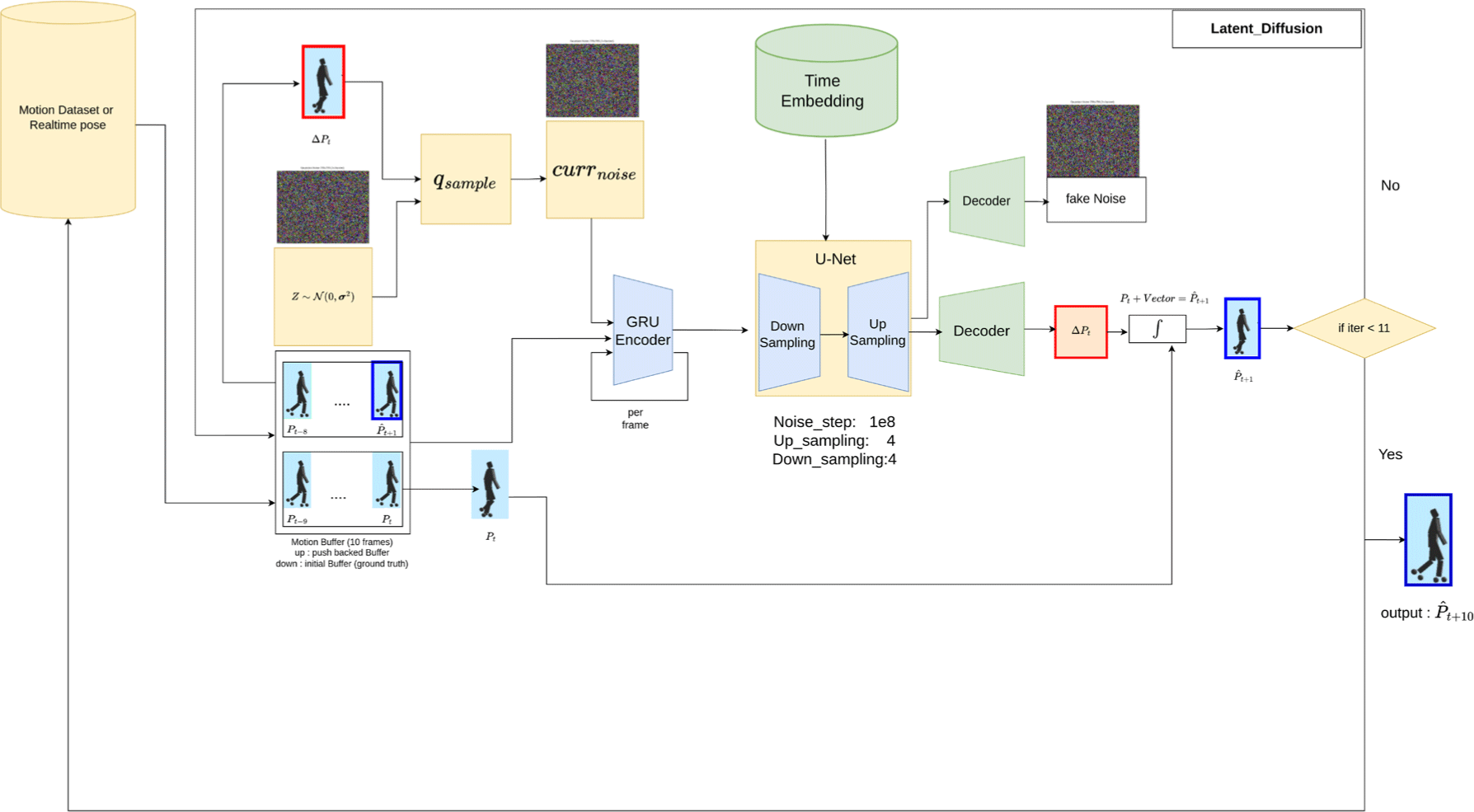
4 Latent Diffusion Model
Figure 2에 나타난 바와 같이, 본 연구에서는 고차원 동작 데이터 를 보다 효율적으로 처리하기 위해 이를 압축된 잠재 공간으로 사 영하는 LDM 프레임워크를 채택하였다. 이러한 전략은 연산 및 메모리 효율을 크게 향상시켜, 고해상도 입력 데이터에 대해서도 효율적인 학습을 가능하게 한다. 해당 잠재 공간에서는 제어된 양의 노이즈가 체계적으로 주입된다. LDM은 이 노이즈를 점진 적으로 제거함으로써, 원래의 데이터를 복원한다. LDM의 학습 과정은 다음과 같은 목적 함수로 표현된다:
여기서 zt = αtz0 + σtϵ, αt, σt ∈ R. 는 노이즈 확산 과 정에서의 하이퍼파라미터이며, cmanifold는 동작 데이터의 임베딩 다양체 구조에 대한 조건을 나타낸다.
우리는 본 LDM 프레임워크 내에 Transformer가 결합된 U-Net 구조 (Transformer-Supported U-Net)를 제안한다. 이 모델은 U-Net의 계층적 특징 추출 능력과 Transformer의 장거리 시공간 의 존성 모델링 능력을 결합하여, 예측의 품질과 시간적 일관성을 크게 향상시킨다. 이 인코더-디코더 구조는 다음과 같은 주요 구 성 요소들로 이루어진다. 첫째, Manifold-Aware Pose Encoder는 현재 동작과 노이즈 벡터를 사전에 정의된 다양체 표현을 활용하 여 인코딩한다. 생성된 임베딩은 U-Net 내에서 스킵 연결을 통해 디코딩 시 의미론적 구조를 보존하도록 전달된다. 둘째, Transformer의 attention 모듈은 동작, 노이즈, 다양체 특징을 텐서 곱 방식으로 통합한 후, Transformer를 통해 전역적인 시공간 의존 성을 학습한다. 이러한 구조는 고정밀 동작 복원을 가능하게 할 뿐만 아니라, 강화학습 파이프라인과의 높은 호환성도 유지한다. 특히 Transformer-Supported U-Net은 매우 역동적인 동작 입력 으로부터 부드럽고 시간적으로 일관된 예측을 생성하는 데 매우 효과적이다. Transformer 기반 Attention 모듈의 출력은 두 가지 구성 요소로 분기된다. 첫 번째 구성 요소는 denoised motion sequence를 예측하며, 이는 단기 동작 예측에 사용된다. 두 번째 출력은 fake noise generator로 지정되며, 월드 모델과의 통합을 위해 설계된 노이즈를 생성한다. 이 노이즈는 다양한 시나리오 생성을 가능하게 하여, 환경 시뮬레이션의 견고성을 높이는 데 기여한다. 이러한 이중 출력 구조는 GAN에서의 노이즈 생성 메 커니즘과 유사하게 작동한다. 네트워크 구조에 대한 보다 자세한 내용은 Section A을 참조하기 바란다.
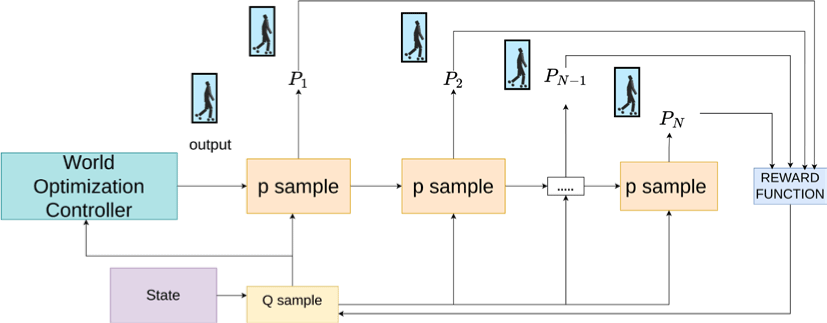
5 World Model
Figure 3에 나타난 바와 같이, 본 연구에서는 강화학습 기반의장 기 동작 예측을 위해 월드 모델을 사용한다. 이 월드 모델은 자 기지도학습에 기반한 모듈로, 실제 인간 동작 및 그 변화를 학습 하도록 설계되었다. 우리의 월드 모델은 다음과 같은 명제로부터 출발한다:
명제 (Proposition): 인간 동작 예측에서 입력 동작 표현의 특성 상 예측 공간은 컴팩트 (compact)하다. 이를 모델링하기 위해, 우 리는 시간과 자세 (프레임)의 곱공간을 월드 모델 다양체 (world model manifold)로 사상하는 연산자 (operator)를 정의하며, 이는 POMDP 프레임워크 내에서 최적화된다.
여기서 k는 예측 윈도우 (10 프레임)를 나타내고, F = R35 는 프레임 공간을 나타내며, 이는 Neural ODE에 의해 예측된 동 작 공간으로, 각 벡터는 인체의 루트 구성과 관절 각도를 인코딩 한다.
W 는 월드 모델 다양체 공간을 나타내며, 10프레임으로 구성된 동작 시퀀스를 구조적으로 임베딩한 공간이다. 집합 W 는 다음과 같은 함수를 포함한다:
이는 불확실성 하에서 최적 상태 전이를 보장하는 함수 집합 이다.
연산자 K는 닫힌 (closed) 컴팩트 연산자로서, 동작 데이터로 부터 월드 모델 다양체로의 사상에서 안정성과 유계성 (boundedness)을 보장한다. 또한 K는 Neural ODE를 사용하여 구성되며, 시간에 따른 인간 동작의 연속적이고 미분 가능한 표현을 제공한 다. 따라서, K를 통한 임베딩은 인간 동작을 구조화된 방식으로 학습할 수 있도록 하며, POMDP 기반 최적화를 활용하여 최적의 정책을 학습할 수 있도록 한다.
모든 모델은 입력 프레임으로부터 목표 동작을 예측하는 방식으 로, 직접 정책 최적화와 유사한 방식으로 동시에 학습된다. 전체 손실 함수는 다음과 같이 네 개의 독립적인 항목으로 구성된다:
출력 손실 Loutput은 LDM의 출력 동작과 해당하는 정답 동작 (ground truth motion) 간의 L2 차이를 직접적으로 측정한다:
Lnoisefake 이는 LDM로부터 생성된 노이즈 출력을 기반으로 계산 된 GAN 유사 손실(GAN-like loss)을 나타낸다:
Lnoisefake 는 LDM의 q-Sampling 과정에서 사용된 원래 노이즈와 LDM이 예측한 (또는 ”가짜” 로 생성한) 노이즈를 비교하는 손 실 함수이다. 이 손실 항은 월드 모델의 출력이 LDM이 기대하는 노이즈 분포와 호환되도록 보장하여, LDM이 적절한 노이즈 경 계 내에서 유효한 예측을 생성할 수 있도록 한다. 월드 모델의 강화학습 손실인 Lworld는 사전 학습된 노이즈 경계 조건을 활용 하여, 월드 모델 프레임워크 내에서 센서 입력 프레임 공간에서의 POMDP를 해결한다. 이 손실 함수는 부분 관측 하의 Neural ODE 를 활용하여 강화학습을 수행하며, 할인 누적 보상 (discounted cumulative reward)을 통해 학습을 진행한다. 여기서 r은 할인 계 수 (discount factor)를 의미한다:
이러한 손실 함수들을 통합함으로써, 전체 프레임워크는 동작 예 측의 정확도와 강화학습의 효율성을 동시에 최적화하고자 한다. 전통적인 지도 학습을 넘어, 우리는 월드 모델을 활용하여 미래 프레임을 생성하고 최적화를 수행한다. 또한, 본 접근법은 프레 임 시퀀스 상에서 강화학습에 적합한 공간을 구성하기 위해 Neural ODE 기반의 수식화를 통합하였다. 학습 과정에 대한 보다 자 세한 내용은 Section C을 참조하기 바란다.
6 Dual sampling
본 연구에서는 기존의 p-sampling을 넘어서 pd-sampling을 추가 하여서 단순 sampling이 아닌 노이즈 에대한 경계값을 설정하는 sampling을 통해서 노이즈에 대한 최적화를 진행하였다. 이에 대 한 sampling 의 공식은 아래와 같다:
여기서 µ는 생성된 평균 (mean)을 나타내며, ϵ은 각각의 Sampling 과정에서 사용된 노이즈를 나타낸다. 우리는 normal sampling을 통해서 기존의 LDM의 생성에 대한 장점을 유지하면서 도 노이즈 에 대해서 견고한 동작을 생성할 수 있었다.
7 Experimental results
구체적으로, 동작 유형별로 분류했을 때, 학습 데이터셋에는 전체 데이터셋 중 Aiming의 40%, Dance의 42%, Fight의 33%, Ground의 50%, Jump의 33%, Multi-Action의 75%, Obstacle의 44%, Push의 33%, Run의 25%, Splinter의 50%, Walk의 16%가 포함된다. 이 동작들은 주로 Subject 1과 Subject 2에 의해 수행되 었다. 나머지 동작들은 평가용 데이터로 사용되었다.
학습 데이터에는 스타일적으로 유사한 동작들이 포함되어 있 으나, 평가 데이터와 동일한 동작 시퀀스는 포함되지 않아 일반화 성능을 공정하게 평가할 수 있도록 구성하였다.
첫 번째 연구에서는 제안하는 동작 예측 프레임워크를 세 가지 기준 모델과 비교하여 평가하였다. 첫 번째 기준 모델인 BeLFusion은 본 연구와 유사하게 LDM을 활용한다 [17]. 마지막 두 기 준 모델인 TransFusion은 Transformer 기반의 Diffusion Model을 채택하여 동작 예측을 수행한다 [28, 29]. 모든 모델은 RTX 3070 Ti GPU와 AMD Ryzen 5 5600X 6코어 CPU가 장착된 머신에서 학습되었다. 모델별 학습 시간은 다음과 같이 상이하였다: BeL-Fusion과 TransFusion은 약 2일정도의 학습 시간이 소요되었고, 한편, 제안하는 우리 모델은 아키텍처의 복잡성과 추가적인 월드 모델에 의한 강화학습 과정으로 인해 약 3일정도의 학습 시간이 소요되었다.
우리의 방법은 BeLFusion 및 TransFusion과 같은 확산 기반 (diffusion-based) 모델들과 동일한 타임스텝 수 (time steps)를 사 용하여 학습되었다. 예측 정확도를 평가하기 위해, 예측된 동작 과 정답 동작(ground-truth)을 다음과 같은 지표를 사용하여 비 교하였다: MPJPE (Mean Per Joint Position Error) – 관절 위치 오차의 평균, 단위는 미터 (m), MPJRE (Mean Per Joint Rotation Error) – 관절 회전 오차의 평균, 단위는 도 (degree). Table 1는 각 동작 범주별로 오류를 측정한 후, 전체 범주에 대한 최대 오차 및 평균 오차를 제시한다. 우리의 방법은 모든 연구에서 가장 우수한 결과를 달성하였다.
더 중요한 점은, 다른 모든 접근 방식이 매우 역동적인 동작 에 대해 어려움을 겪었으며, 그 결과 예측이 전반적으로 노이즈 가 많은 경향을 보였다는 것이다. 반면, 월드 모델을 결합한 우리 모델은 더 높은 품질의 동작 예측을 생성하였으며, 이는 첨부된 비디오에서도 각각의 모델의 출력을 비교하면 확인할 수 있다.
8 Ablation Study
제안하는 모델의 전체 성능에 있어 각 구성 요소인 잠재 동작 U-Net, 그리고 월드 모델의 개별적인 기여도를 명확히 평가하기 위 해 Ablation Study를 수행하였다.
Table 2에 요약된 결과는 각 구성 요소가 성능 향상에 의미 있게 기여하고 있음을 보여준다. 각각 LDM 모델에서의 Latent 파트의 제거, 그리고 그 후 LDM에서 월드 모델 의 제거 단계로 ablation study를 진행하였다. 이는 단순 확산인 Standard Diffusion을 통해 서 기존의 Diffusion을 실험 하였고,그 후 우리모델에서 강화학습 부분인 월드 모델을 제거한 Standard LDM을 실험하였다.마지막 으로 월드 모델까지 포함한 우리의 모델로의 발전을 연구로 진 행하였다. 실험 결과를 보면,월드 모델을 제외했을 경우 성능이 크게 저하되었으며, 이는 구성 요소가 모델의 성능에 있어 매우 중요한 역할을 하고 있음을 뒷받침한다.
그리고 우리는 Dual sampling을 진행한 것과 아닌 것을 비교 하는 연구를 추가로 진행하였다. 이를 통해서 우리는 Dual Sampling을 통한 노이즈의 최적화가 적용 가능함을 알 수 있었다.
| Model | Performance | Dance | Run | Walk |
|---|---|---|---|---|
| Ours | MPJRE (deg) | 8.141 | 6.304 | 6.606 |
| MPJPE (m) | 0.0201 | 0.0664 | 0.077 | |
| No Sampling | MPJRE (deg) | 9.925 | 8.4255 | 9.24377 |
| MPJPE (m) | 0.1307 | 0.1470 | 0.1348 |
9 Conclusion and Discussion
본 연구는 기존 확산 기반 (Diffusion) 모델이 갖는 노이즈 민감성 문제를 극복하고, 보다 정확하고 시간적으로 일관된 인간 동작 예측을 달성하기 위해 세 가지 핵심 기술을 제안한다.
첫째, 트랜스포머 기반의 U-Net 구조를 활용한 LDM을 도입하 였다. 최근 동작 예측 과제에서는 트랜스포머와 LDM의 결합이 점차 주목받고 있으며, 본 연구에서는 트랜스포머의 시계열 정 보에 대한 장기 의존성 처리 능력을 활용하여, 노이즈 환경 하에 서의 경계를 효과적으로 형성함으로써 노이즈에 대한 견고성을 확보하였다.제안하는 하이브리드 모델은 다양한 아키텍처의 장 점을 통합한다. U-Net의 계층적 특징 추출 능력, 트랜스포머의 장거리 의존성 모델링, 그리고 구조화된 임베딩 공간에서 효과 적으로 작동하는 확산 기반 접근법(diffusion approach)의 이점을 조합하였다.이는 기존의 Diffusion Model에서는 역문제(inverse problem) 해결 시 데이터 정보가 부족하여, 연속적인 동작을 생성 할 때 노이즈가 잔존하고 결과적으로 동작의 불안정한 현상이 발 생하는 문제를 해결하고제노이즈에 대한 견고성을 향상시켰다.
두번째로, 우리의 모델은 기존의 강화학습이 가지는 부분 관 측성의 문제를 Neural ODE를 통한 월드 모델의 구현을 통해서 해결하였다.기존의 강화학습에서는 환경에 대한 전체 정보를 통 해서 학습이 진행되는데,이는 현실적으로 전체 환경을 예측하는 어려움이 실제 세계에 있고,전체 정보를 전부 집어 넣어서 학습을 시키면,시간적으로 큰 손실이 있으며 과적합의 문제 또한 발생 할 수 있다.우리의 모델은 월드 모델의 장점이 특징 공간 (feature space) 만을 사용하여서 과적합에 대해서 견고성을 유지함과 동 시에 Neural ODE를 통해서 부분 정보를 통해서 실세계에서의 부분 관측성 문제를 해결 하였다.이는 우리의 월드 모델을 통한 강화학습이 노이즈에 대한 견고서을 높이는데 있어서 실세계와 바로 연결된다는 장점을 시사하고 있다.
마지막으로, Dual Sampling 전략을 통한 노이즈에 대한 최적화 전략으로 Dual Sampling을 통해서 우리의 연구는 기존의 Diffusion Model 이 가지고 있는 p-sampling 에서의 단점을 해결하고 단순한 동작의 생성을 넘어서서 고품질의 동영상을 실시간적으 로 예측하는 결과를 얻을수 있었다 [7, 8].
하지만 우리의 연구는 아직 실시간 동작 생성에서 13frame 이 상에서는 결과가 좋지 않다는 단점이 있다.앞으로의 연구에서는 실시간 고품질 동작 생성에 더해서 장기간 동작 예측에 대한 추 가적인 연구가 필요해 보인다.