





1. 서론
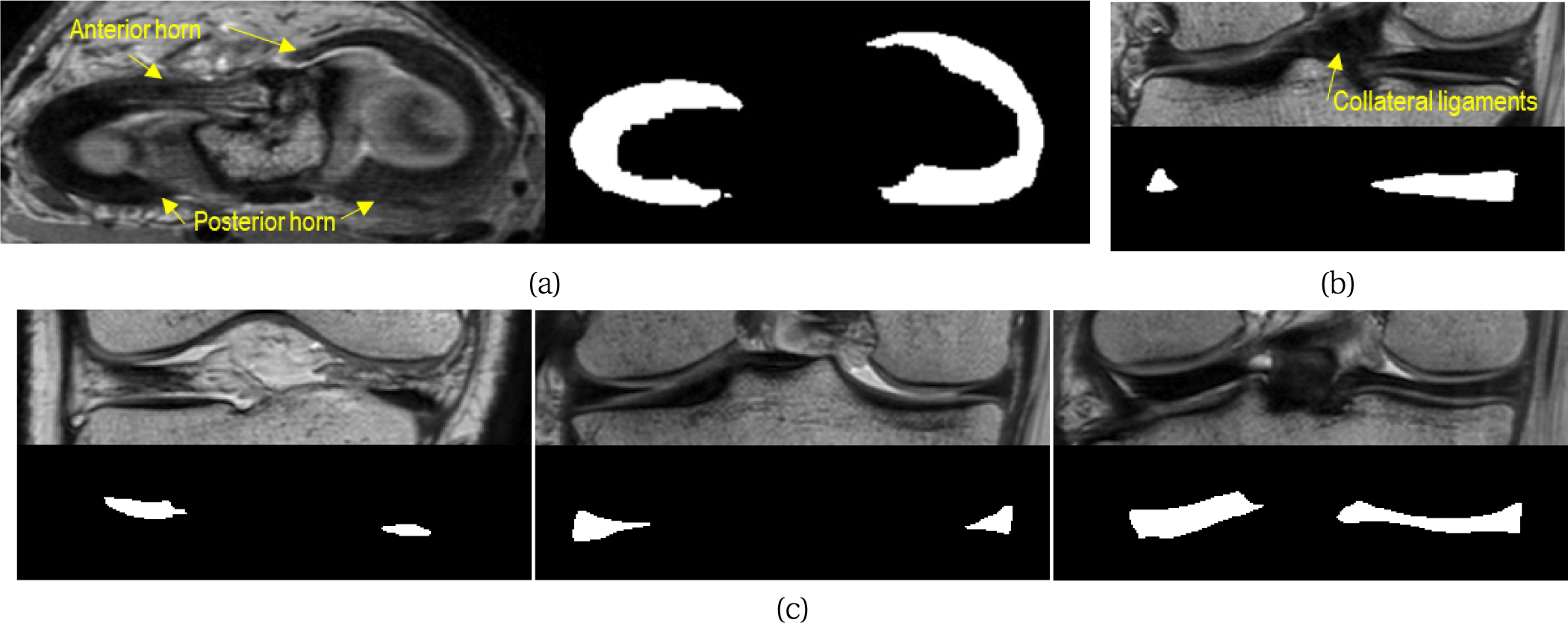
반월상 연골은 대퇴골과 경골 사이에 위치한 C자 형태의 연골로 내측 및 외측 반월상 연골로 구성되어 있으며, 무릎 관절에서 하중 분산, 충격 흡수, 마찰 감소 등 다양한 역할을 수행한다[1]. 반월상 연골은 장기간 반복되는 하중이나 외상, 노화 등으로 인해 쉽게 손상될 수 있으며, 이는 골관절염(osteoarthritis)과 같은 퇴행성 질환으로 이어질 수 있다. 이러한 경우, 손상된 연골을 대체하기 위해 시행되는 반월상 연골 동종이식(meniscal allograft transplantation, MAT)은 환자의 원래 연골 크기와 형태에 정밀하게 부합하는 이식편을 제작해야 성공적인 결과를 얻을 수 있다. 이를 위해 반대측의 건강한 반월상 연골을 정확히 분할(segmentation)하여 길이, 폭, 높이와 같은 구조적 파라미터를 정량적으로 산출하는 과정이 필수적이다. 따라서 무릎 MR 영상에서 반월상 연골을 분할하는 것은 맞춤형 이식편 제작 및 수술 계획 수립을 위한 핵심 단계라 할 수 있다. 하지만 Figure 1과 같이 반월상 연골은 해부학적으로 얇고, MRI 영상에서는 주변 십자인대와 유사한 신호 강도를 보이며 전각(anterior horn)과 후각(posterior horn) 부위의 경계가 모호하여 정확한 식별이 어렵다. 또한 전각과 후각은 슬라이스에서 형태가 크게 달라지고, 영상 내 신호 강도의 불균일성(signal intensity inhomogeneity)으로 인해 분할에 어려움이 있다.
무릎 MR 영상에서 반월상 연골 분할에 대한 기존 연구는 주로 CNN 기반 또는 Transformer 기반의 딥러닝 네트워크를 중심으로 이루어져 왔다. CNN 기반 연구에서는 주로 U-Net이나 V-Net과 같은 구조를 활용하여 반월상 연골 분할을 수행하였으며, 이후 다양한 변형과 보완이 제안되었다. 기존 U-Net 구조에 주의 메커니즘을 도입하여 소규모 데이터셋에서도 중요한 영역에 집중할 수 있도록 한 연구 및 Mask R-CNN을 3D로 확장하여 분할을 수행한 연구가 제안되었다[2-3]. 또한 meniscus의 위치와 형태 정보를 보조 채널로 제공하는 object-aware map과 조건부 적대적 학습 구조를 결합하여 경계 불확실성이 큰 영역에서의 성능을 개선한 연구 및 YOLO 기반 탐지 네트워크와 앙상블 기법을 통해 일반화 성능과 강건성을 강화한 연구도 제안되었다[4-5]. 이와 같은 CNN 기반 방법들은 국소 영역의 구조는 잘 포착하지만, 얇은 반월상 연골의 전역적 맥락을 안정적으로 인식하는 데 한계가 있다[6]. Transformer 기반 연구에서는 Swin Transformer와 같은 셀프-어텐션 구조 및 이전 슬라이스 정보를 기억하려 활용함으로써 연속적인 3D 맥락을 반영하는 메모리 기반 모델을 활용하여 전역적인 문맥 정보를 효과적으로 포착하고, 다양한 크기와 형태의 해부학적 구조를 갖는 반월상 연골을 정밀하게 분할하고자 하였다[7-9]. 이러한 구조는 CNN에 비해 더 넓은 수용 영역과 계층적 표현력을 바탕으로 다양한 해부학적 구조를 포괄적으로 인식할 수 있으나, 얇은 반월상 연골의 경계와 같은 세밀한 지역적 특징을 안정적으로 포착하기 어렵다. 이로 인해 경계 표현이 뚜렷하지 않은 조직에서는 주변 조직까지 과도하게 포함하는 과대 분할(over-segmentation)이 발생하기 쉽다. 또한 Transformer 기반 모델은 셀프-어텐션 연산 특성상 파라미터 규모가 크고 학습 안정성을 위해 대규모 데이터셋에서의 사전학습(pretraining)에 크게 의존하여 데이터셋 규모가 제한적인 의료 영상 환경에서는 모델의 일반화 성능을 확보하는 데 제한적이다.
최근 연구되는 확산(diffusion) 모델은 입력 데이터를 점진적으로 노이즈화한 후 반복적인 역과정을 통해 원본 구조를 복원하는 방식으로 학습된다[10-11]. 이러한 복원 중심의 학습 특성은 복원 과정의 각 단계에서 미세한 형태 변화와 경계 정보를 세분화하여 모델이 누적적으로 학습하도록 만들기 때문에, 경계가 불분명한 얇은 구조에서도 안정적인 경계 추정이 가능하다. 또한 확산 모델은 데이터 분포를 직접 모델링하며 구조적 일관성을 유지하는 방향으로 복원하도록 학습되므로, 기존 CNN이나 Transformer 기반 분할 방법에서 나타나는 경계 주변의 과대 분할 문제를 효과적으로 완화할 수 있다.
따라서 본 연구에서는 무릎 MR 영상에서 반월상 연골과 같이 얇고 경계가 모호한 구조의 분할 정확도를 향상시키기 위해 확산 모델을 기반으로 한 새로운 방법을 제안한다. 제안 방법은 영상과 마스크를 동시에 노이즈화하는 공동 노이즈-복원(joint noising-denoising) 학습 구조를 통해 영상-마스크 간 공간적 상관관계를 직접 학습함으로써, 모호한 경계 부분의 구조적 단서를 보다 효과적으로 활용하도록 설계되었다. 또한 단계별 영상 주입(step-wise image injection) 기반 샘플링을 통해 역확산 과정에서 원본 영상의 구조적 정보를 반복적으로 주입함으로써, 새로운 영상이 생성되는 것을 억제하고 안정적인 경계 복원을 가능하게 한다. 본 연구에서는 제안 방법의 성능을 정량적 및 정성적으로 평가하며, 특히 경계가 모호하거나 반월상 연골 내부의 신호 강도가 불균일한 어려운 사례를 선정하여 성능을 확인한다.
본 논문의 주요 기여는 다음과 같다.
첫째, 영상과 마스크를 동시에 노이즈화하는 공동 조건부 확산 학습 구조를 제안하여, 영상–마스크 간의 관계를 직접 학습한다.
둘째, 단계별 영상 주입 기반 샘플링 전략을 도입하여 역확산 과정에서 원본 영상의 구조적 정보를 지속적으로 반영한다.
셋째, 무릎 MR 영상 데이터에 대한 정량적 및 정성적 실험을 통해 제안 방법의 효과를 검증한다.
2. 제안방법
확산 모델은 데이터를 점진적으로 노이즈화 한 후 이를 복원하는 과정을 학습하는 생성 모델이다. 분할 문제에 적용하는 경우, 분할 마스크가 노이즈를 추가하는 확산 과정의 대상이 되고, 모델은 이를 단계적으로 복원하는 과정을 통해 주어진 영상으로부터 올바른 마스크를 생성할 수 있도록 학습된다.
조건부 확산(conditional diffusion) 모델에서는 이 과정이 식 (1)과 같이 정의된다.
이 때, S0는 정답 마스크, St는 시간 t에서 노이즈가 추가된 마스크이며, α̅t는 누적 노이즈 스케줄 파라미터이다.
단계적으로 복원하는 역확산 과정에서는 모델이 식 (2)의 분포를 근사하도록 학습된다.
이 때, I0는 원본 영상으로 확산 과정에는 참여하지 않으며 마스크 복원을 위한 조건(condition)으로만 사용된다. 즉, 일반적인 조건부 확산 모델은 마스크는 노이즈화 되지만, 영상은 어떤 변형도 받지 않은 채 그대로 네트워크에 제공되는 구조로 이루어지며 입력 영상은 밝기 분포, 경계 정보, 해부학적 위치 정보 등 마스크 복원에 필요한 구조적 참조 정보를 제공한다[12]. 대표적인 예로 SegDiff[12] 모델은 이 구조를 따르며, 영상은 네트워크의 조건 입력으로만 사용되고 모델은 영상을 참조하여 노이즈가 섞인 마스크의 단계적으로 복원하도록 학습된다.
이와 같은 조건부 확산 방식은 데이터 분포를 기반으로 마스크를 복원하기 때문에 경계가 흐릿한 조직을 점진적으로 정제할 수 있다는 장점이 있다. 다만 영상이 확산 과정에 참여하지 않기 때문에, 영상-마스크 간의 공간적 대응 관계(spatial alignment)를 직접 학습하기 어렵다는 한계가 있다.
기존 조건부 확산 모델은 영상은 정적인 조건으로만 입력되고 마스크만 노이즈화되기 때문에, 영상과 마스크 간의 관계를 충분히 학습하지 못하고 경계가 불명확한 영역에서는 과대 및 과소 분할이 발생하는 한계가 있다.
이러한 문제를 해결하기 위해, 본 연구에서는 영상과 마스크를 동시에 노이즈화하여 공동 분포를 학습하는 공동 조건부 확산 모델(Joint Conditional Diffusion, Joint CondDiff)을 제안한다. Figure 2의 training step과 같이, 제안 모델의 학습 단계에서는 입력 영상과 이에 대응하는 정답 마스크를 모두 확산 과정의 대상으로 포함한다. 구체적으로, 영상과 마스크는 동일한 확산 스케줄에 따라 시간 단계마다 노이즈가 추가되며, 네트워크는 노이즈화된 영상-마스크 쌍으로부터 원본 영상과 마스크를 동시에 복원하도록 학습된다. 이 과정에서 모델은 영상의 구조적 패턴과 마스크의 경계 정보를 함께 고려함으로써, 두 정보 간의 공간적 대응 관계를 직접 학습한다. 즉, 영상의 형태적 패턴과 마스크의 구조적 경계 정보를 하나의 학습 공간에서 함께 인코딩함으로써, 모델이 두 입력 간의 상관관계를 자연스럽게 이해하도록 유도한다. 이러한 영상-마스크 공동 노이즈화(joint noising) 과정은 두 입력이 동일한 확산 경로를 공유하도록 하여, 기존 조건부 확산 모델에서 영상은 확산 과정에 참여하지 않고 마스크만 노이즈화되던 구조적 한계를 개선함으로써 두 데이터 간의 공간적 대응 관계를 일관적으로 학습할 수 있다. 이를 통해 반월상 연골의 얇고 불규칙한 형태나 경계가 흐릿한 부위에서도 영상의 구조적 단서를 적극적으로 활용하여 안정적이고 정밀한 분할을 수행할 수 있다. 따라서 제안된 Joint CondDiff는 영상–마스크 간 상호작용을 강화함으로써, 경계 모호성으로 인한 과대∙과소 분할 문제를 효과적으로 완화한다.
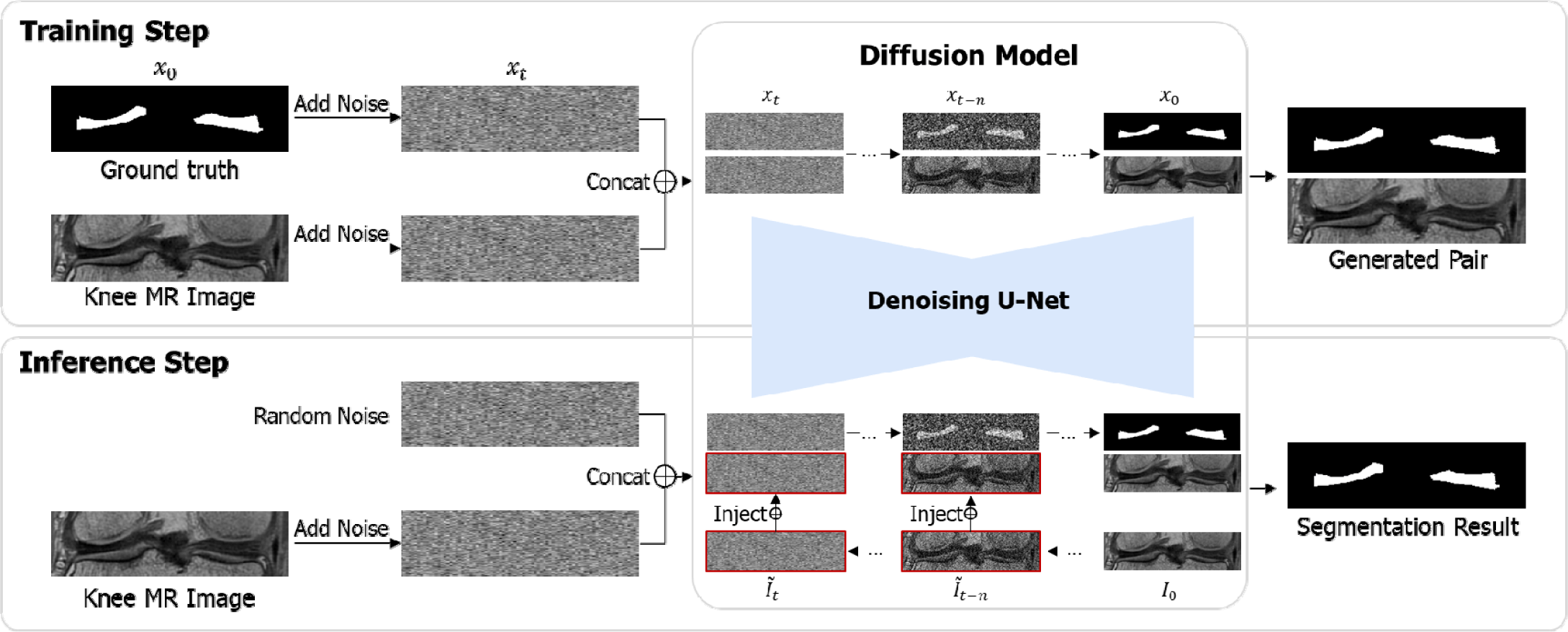
추론 과정에서의 샘플링은 역방향 확산을 반복 수행하여 노이즈화된 마스크를 점진적으로 복원하는 단계이다. 일반적인 조건부 확산 모델에서는 이 복원 과정에서 모델이 내부적으로 추정한 이미지 표현을 조건 입력으로 사용한다. 그러나 이러한 방식은 네트워크가 실제 영상의 구조적 단서를 직접 활용하지 못하게 하여, 분할 과정이 원본 영상과 정렬되지 않은 해부학적 형태를 생성하게 된다. 그 결과, 원본 영상의 해부학적 구조와 일치하지 않는 마스크가 생성될 수 있다. 특히 본 연구와 같이 학습 단계에서 영상과 마스크를 함께 노이즈화하는 구조에서는, 추론 단계에서 영상 생성이 동반될 경우 원본 영상과의 정렬이 더욱 저하될 수 있으므로 이를 제어하기 위한 추가적인 샘플링 전략이 필요하다.
이를 해결하기 위해 본 연구에서는 단계별 영상 주입(step-wise image injection) 방식을 도입하였다. Figure 2의 inference step과 같이, 매 단계 t에서 모델이 생성한 영상 대신, 원본 영상 I0에 현재 단계의 노이즈를 점진적으로 추가하여 얻은 영상 Ĩt를 조건 입력으로 주입한다. 이 과정을 통해 모델은 매 단계마다 원본 영상의 구조적 정보를 직접 참조하게 되며, 새로운 영상을 생성하지 않고 원본 영상에 대응하는 마스크만을 복원하도록 유도된다. 이와 같은 단계별 영상 주입은 역방향 확산 과정 전반에 걸쳐 구조적 제약(structural constraint) 역할을 수행하여, 모델이 원본 영상의 구조를 강하게 따르도록 한다. 결과적으로 경계가 불명확한 얇은 반월상 연골 구조에서도 안정적이고 정밀한 마스크 복원이 가능하다.
3. 실험 및 결과
실험에서 사용한 데이터셋은 삼성서울병원에서 획득한 무릎 재건 수술을 받은 103명 환자의 반대쪽 정상 무릎 MR 영상으로 구성되어 있다. Achieva 3.0T Philips Medical Systems을 통해 촬영된 3D PD VISTA 관상면 영상을 사용하였으며, 해상도는 512x512, 슬라이드 장수는 230~250장, 화소 크기는 0.3125mm, 슬라이스 간격은 0.5mm로 구성되어 있다. 본 연구에서는 3D MR 영상으로부터 추출된 2D 관상면 슬라이스를 기준으로 학습 및 추론을 수행하였다.
반월상 연골은 해부학적으로 얇아 전체 영상 내 비율이 매우 작고, 이로 인해 클래스 불균형에 따른 과소 분할이 발생할 수 있다. 따라서 본 연구에서는 반월상 연골이 항상 대퇴골(femur)과 경골(tibia) 사이에 위치한다는 해부학적 특성에 기반하여 ROI를 설정하였다. 구체적으로, 각 슬라이스에서 사전에 분할된 대퇴골 및 경골 마스크를 이용하여 두 뼈 구조가 맞닿는 중심선을 기준으로 상하 방향으로 각각 40 px씩 총 80 px 범위를 ROI로 설정하였으며, 좌우 방향은 대퇴골과 경골 중 가장 좌측 및 우측 픽셀을 기준으로 정의하여 ROI를 설정하여 최종적으로 291x80 크기로 정규화하였다. 이 과정에서 반월상 연골의 정답 마스크는 ROI 설정에 사용되지 않았으며, 대퇴골 및 경골 마스크는 반월상 연골의 해부학적 위치를 제한하기 위한 구조적 정보로만 활용되었다. 또한 촬영 조건에 따른 신호 강도 차이를 줄이기 위해 Z-score 정규화를 적용하였다[13].
실험은 GeForce RTX 3090 그래픽 카드가 장착된 서버에서 진행되었으며, CUDA 12.4, CUDNN 9.1, Python 3.10.16, Pytorch 2.6.0 환경에서 실험을 수행하였다. 모델의 구현은 VolumeDiffusion[14]의 공개 코드를 기반으로 구현하였다. 평가를 위해 83개의 훈련 데이터와 20개의 테스트 데이터로 나누어 사용하였다. 네트워크 학습 시 에폭은 900, 학습률은 5e-6, 배치 크기는 32, 타임 스텝 t는 1000, 손실함수는 평균제곱오차(Mean squared error)를 사용했다.
제안된 Joint CondDiff 모델의 성능을 평가하기 위해 앞서 설명한 조건부 확산 모델을 기반의 대표적 분할 방법인 SegDiff[12]와 성능을 비교하였고, F1-score, 재현율(recall), 정밀도(precision)를 측정하였다. 추가적으로, 반월상 연골의 경계 모호성, 인접 조직과의 신호 강도 유사성, 내부 신호 강도 불균일성 등 영상적 특징으로 인해 분할이 어려운 사례(challenging case)를 별도로 선정하여 분석하였다.
Table 1은 반월상 연골 분할 성능의 평가 결과를 보여준다. 전체 데이터에서 제안 방법의 F1-score와 정밀도가 비교 방법에 비해 각각 1.5%p, 4.3%p 상승하여 기존 방법 대비 분할 성능이 향상되었다. 비교 방법은 재현율은 다소 높으나 정밀도가 상대적으로 낮아 과대 분할이 발생하는 경향이 있었던 반면, 제안 방법은 영상–마스크 간의 관계를 학습함으로써 형태적 특성이 잘 반영되어 과대 분할을 줄이고 정밀도를 개선하였다. 분할이 어려운 사례를 분석한 결과, F1-score와 정밀도가 각각 1.26%p, 4.37%p 향상되었다. 이는 제안 방법이 특정 조건에서만 성능이 개선되는 것이 아니라, 실제 임상적으로 난이도가 높은 경우에도 안정적인 개선 효과를 제공함을 보여준다.
| Overall | Challenging cases | |||||
|---|---|---|---|---|---|---|
| F1-score | Recall | Precision | F1-score | Recall | Precision | |
| SegDiff[12] | 86.75±1.98 | 91.50±3.34 | 82.78±4.78 | 84.37±1.69 | 90.33±4.72 | 79.71±5.73 |
| Joint CondDiff (Ours) | 88.26±2.00 | 89.92±4.55 | 87.11±5.02 | 85.63±1.40 | 88.17±5.60 | 84.08±6.74 |
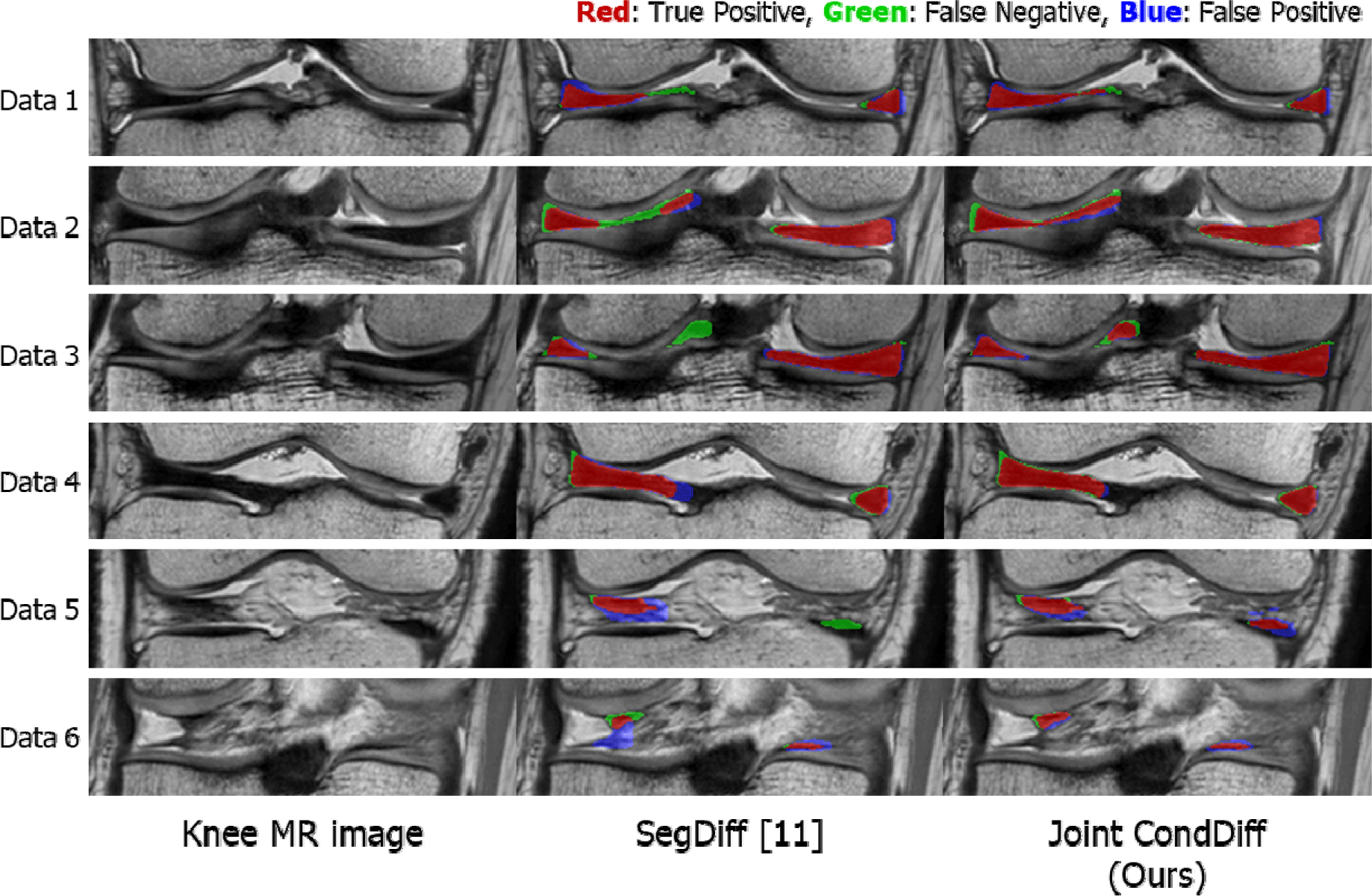
Figure 3은 반월상 분할의 정성적 평가 결과이다. 비교 방법의 경우, 구조적으로 얇거나 반월상 연골이 분리되어 나오는 슬라이스의(Data 1-3) 경우 과소 분할이 발생하였으며, 인대 및 주변 유사 신호 강도 영역으로 과대 분할이 발생하였다(Data 4). 또한 전각 및 후각 슬라이스(Data 5-6)에서 경계가 모호하여 주변 영역으로 과대 분할이 발생하거나 아예 분할이 되지 않는 경우도 발생하였다. 반면, 제안 방법은 영상의 해부학적 구조를 참고하여 영상과 마스크를 함께 생성하도록 학습되기 때문에 분할 결과가 다른 위치로의 과대 분할 및 과소 분할이 방지됨을 보였다. 추가적으로 분할이 어려운 사례에 대해서 모호한 경계 영역 및 불균일한 신호강도로 인해 과소 및 과대 분할이 발생하여 모델의 분할 성능이 저하되는 데이터에 대해서도 분할 성능이 개선됨을 확인하였다.
4. 결론
본 논문에서는 무릎 MR 영상에서 반월상 연골 분할의 정확성과 안정성을 향상시키기 위해 Joint CondDiff를 제안하였다. 제안 방법은 기존 조건부 확산 모델의 구조적 한계를 해결하기 위해, 영상-마스크 공동 노이즈화 학습 구조와 단계별 영상 주입 기반 샘플링 전략을 도입하였다. 이를 통해 영상과 마스크 간의 공간적 상관관계를 직접 학습하고, 역확산 과정에서 원본 영상의 구조 정보를 지속적으로 반영함으로써 안정적인 복원이 가능하도록 설계하였다. 실험 결과, 제안 방법은 비교 방법 대비 정밀도와 F1-score에서 유의미한 향상을 보였으며, 특히 분할이 어려운 사례에서도 개선 효과를 유지함을 알 수 있었다. 또한 정성적 결과를 통해 제안 방법이 경계가 모호한 전각 및 후각 슬라이스에서도 과대∙과소 분할을 효과적으로 완화하고, 복잡한 해부학적 구조를 안정적으로 분할할 수 있음을 알 수 있었다. 본 연구에서는 조건부 확산 기반 분할 모델의 구조적 특성을 분석하는 데 초점을 두고, SegDiff를 비교 방법으로 사용하였으며, 공동 노이즈화 학습과 단계별 영상 주입의 개별 효과에 대한 추가적인 분석 및 다른 분할 계열과의 비교는 향후 연구에서 함께 고려할 예정이다. 향후 연구에서는 영상 기반 분할만으로는 개인별 해부학적 변이를 충분히 반영하기 어렵다는 한계점을 보완하기 위해, 환자의 해부학적 정보를 텍스트 임베딩(text embedding) 형태로 모델에 통합하여, 영상 뿐 아니라 환자의 특징을 함께 반영하는 맞춤형 분할 및 형태 예측을 수행함으로써 정밀도를 높이고자 한다.


