





1 Introduction
Recent progress in generative artificial intelligence has rapidly improved the ability to create images, videos, and 3D assets directly from text prompts. In particular, text-to-3D studies such as DreamFusion, Magic3D, Fantasia3D, and SJC have significantly expanded the feasibility of prompt-driven 3D content creation by combining pretrained 2D diffusion models with differentiable rendering [1, 2, 3, 4]. Along with this trend, there is a growing demand for digital avatars that can not only be automatically created but also naturally animated for speech. Digital avatars are becoming key media interfaces in metaverse platforms, virtual customer service, educational tutoring systems, public guidance services, and character-driven media production [5, 6, 7]. Beyond static character design, practical applications increasingly require systems that can generate an avatar according to a user-specified text prompt and then animate it from arbitrary speech signals in real time or near real time [8, 9, 10].
However, most existing talking-face generation methods impose strong constraints on input conditions. Early landmark- or keypoint-based approaches [11, 12] and later methods such as MakeItTalk, Audio2Head, one-shot correlation learning, and SadTalker [5, 13, 14, 8] typically take a reference image and audio as input to synthesize a talking face video. While these approaches can generate high-quality animated frames with relatively simple inputs, they do not allow users to freely design a new identity, and their output quality is strongly affected by the quality and pose of the reference image. In contrast, text-to-3D methods can generate diverse appearances from prompts, but most of them focus on static 3D asset creation and do not directly address speech animation, facial dynamics, or temporal consistency across frames.
This gap becomes immediately apparent in realistic use scenarios where one wants to “design the appearance from text and animate it from speech.” For example, a virtual customer service avatar should be created without requiring a portrait image while still reflecting a desired style, age, or overall visual tone. It should then speak naturally in multiple languages, including Korean, English, Chinese, and Japanese, while preserving consistent identity across the entire animation sequence. In addition, frame flickering, lip mismatch, and unstable facial dynamics must be minimized. These requirements indicate the need to combine 3D morphable face models [15] with 3D-aware rendering and talking head synthesis methods [7, 16, 17].
To address these issues, this paper presents PortraitTalker, a framework for 3D talking head generation from text prompts and speech input only. The key idea is to unify three components within a single pipeline. First, an SDS-based text-to-3D synthesis module creates a photorealistic appearance and texture without requiring any reference image. Second, a transformer-based speech encoder predicts frame-wise FLAME expression and pose parameters for speech-driven animation. Third, a differentiable renderer combines the generated 3D appearance with the time-varying facial parameters to produce temporally coherent videos.
PortraitTalker shows strong quantitative performance on the HDTF dataset and maintains consistent quality across a variety of languages, ages, and regional appearance conditions. The main strength of the work lies in integrating text-based avatar design and speech-driven facial animation into a coherent framework while also reporting both objective metrics and user preference studies. At the same time, computational efficiency, broader comparison with more recent baselines, and stronger support for real-time claims remain important directions for further improvement.
The main contributions of this paper are summarized as follows.
-
We present an integrated framework for generating 3D talking avatars from text and speech without requiring reference images or manual rigging.
-
We organize the pipeline around SDS-based 3D appearance synthesis, transformer-based FLAME parameter prediction, and differentiable rendering, and analyze the role of each component.
-
We report quantitative and user-study results on HDTF, showing strong performance in lip synchronization, visual quality, and perceptual naturalness.
2 Related Work
Research on text-conditioned 3D generation has grown rapidly with the development of diffusion priors and score distillation optimization. DreamFusion established a representative starting point by showing that the score of a pretrained text-to-image model can guide 3D optimization without paired 3D supervision [1]. Magic3D improved visual fidelity and efficiency through high-resolution supervision and a two-stage mesh optimization process [2]. Fantasia3D further improved geometric detail by disentangling geometry and appearance [3], while SJC interpreted 3D generation as lifting pretrained 2D diffusion models through Jacobian chaining [4]. For portrait-specific generation, Portrait3D introduced identity-aware supervision to improve 3D head quality and identity preservation [18]. Despite these advances, the primary goal of these methods is static 3D content creation rather than temporally coherent speech animation.
PortraitTalker is meaningful in that it connects this line of text-driven 3D generation to the problem of talking head animation. In this setting, text determines identity, age, style, clothing, and lighting mood, while the speech-driven module adds dynamic facial motion on top of the same underlying 3D identity. This design separates character creation from animation while still functioning as a unified end-to-end pipeline from the perspective of the final output video.
Speech-driven talking head generation aims to synthesize facial expressions, lip motion, and head pose that are consistent with input audio. Early methods often relied on intermediate 2D representations such as landmarks, dynamic pixel-wise constraints, or keypoint motion [11, 12]. Later work such as MakeItTalk, Neural Voice Puppetry, Audio2Head, one-shot talking face generation, and SadTalker improved the quality of single-image talking face animation [5, 19, 13, 14, 8]. These methods can generate natural speech animation with limited input, but they are fundamentally based on transforming a given face image rather than creating a new identity from scratch.
Moreover, 2D-based generation often produces strong frame-level visual quality while remaining limited in free-view consistency and 3D structural stability. To address this issue, researchers have explored 3D morphable face models such as FLAME [15], free-view talking head synthesis [7], depth-aware generation [16], NeRF-based talking head models such as AD-NeRF [17], and real-time photorealistic portrait animation [6]. PortraitTalker adopts this general direction by using a speech encoder that directly predicts FLAME-compatible parameters, thereby establishing a more explicit connection between audio dynamics and facial control space.
High-quality digital human generation also depends critically on the rendering stage that integrates geometry and texture. Neural rendering and differentiable rendering make it possible to jointly optimize geometry and appearance from observations or latent representations. In addition, explicit 3D representations such as NeRF, tri-plane structures, and 3D Gaussian splatting provide practical trade-offs between rendering speed and visual fidelity [17, 9, 10]. PortraitTalker uses orthogonal feature planes or a tri-grid representation to maintain an animation-ready appearance representation, which is then combined with FLAME-based geometry and rendered into the final video.
Overall, prior work has shown major progress in both text-driven appearance generation and speech-driven animation, but relatively few studies tightly integrate the two while remaining free from reference images. More recent Gaussian talking head methods [9, 10] suggest promising directions for fast rendering, yet they are still not directly centered on text-conditioned identity generation. PortraitTalker addresses this missing connection.
3 Method
PortraitTalker can be understood as a three-stage pipeline, as shown in Fig. 1. First, a 3D appearance representation is generated from a text prompt describing the face and upper body of a desired person. Second, the input speech is analyzed over time to estimate frame-wise facial expressions and head pose. Third, the appearance representation and motion parameters are integrated through rendering to produce the final talking head video.
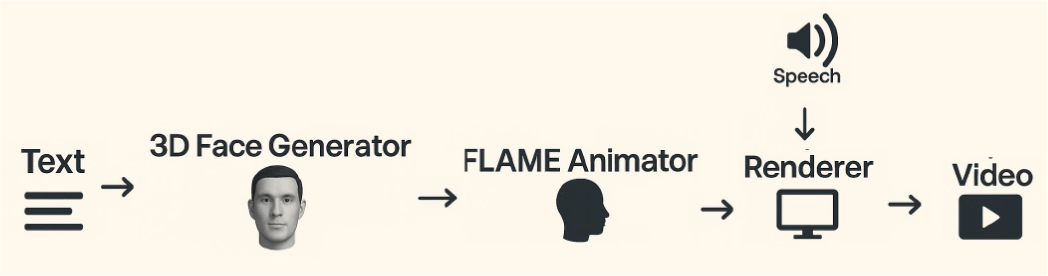
This architecture establishes a clear division of labor: text specifies who should be created, while speech determines how the generated character should speak. As a result, the same audio can be applied to different identities, and the same identity can be reused for multiple utterances or languages. Qualitative results indicate that the framework maintains identity consistency while generating speech animation for Korean, English, Chinese, and Japanese audio.
The first module addresses the core challenge of generating a diverse, high-fidelity 3D avatar from a free-form text description without any reference image. To achieve this, PortraitTalker uses diffusion optimization based on score distillation sampling. In general, SDS transfers the visual knowledge of a pretrained text-to-image diffusion model into 3D optimization, encouraging rendered views of the current 3D representation to align with the prompt. This general strategy has been widely used in DreamFusion, Magic3D, and Fantasia3D [1, 2, 3].
Conceptually, the text-to-3D optimization can be expressed as
where LSDS encourages prompt-consistent renderings and Lreg represents regularization terms that stabilize geometry and texture. Since the focus here is on the overall modeling framework, the objective is described at a conceptual level rather than through exhaustive implementation-specific hyperparameters.
PortraitTalker uses an animation-ready representation based on orthogonal feature planes or tri-grid structures. Such a representation stores appearance and geometry information compactly while allowing efficient access during the downstream animation stage. For example, a prompt such as “upper body photo, 25 y.o man in casual clothes, night, city street, soft lighting, high quality, film grain” can be translated into a coherent face and upper-body appearance with appropriate age, clothing, scene mood, and lighting style.
The second module addresses the challenge of capturing the fine-grained, temporally extended dynamics needed to drive a 3D face from speech. To model the nonlinear mapping between audio signals and realistic facial motion, PortraitTalker uses a transformer-based audio encoder to regress FLAME-based expression and pose parameters directly. This design is consistent with recent speech-driven animation approaches such as SadTalker, Neural Voice Puppetry, and Audio2Head, which also model the nonlinear mapping between audio and facial motion using temporally aware networks [8, 19, 13].
Given an input audio sequence a1:T, the model predicts FLAME parameters yt at each time step:
where yt may contain expression coefficients, jaw motion, and head pose. A FLAME-compatible control space makes it easier to interpret and manipulate lip, jaw, cheek, and eye-region motion than purely image-based warping, which in turn improves temporal stability.
Lip synchronization is not only a matter of matching mouth opening timings. It also requires phoneme-level mouth shapes, smooth transitions, and plausible global facial dynamics. Therefore, the audio encoder must capture both local acoustic cues and longer temporal context. A transformer architecture is well suited to this requirement through self-attention, and it is potentially more robust to multilingual speech, prosodic variation, and differences in speaking style.
The third module combines the text-generated appearance with the speech-predicted dynamic facial parameters to render the final video. A differentiable renderer combines FLAME-based geometry with hierarchical tri-grid textures. The goal is not simply to render each frame independently, but to preserve a coherent identity throughout the sequence while preventing instability in lighting, texture, and facial outline. This viewpoint is closely related to 3D-aware and explicit 3D talking head methods such as AD-NeRF, face-vid2vid, GaussianTalker, and MGGTalk [17, 7, 9, 10].
The final frame It can be written conceptually as
where M denotes the text-generated 3D appearance representation, yt is the FLAME parameter vector at time t, and Θ represents camera and rendering settings. A differentiable renderer provides a practical mechanism for maintaining visual realism together with temporal coherence during synthesis.
An important design choice of PortraitTalker is that it separates new identity creation from speech animation while still optimizing for the quality of the final video output. Traditional reference-image-based approaches limit the freedom of identity creation [5, 8, 14], whereas text-to-3D methods alone do not solve the animation problem [1, 2, 18]. PortraitTalker provides a practical middle ground between these two extremes.
4 Experimental Setup
Experiments are conducted on the HDTF dataset. HDTF is a high-resolution audio-visual benchmark widely used for evaluating lip synchronization, temporal consistency, and perceptual quality in talking face generation [20]. Since PortraitTalker introduces a new task setting where both identity creation and animation are performed without any reference image, no existing method is directly comparable out of the box. To establish a fair and meaningful baseline, we construct a cascaded pipeline for each reference-based prior method: we first generate a reference portrait image from the same text prompt using a pretrained text-to-image model, and then feed this synthetic image together with the speech input into MakeItTalk [5] and the method of Wang et al. [14]. This adaptation allows both baselines to operate under the same input conditions as PortraitTalker. More importantly, this cascaded setup exposes the structural weakness of delegating identity creation to a 2D image: any imperfection in the generated portrait, such as missing 3D cues, unstable identity, or limited pose coverage, propagates directly into the subsequent animation stage. PortraitTalker, by contrast, circumvents these issues by operating on an explicit 3D representation from the start.
The qualitative results further cover a range of prompt conditions involving language, region, and age. The examples include Korean news speech, a young European male, an Asian male, a muscular adult male, a child, a middle-aged man, and an elderly woman. These examples suggest that the method is not restricted to a narrow identity distribution and can support a broad design space.
Objective evaluation uses metrics related to lip synchronization and visual quality. The key metrics reported in the paper are as follows.
-
LSE-C: Lip Sync Error Confidence, where higher values indicate better synchronization confidence.
-
LSE-D: Lip Sync Error Distance, where lower values indicate better alignment between speech and mouth motion.
-
FID: Fre´chet Inception Distance, where lower values indicate better visual realism.
The user study was conducted with 20 participants. A total of 50 video clips were generated, covering samples from PortraitTalker, MakeItTalk, and Wang et al. across diverse prompts and speech inputs. Each participant watched the videos in a randomized order and was asked to rate each clip on a five-point Likert scale for four perceptual criteria: lip-sync accuracy, motion diversity, video sharpness, and overall naturalness. Table 2 reports the percentage of responses in which each method received the highest rating. This multidimensional protocol complements objective metrics by capturing perceptual quality that may not be fully reflected by a single numerical score.
5 Results
This section reports the performance of PortraitTalker from both quantitative and qualitative perspectives. We first compare the proposed method with prior talking-head baselines using objective synchronization and visual-quality metrics on the HDTF dataset [20]. We then analyze user preference results and representative visual examples to examine whether the proposed text-to-3D and speech-driven animation framework produces perceptually convincing and diverse talking portraits.
Table 1 summarizes the quantitative results. PortraitTalker achieves an LSE-C of 7.230, an LSE-D of 7.712, and an FID of 21.997 on HDTF. Compared against the adapted cascaded pipelines, The LSE-C score improves by about 43.2% over MakeItTalk [5], which reports 5.051, and by about 48.4% over the Wang et al. baseline [14], which reports 4.872. The LSE-D score is reduced from 9.999 and 9.995 to 7.712, indicating more accurate alignment between audio and lip motion. In terms of visual quality, PortraitTalker also outperforms the baselines in FID, improving from 28.183 and 22.372 to 21.997.
| Method | LSE-C↑ | LSE-D↓ | FID↓ |
|---|---|---|---|
| MakeItTalk [5] | 5.051 | 9.999 | 28.183 |
| Wang et al. [14] | 4.872 | 9.995 | 22.372 |
| PortraitTalker (Ours) | 7.230 | 7.712 | 21.997 |
These results suggest that the proposed method does not merely generate visually plausible faces, but more accurately synchronizes facial motion with the speech signal. The fact that both LSE-C and LSE-D improve simultaneously indicates that the method achieves a balanced improvement in both temporal alignment and motion quality rather than optimizing only a single aspect of synchronization. The reported FID of 21.997 further indicates strong visual quality.
Table 2 summarizes the user study results based on 20 participants and 50 samples. PortraitTalker achieves preference scores of 68.13% for lip-sync accuracy, 76.89% for motion diversity, 74.06% for video sharpness, and 74.76% for overall naturalness. MakeItTalk and Wang et al. receive substantially lower preference ratios across all four criteria. These outcomes indicate that the generated videos are not only quantitatively strong but also perceptually convincing to human observers.
| Criterion | MakeItTalk [5] | (%) Wang et al. [14] | (%) Ours (%) |
|---|---|---|---|
| Lip-sync accuracy | 9.86 | 22.01 | 68.13 |
| Motion diversity | 7.04 | 16.07 | 76.89 |
| Video sharpness | 6.72 | 19.22 | 74.06 |
| Overall naturalness | 9.41 | 15.83 | 74.76 |
The particularly strong results in motion diversity and overall naturalness suggest that the combination of FLAME-based animation and 3D rendering contributes benefits beyond lip synchronization alone. Human viewers judge the overall realism of the entire face, including expression transitions, subtle motion, and consistency across frames, so these preference gains support the structural effectiveness of the proposed design.
Figure 2 shows a representative end-to-end result. In this example, the input prompt is “close upper body photo, 25 y.o. man in casual clothes, night, city street, soft lighting, high quality, film grain,” and the driving audio corresponds to Korean news speech. The generated example illustrates the full progression from text input to 3D identity creation and finally to speech-driven animation. The result indicates that PortraitTalker can synthesize a plausible portrait identity from text alone and animate it with temporally coherent facial motion. We refer the reader to the accompanying video for full animation results.

Qualitative results highlight three main perspectives. The first is language diversity. PortraitTalker is shown to generate speech animation for Korean, English, Chinese, and Japanese while pre-serving the same avatar identity. This suggests that the audio encoder generalizes beyond a single language and can exploit speech rhythm and acoustic structure in a language-agnostic manner.
The second perspective is diversity in regional appearance and visual attributes. The examples include an Asian male, a young woman, a muscular man, and a blue-haired woman. As illustrated in Fig. 3, these diverse prompts demonstrate that the text-to-3D stage is not limited to a narrow facial distribution and can cover a broader identity and style space.

The third perspective is age variation. The examples include a young adult, a child, a middle-aged man, and an elderly subject. These results imply that attributes such as facial contour, skin texture, and wrinkles can be incorporated into the generated identity. Figure 4 shows representative outputs across age groups. This is important in practical applications where avatar design often needs to reflect a target age group.

The diversity results also imply that the open-ended prompt expressiveness demonstrated by text-to-3D studies after DreamFusion [1, 2, 3] can be effectively transferred to the domain of speech-animated portrait generation.
6 Discussion
PortraitTalker differs from prior talking face methods in two fundamental respects: it eliminates the need for a reference image, and it unifies text-driven identity creation with speech-driven animation in a 3D-aware pipeline. The relaxation of input constraints makes the method applicable to large-scale avatar creation scenarios. For example, an educational platform could quickly produce virtual tutors with different ages or visual styles, and an enterprise could rapidly prototype digital service agents aligned with brand identity. The use of FLAME-compatible parameters as the motion representation further ensures that facial dynamics remain inter-pretable and stable across frames, reducing identity drift without requiring manual rigging. These design choices separate our work from image-conditioned animation pipelines [5, 14, 8] while also extending text-to-3D generation [1, 2, 3] toward dynamic, speech-driven scenarios. The ability to create a new identity from text while preserving temporally stable speech animation is a central distinction of PortraitTalker.
Despite these advantages, several aspects of PortraitTalker warrant further investigation. First, the current quantitative comparison relies on adapted reference-based baselines rather than native text- and-speech-driven methods because no such methods exist in the published literature. As the field evolves, comparisons with future text-to-talking-head methods will be necessary to contextualize our performance more precisely.
Second, the computational cost of the text-to-3D stage remains significant. As commonly observed in SDS-based pipelines, the per-identity optimization requires dozens of minutes on a highend GPU, making real-time interactive avatar creation currently infeasible without further acceleration. Profiling and optimizing this stage, potentially through amortized inference networks or Gaussian-based representations, is an important direction for practical deployment.
Third, the absence of component-wise ablation studies limits our ability to attribute gains to specific design choices. While the end-to-end results are encouraging, future work should systematically evaluate the contribution of the SDS module, the transformer audio encoder, and the differentiable renderer, for instance by replacing the transformer with an LSTM-based encoder or by freezing the 3D appearance to a fixed template.
Additional extensions include expanding the framework to full-body avatars with hand gestures, conducting systematic multilingual evaluations, and targeting lightweight deployment for mobile or edge devices. We believe these directions will build on the foundation established here and further bridge the gap between text-driven character design and speech animation.
7 Conclusion
This paper presents PortraitTalker, a framework for generating photorealistic 3D talking heads directly from text prompts and speech. The method is organized around SDS-based text-to-3D appearance synthesis, transformer-based FLAME parameter prediction, and differentiable rendering. This design alleviates the main limitation of reference-image-dependent talking face generation and offers a practical route toward scalable avatar production.
The reported experiments show strong lip synchronization and visual quality on the HDTF dataset [20], and the user study further supports the perceptual quality of the generated videos. These observations suggest that combining text-driven avatar creation with speech-driven animation is a promising direction for digital human generation. Future work should extend the system to full-body avatars, conduct systematic multilingual evaluations, profile and accelerate the text-to-3D stage for practical deployment, and validate design choices through component-wise ablation studies.

