





1 Introduction
Estimating depth from a single image has been extensively studied due to its applicability to higher-level visual processing, such as generating 3D geometry [1], 3D rendering with object compositing [2], creating panoramas in other viewpoints [3], and scene understanding [4]. However, the majority of efforts on depth prediction has been focused on normal field-of-view (FoV) images, and depth estimation from 360° panorama images has been paid less attention despite the increasing popularity of 360° cameras.
For depth estimation from 360° panorama images, traditional approaches [5, 3] mostly use more than one panorama images, and rely on structure-from-motion (SfM) [6] and bundle adjustment with the plane sweeping algorithm [7]. With the recent advent of deep learning, single 360° panorama image-based depth estimation techniques have been introduced. Zioulis et al. [8] propose a supervised learning-based approach, in which they implement rectangular convolution filters for the robustness to geometric distortions in panorama images. Eder et al. [9] use two supervised decoders, one of which estimates a depth map, while the other predicts normal and boundary maps. Eder et al. [10] introduce deformed convolution kernels that dynamically change their shapes depending on the locations to effectively handle geometric distortions in panorama images. Zioulis et al. [11] introduce a self-supervised method to deal with error in training data. Thanks to the capability of deep learning, these methods can produce a plausible depth map even from a single image.
However, previous deep learning-based methods [8, 9, 10, 11] heavily rely on synthetic datasets as acquisition of real panorama images and depth maps is difficult. The most popular datasets for panorama image depth estimation include the SUMO [12] and 360D [8] datasets. The SUMO dataset consists of panorama images rendered from computer-generated 3D models, and their corresponding ground truth depth maps. The 360D dataset also consists of panorama images rendered from 3D models, and their corresponding depth maps. The 3D models used in the 360D datasets are either computer-generated or obtained by 3D scanning of real indoor environments.
Unfortunately, the synthetic nature of both datasets has fundamental limitations. While computer-generated 3D models may provide highly accurate depth information, panorama images rendered from them are often unrealistic and have different characteristics from real panorama images. On the other hand, 3D scanning may provide more realistic-looking panorama images, but suffer from 3D reconstruction errors, which lead to artifacts in panorama images and depth maps. Such unnatural characteristics of previous datasets introduce domain difference [13] between synthesized and real panorama images, which hinders the performance of learning-based depth estimation approaches. Fig. 1 shows the visual difference of synthetic and real panorama images.

In this paper, we propose a novel deep learning-based approach that estimates a depth map from a single 360° panorama image. In our approach, we use the 360D dataset [8] to train a convolutional neural network to predict a depth map from a single panorama image. However, to address the domain difference between synthesized and real images, we introduce domain adaptation into our framework. Specifically, for training the network, we utilize an additional dataset, SUN360 [14], which provides real 360° panorama images without ground truth depth maps. We also adopt an adversarial loss to learn features shared by synthetic and real panorama images so that the network can predict accurate depth maps from real panorama images even if it is trained on synthetic datasets. Additionally, we introduce a surface normal loss to suppress noise in predicted depth maps. Experimental results show that our approach outperforms previous approaches both on synthetic and real panorama images.
2 Our Approach
In this section, we describe the network architecture of our frame-work for depth map estimation from a single 360° panorama image, and how to train the network addressing the domain difference between synthetic and real data.
Our framework is built on top of Zioulis et al.’s framework [8], which is the state-of-the-art approach to depth estimation from a single panorama image. Fig. 2 shows our network architecture. Specifically, for our depth estimation network, we adopt the Rect-Net architecture [8], which is an encoder-decoder architecture. The network takes a single 360° panorama image obtained with equirectangular projection as input, and predicts its depth map. The network uses horizontally wide rectangular convolution filters of various sizes to deal with distortions of equirectangular projection. It also adopts dilated convolution to increase the size of receptive fields.
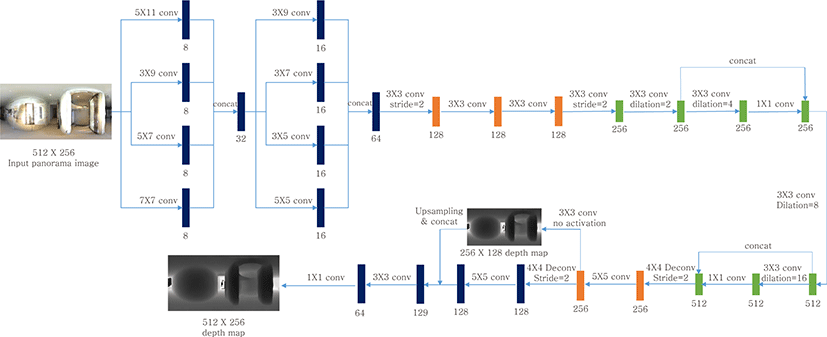
To train the depth estimation network, we utilize two different datasets: 360D [8] and SUN360 [14], each of which serves learning accurate depth estimation and domain adaptation, respectively. The 360D dataset provides 34,679 pairs of a synthetic panorama image and its ground truth depth map for training, and 1,298 pairs for testing. The SUN360 dataset provides real panorama images collected from the Internet without ground truth depth maps. The SUN360 panorama dataset is separated into two sets: indoor and outdoor. We randomly separated the indoor panorama images of SUN360 dataset into a training set of 10,598 images and a test set of 1,179 images.
To learn depth estimation, we minimize a loss function over the training set sampled from the 360D dataset, which is defined as:
where Ldepth, Lsmooth, and Lnormal are data fidelity loss, smoothness loss, and surface normal loss, respectively. βdepth, βsmooth, and βnormal are their weights. Ldepth makes it possible to learn depth estimation, while Lsmooth encourages the depth estimation network to predict smooth depth maps. Following Zioulis et al. [8], we define Ldepth and Lsmooth as:
where XS and DGT are a synthetic panorama image and its ground truth depth map, respectively. G indicates the depth estimation network, and G(XS) is a depth map predicted from XS. M is a binary mask of valid pixels in XS, which is also provided by the 360D dataset. Me is a binary mask to exclude pixels belonging to edges in DGT as they often suffer from large errors caused by 3D scanning. The inclusion of this mask Me is our own modification that was not a part of the original Lsmooth proposed by [8]. We refer the readers to our supplementary material for the construction of Me.
Without Lsmooth, the network can still learn to predict accurate depth maps in terms of mean-squared-error (MSE), but the prediction results may suffer from high frequency noise, i.e., noisy surface normals. Lsmooth can help avoid such noise as shown in [8], but it may harm the accuracy as it simply suppresses depth map gradients as will be shown in Sec. 3. To resolve this, we propose a novel loss function Lnormal that encourages the surface normals of a predicted depth map to be similar to those of the ground truth depth map so that the predicted depth map has clean and accurate surface normals with less noise. Mathematically, we define Lnormal as:
where N is an operator that computes the surface normal map.
Training the depth estimation network using only Eq. (1) causes over-fitting to synthetic panorama images and performance degradation on real images due to the domain gap. To resolve this, we employ adversarial loss functions Ladv and LD for domain adaptation, which are defined as:
where XR is a real panorama image. D is a discriminator network that takes a depth map produced by G and discriminates whether the depth map has been estimated from a synthetic panorama image or not. With Eq. (5), to deceive D for real images, G should produce depth maps with similar characteristics to the depth maps from synthetic images. On the other hand, Eq. (6) trains D to more accurately discriminate depth maps from real and synthetic panorama images. For the discriminator network D, we employ the same architecture as the encoder part of G, but with an additional fully connected layer at the end for binary classification.
Our total loss for training the depth estimation network G is then defined as:
As constrained by both Eq. (1) and Eq. (5), G can preserve the high performance on the synthetic panorama images, while it can also produce similar quality results for real images. Consequently, our domain adaptation enables G to produce high-quality depth maps for any types of input images.
3 Results
We use Adam optimizer [20] to train the depth estimation and discriminator networks with a learning rate of 10—4. We set [α, βdepth, βsmooth, βnormal, γ]=[10—3, 1, 0.2, 0.4, 10—4], where γ is the weight for LD in Eq. (6). We first train the depth estimation network with only Ldata for 65,000 iterations with batch size 10. Then we train the pretrained depth estimation network and discriminator network with LG and LD for 21,000 iterations with batch size 5.
We conduct an ablation study to verify the effect of each component of our framework. In our ablation study, we examine three variants of our model to verify the effect of the surface normal loss and the adversarial loss. The first model is a baseline model trained with only Ldepth and Lsmooth, which is the same model proposed by Zioulis et al. [8]. The second model is trained with Ldepth, Lsmooth and Lnormal. Finally, the third model is trained with our final loss function in Eq. (7) with domain adaptation. Then, we qualitatively compare the results of the models on a real panorama image as real panorama images have no ground truth depth maps. Fig. 3 shows resulting depth maps of the three variants. In each depth map, bright pixels are far away, and dark pixels are close. As shown in Fig. 3(b), the baseline model produces noisy structures despite Lsmooth. On the other hand, Fig. 3(c) shows that Lnormal successfully suppresses noise even for the real image. However, the result still has large depth error as shown in the green box where the depth of an aisle is incorrectly estimated as very close. Finally, Fig. 3(d) shows that Ladv successfully improves the accuracy for the real image more accurately detecting the depth of the aisle.

Figs. 4 and 5 show qualitative comparisons of our method with Zioulis et al. [8] on synthetic and real panorama images, respectively. Zioulis et al. [8]‘s model is trained with 360D [8] datasets. The input images in Figs. 4 and 5 are from the 360D and SUN360 datasets, respectively, and they are not used for training. For synthetic panorama images, both Zioulis et al.’s method and ours show reasonable results while our results are less noisy and sharper thanks to the surface normal loss. On the other hand, for real panorama images in Fig. 5, Zioulis et al.’s method produces a significant amount of errors due to the domain difference between the real and synthetic panorama images while our method still produces accurate results thanks to our domain adaptation. We refer the readers to the supplementary material for more examples.


Finally, we quantitatively compare our method with previous state-of-the-art approaches on synthetic panorama images. We compare our method with two panorama image depth estimation approaches [8, 11] and five non-panorama image depth estimation approaches [15, 16, 17, 18, 19]. Zioulis et al. [8, 11]‘s two models are trained with 360D [8] datasets and a set of rendered panorama pairs made out of [21, 22, 23], respectively. [15] is trained with outdoor scenes such as KITTI [24] dataset, and other four non-panorama image depth estimation approaches [16, 17, 18, 19] are trained with NYUD-V2 [25] dataset. For quantitative comparison, we use the test set of the 360D dataset [8]. Since the non-panorama image methods are not trained for panorama images, it is unfair to directly compare our method with them. For a fair comparison, as Zioulis et al. [8] did, we divide a 360° panorama image into multiple subimages with a standard FoV by cube map projection and estimate a depth map for each image. Then, we merge the multiple depth maps into a panorama depth map using sphere projection. We use the final depth map for measuring the performance of the non-panorama image depth estimation methods. Table 1 shows that our method outperforms both panorama and non-panorama image depth estimation methods, which indicates that our approach also improves quantitative performance on synthetic panorama images while successfully reducing the domain gap between the synthetic and real panorama images.
| Abs Rel ↓ | Sq Rel ↓ | RMS ↓ | RMSlog ↓ | δ < 1.25 ↑ | δ < 1.252 ↑ | δ < 1.253 ↑ | |
|---|---|---|---|---|---|---|---|
| Godard et al. [15] | 0.2552 | 0.9864 | 4.4524 | 0.5087 | 0.3096 | 0.5506 | 0.7202 |
| Lainaet al. [16] | 0.1423 | 0.2544 | 0.7751 | 0.2497 | 0.5198 | 0.8032 | 0.9175 |
| Liu et al. [17] | 0.1869 | 0.4076 | 0.9243 | 0.2961 | 0.424 | 0.7148 | 0.8705 |
| Lee et al. [18] | 0.3212 | 0.3511 | 1.0838 | 0.4109 | 0.4293 | 0.7389 | 0.8918 |
| Yan et al. [19] | 0.3841 | 0.5195 | 1.2677 | 0.4843 | 0.3406 | 0.6467 | 0.8405 |
| Zioulis et al. [8] | 0.0702 | 0.0297 | 0.2911 | 0.1017 | 0.9574 | 0.9933 | 0.9979 |
| Zioulis et al. [11] λratio = 0.6 | 0.1953 | 0.1531 | 0.6589 | 0.2614 | 0.6469 | 0.9212 | 0.9776 |
| Zioulis et al. [11] λratio = 0.8 | 0.1949 | 0.1457 | 0.6574 | 0.2591 | 0.6620 | 0.9180 | 0.9758 |
| Zioulis et al. [11] λratio = 1 | 0.1938 | 0.1444 | 0.6468 | 0.2573 | 0.6737 | 0.9159 | 0.9754 |
| Zioulis et al. [11] supervised | 0.1238 | 0.0693 | 0.4365 | 0.1723 | 0.8507 | 0.9679 | 0.9898 |
| Ours | 0.0708 | 0.0231 | 0.2498 | 0.1001 | 0.9614 | 0.9946 | 0.9982 |
4 Conclusion
In this paper, we presented a novel deep learning-based approach for depth map estimation from a single real panorama image by bridging the domain difference between real and synthetic panorama images using domain adaptation. As previous works rely on synthetic datasets, they are not guaranteed to accurately predict the depth from real panorama images. To address the lack of datasets with real panorama images for depth estimation, we introduced domain adaptation based on an adversarial loss for depth estimation from panorama images. We also proposed a surface normal loss to suppress noise in estimated depth maps. The quantitative and qualitative results demonstrate that our approach can effectively reduce the domain gap and accurately estimate the depth from synthetic panorama images.





